[네트워크] 라우터 내부 구조, 포트, 버퍼 관리, 스케쥴링 내부 동작 설명
Router Architecture Overview (라우터 아키텍처 개요)

라우터(Router)는 네트워크에서 데이터그램(datagram, 패킷)을 목적지까지 전달(forwarding)하는 장치이다. 라우터의 내부 구조는 크게 두 가지 평면(plane)으로 나뉜다.
- Control Plane(제어 평면): 소프트웨어 기반으로 동작하며, 라우팅(routing)과 관리(management)를 담당한다. 라우팅 프로토콜을 통해 라우팅 테이블을 계산하고, 이 결과를 데이터 평면에 전달한다. 밀리초(ms) 단위의 시간 프레임에서 동작한다.
- Data Plane(데이터 평면, Forwarding Plane): 하드웨어 기반으로 동작하며, 실제 패킷 전달(forwarding)을 수행한다. 나노초(ns) 단위의 매우 빠른 시간 프레임에서 동작한다.
라우터는 입력 포트(input port), 고속 스위칭 패브릭(high-speed switching fabric), 출력 포트(output port)로 구성된다.
라우터 내부 구조의 Analogy

라우터는 기차역(station)과 유사하다. 각 입력 포트는 입구역(entry station), 출력 포트는 출구 도로(exit road), 스위칭 패브릭은 회전 교차로(roundabout), 라우팅 프로세서는 역 관리자(station manager)에 해당한다.
- 입구역(entry station): 데이터그램이 들어오는 곳(입력 포트)
- 회전 교차로(roundabout): 데이터그램이 목적지로 가기 위해 방향을 바꾸는 곳(스위칭 패브릭)
- 역 관리자(station manager): 전체 경로와 처리를 관리(라우팅 프로세서)
- 출구 도로(exit road): 데이터그램이 나가는 곳(출력 포트)
Input Port Functions (입력 포트 기능)

입력 포트는 데이터그램이 라우터에 도착했을 때 가장 먼저 처리되는 부분이다. 주요 기능은 다음과 같다.
- Physical Layer(물리 계층): 비트 단위(bit-level)로 신호를 수신한다. 예시: Ethernet
- Link Layer(링크 계층): 프레임을 수신하고, 링크 계층 프로토콜을 처리한다.
- Lookup, Forwarding, Queueing(조회, 전달, 큐잉): 헤더 필드 값을 이용해 출력 포트를 결정하고(lookup), 전달(forwarding)하며, 큐에 저장(queueing)한다.
Decentralized Switching (분산 스위칭)
- 입력 포트에서 헤더 필드 값을 사용하여, 입력 포트 메모리에 저장된 포워딩 테이블(forwarding table)로 출력 포트를 결정한다. 이 과정을 "match plus action"이라 한다.
- 목표는 입력 포트에서 ‘라인 속도(line speed)’로 처리를 완료하는 것이다.
- 데이터그램이 스위칭 패브릭으로 전달되는 속도보다 빠르게 도착하면, 입력 포트 큐잉(input port queuing)이 발생한다.
Forwarding 방식
- Destination-based Forwarding(목적지 기반 포워딩): 전통적으로 목적지 IP 주소만을 기반으로 포워딩
- Generalized Forwarding(일반화된 포워딩): 헤더의 다양한 필드 값을 기반으로 포워딩
Destination-based Forwarding (목적지 기반 포워딩)
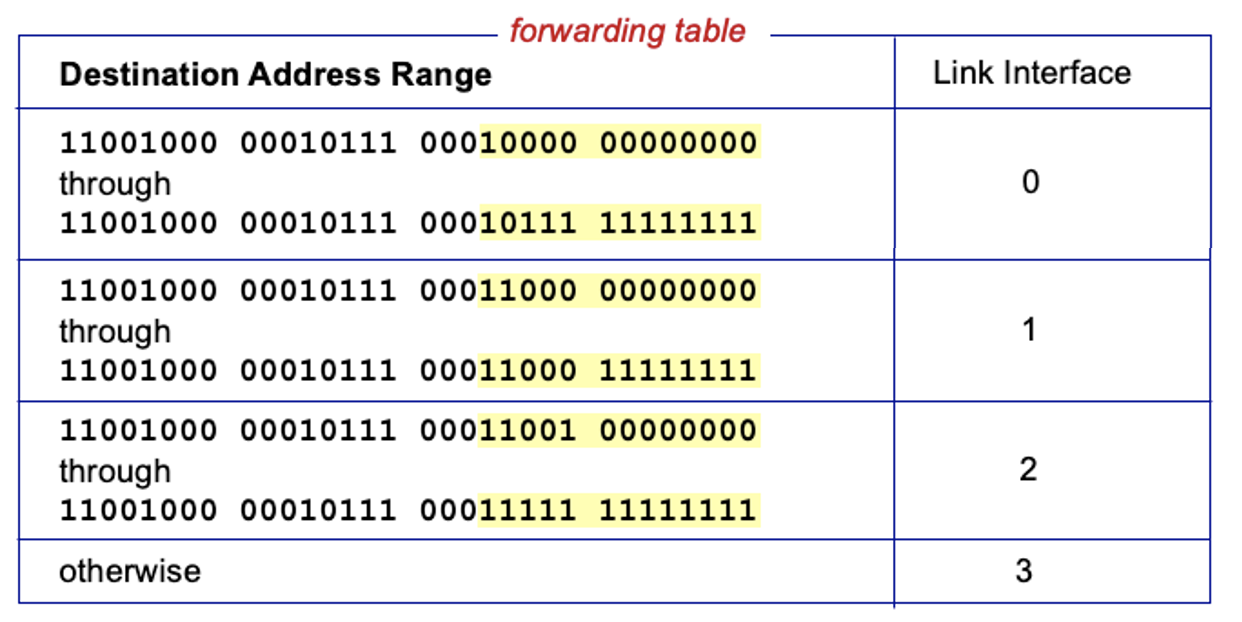
라우터(Router)는 패킷의 목적지 주소(Destination Address)를 보고, 포워딩 테이블(Forwarding Table)에 따라 어느 링크 인터페이스(Link Interface)로 패킷을 전달할지 결정한다. 포워딩 테이블에는 목적지 주소 범위(Destination Address Range)와 각 범위에 해당하는 인터페이스가 매핑되어 있다.
예시 테이블에서, 목적지 주소가 특정 비트 패턴 범위에 속하면 해당 인터페이스로 전달된다. 하지만, 주소 범위가 딱 맞게 나누어지지 않을 때가 많아, 이럴 때는 'Longest Prefix Matching(최장 접두사 일치)'가 필요하다.
Longest Prefix Matching (최장 접두사 일치)

Longest Prefix Matching은 목적지 주소와 포워딩 테이블의 주소 범위 중에서, 가장 긴(가장 많은 비트가 일치하는) 접두사(prefix)가 일치하는 엔트리를 선택하는 방식이다.
- 목적지 주소가 주어지면, 포워딩 테이블의 여러 엔트리 중에서 가장 많은 비트가 앞에서부터 일치하는(즉, 가장 긴 접두사) 엔트리를 찾아 해당 인터페이스로 포워딩한다.
TCAM (Ternary Content Addressable Memory)
Longest Prefix Matching을 빠르게 처리하기 위해, 라우터는 TCAM(Ternary Content Addressable Memory)이라는 특수 메모리를 사용한다.
- TCAM은 입력 주소와 테이블의 모든 엔트리를 동시에 비교하여, 한 번의 클럭 사이클(one clock cycle)만에 가장 긴 접두사 일치 결과를 찾아낸다.
- Cisco Catalyst 같은 장비는 약 100만 개의 라우팅 테이블 엔트리를 TCAM에 저장할 수 있다.
- TCAM의 특징: 주소를 입력하면, 일치하는 엔트리를 즉시 반환한다.
Switching Fabric(스위칭 패브릭) 개념과 내부 동작
스위칭 패브릭(Switching Fabric)은 라우터(Router) 내부에서 입력 포트(input port)로 들어온 패킷(packet, 데이터그램)을 적절한 출력 포트(output port)로 전달하는 핵심 구조이다. 스위칭 패브릭의 성능은 라우터 전체의 처리 속도와 직결된다.
Switching Rate(스위칭 속도)

- 스위칭 속도는 입력에서 출력으로 패킷을 전달할 수 있는 최대 속도를 의미한다.
- 보통 입력/출력 라인 속도의 배수로 측정한다.
- N개의 입력 포트가 있다면, 이상적으로는 N배(line rate)의 스위칭 속도가 필요하다.
스위칭 패브릭의 3가지 주요 방식

1. Switching via Memory(메모리 기반 스위칭)

동작 구조: 초기 라우터에서 사용된 방식으로, CPU(라우팅 프로세서)가 직접 제어한다.
처리 과정
- 입력 포트로 패킷이 도착하면, CPU가 인터럽트(interrupt)로 이를 감지한다.
- 패킷이 입력 포트에서 시스템 메모리(system memory)로 복사된다.
- CPU가 패킷의 헤더에서 목적지 주소를 추출하고, 포워딩 테이블(Forwarding Table)에서 출력 포트를 조회한다.
- 패킷이 메모리에서 해당 출력 포트의 버퍼로 복사된다.
특징
- 한 번에 하나의 패킷만 처리 가능(동시에 여러 패킷 불가)
- 처리 속도는 메모리 대역폭(memory bandwidth)에 의해 제한된다(패킷당 2번의 버스 접근 필요)
적용: 저속 네트워크, 1세대 라우터
2. Switching via a Bus(버스 기반 스위칭)

동작 구조: 입력 포트와 출력 포트가 공통 버스(shared bus)로 연결되어 있다.
처리 과정
- 입력 포트가 패킷에 내부 라벨(내부 헤더)을 붙여 버스로 전송한다.
- 모든 출력 포트가 패킷을 수신하지만, 라벨이 일치하는 포트만 패킷을 저장한다.
- 출력 포트에서 내부 라벨을 제거한다.
특징
- 한 번에 하나의 패킷만 버스를 통과할 수 있다(버스 경쟁, bus contention 발생)
- 스위칭 속도는 버스 대역폭(bus bandwidth)에 의해 제한
- 예시: Cisco 5600(32Gbps 버스)
적용: 중소형 라우터, 액세스 라우터
3. Switching via Interconnection Network(인터커넥션 네트워크 기반 스위칭, 크로스바 등)

인터커넥션 네트워크(Interconnection Network)는 입력 포트와 출력 포트를 다양한 방식의 스위칭 네트워크로 연결하는 구조이다. 대표적으로 크로스바(Crossbar), Clos 네트워크(Clos Network) 등이 있다. 이 방식은 원래 멀티프로세서 시스템에서 프로세서 간 연결을 위해 개발되었으나, 라우터에서도 대규모 패킷 스위칭을 위해 사용된다.
멀티스테이지 스위치(Multistage Switch)
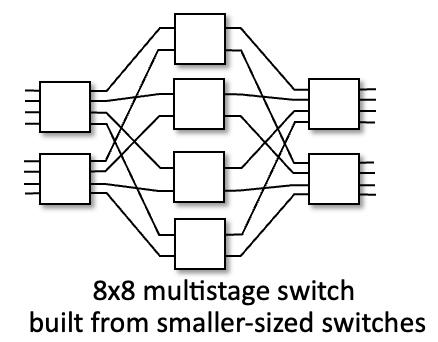
- nxn 스위치를 여러 단계(stage)의 소형 스위치로 구성한다.
- 예시: 8x8 스위치는 여러 개의 작은 스위치를 계층적으로 연결하여 구현한다.
- 오른쪽 그림 참고(3x3 크로스바, 8x8 멀티스테이지 스위치)
병렬성 활용(Exploiting Parallelism)
- 입력 시 데이터그램(datagram)을 고정 길이 셀(fixed-length cell)로 분할(fragmentation)한다.
- 각 셀(cell)을 패브릭 내부에서 병렬로 전송한다.
- 출력 포트에서 셀을 재조립(reassembly)하여 원래의 데이터그램으로 복원한다.
- 이 과정을 통해 여러 패킷이 동시에 서로 다른 경로로 전달될 수 있다.
스케일링과 패브릭 플레인(Fabric Plane)

- 대형 라우터에서는 여러 개의 스위칭 플레인(switching plane, 패브릭 플레인)을 병렬로 사용한다.
- 각 플레인은 독립적으로 동작하며, 병렬성을 통해 처리량(switching capacity)을 대폭 향상시킨다.
- 예시: Cisco CRS 라우터는 8개의 패브릭 플레인을 사용하고, 각 플레인은 3단계 인터커넥션 네트워크(3-stage interconnection network)로 구성된다.
- 이러한 구조는 수백 Tbps(terabits per second) 이상의 스위칭 용량을 제공할 수 있다.
Input Port Queuing(입력 포트 큐잉) 내부 동작

스위칭 패브릭(switch fabric)의 처리 속도가 여러 입력 포트(input port)들의 합보다 느릴 경우, 입력 포트에서 큐잉(queueing)이 발생한다. 이때 주요 현상과 동작은 다음과 같다.
- 입력 포트의 버퍼(buffer)에 데이터그램(datagram)이 쌓이게 되며, 이로 인해 큐잉 지연(queueing delay)과 버퍼 오버플로우(buffer overflow)로 인한 패킷 손실(loss)이 발생할 수 있다.
- Head-of-the-Line(HOL) Blocking: 입력 큐의 맨 앞에 있는 데이터그램이 특정 출력 포트(output port)로만 나갈 수 있는데, 해당 출력 포트가 이미 다른 입력 포트의 데이터그램으로 점유되어 있다면, 맨 앞 데이터그램이 블록(block)되어 큐 뒤에 있는 다른 데이터그램들도 함께 지연된다. 이로 인해 전체 처리 효율이 저하된다.
- 예시 그림에서, 두 입력 포트에서 동시에 같은 출력 포트로 데이터그램을 보내려고 하면, 한 개만 전달되고 나머지는 대기하거나 블록된다.
Output Port Queuing(출력 포트 큐잉) 내부 동작

스위칭 패브릭을 통과한 데이터그램이 출력 포트로 도착할 때, 출력 포트의 전송 속도(line speed)보다 도착 속도가 빠르면 출력 포트에서도 큐잉이 발생한다.
- 출력 포트에는 데이터그램 버퍼(datagram buffer)가 존재하며, 패킷이 도착할 때마다 큐에 저장된다.
- 큐가 가득 차면(drop policy 적용), 어떤 데이터그램을 버릴지 결정해야 한다. 이 정책에 따라 일부 패킷은 손실될 수 있다.
- Scheduling discipline(스케줄링 규율)에 따라, 큐에 쌓인 데이터그램 중 어떤 것을 먼저 전송할지 결정한다. 예를 들어, 우선순위(priority scheduling)를 적용하면 특정 트래픽이 더 빠르게 전송될 수 있다.
- 혼잡(congestion)이나 버퍼 부족(buffer overflow)으로 인해 데이터그램이 손실될 수 있다.

- 입력 포트 큐잉: 스위칭 패브릭 진입 전, 입력 버퍼에서 발생. HOL blocking 등으로 인한 지연과 손실이 문제.
- 출력 포트 큐잉: 스위칭 패브릭을 통과한 후, 출력 버퍼에서 발생. 도착 속도가 전송 속도를 초과할 때 큐잉 및 손실 발생.
- 두 경우 모두, 큐잉 지연(delay)과 버퍼 오버플로우로 인한 패킷 손실(loss)이 네트워크 성능 저하의 주요 원인이다.
- 스케줄링과 드롭 정책(drop policy)에 따라 성능과 네트워크 공정성(network neutrality)이 달라질 수 있다.
버퍼(Buffer) 크기와 관리의 내부 동작
버퍼 크기 결정 원리

- 기본 원칙: RFC 3439에 따르면, 라우터의 평균 버퍼 크기는 "평균 RTT(Round Trip Time)"에 링크 용량(Capacity, C)을 곱한 값으로 잡는다. 예를 들어, RTT가 250ms이고 링크 용량이 10Gbps라면, 적정 버퍼 크기는 2.5Gbit이다.
- 동시 플로우 고려: 최근에는 N개의 플로우(flow)가 동시에 지나갈 때, 적정 버퍼 크기를 위 공식으로 권장한다. 즉, 플로우가 많아질수록 각 플로우가 차지하는 버퍼 공간은 줄어든다.
- 과도한 버퍼 문제: 버퍼가 너무 크면 지연(delay)이 늘어나고, 특히 가정용 라우터에서 실시간 애플리케이션 성능 저하와 TCP 반응성 저하가 발생한다. 따라서 "병목 링크를 충분히 채우되 더 이상은 채우지 않는다"는 지연 기반 혼잡 제어 원칙이 중요하다.
Buffer Management(버퍼 관리) 내부 동작

- 버퍼 구조: 스위칭 패브릭(switch fabric)에서 나온 데이터그램은 버퍼(datagram buffer)에 저장되고, 큐잉 스케줄링(queueing scheduling)을 거쳐 링크 계층(link layer protocol)으로 전송된다. 최종적으로 라인 종단(line termination)에서 실제 전송이 이루어진다.
- 큐(queue) 추상화: 패킷이 도착하면 큐(대기 공간)에 쌓이고, 링크(서버)에서 하나씩 꺼내 전송된다.
- 드롭 정책(drop policy): 버퍼가 가득 찼을 때 어떤 패킷을 버릴지 결정한다.
- Tail Drop: 새로 도착한 패킷을 버린다.
- Priority Drop: 우선순위가 낮은 패킷부터 버린다.
- 마킹(marking): 혼잡 신호를 위해 특정 패킷에 마크를 남긴다(예: ECN, RED).
Packet Scheduling(패킷 스케줄링) 내부 동작
FCFS(First Come First Served, FIFO)

- 동작 원리: 패킷이 도착한 순서대로 큐에 저장되고, 출력 포트로 전송된다.
- 현실 예시: 은행 창구, 티켓 줄 등 실제로도 많이 쓰이는 방식
Priority Scheduling(우선순위 스케줄링)

- 분류 및 큐잉: 도착한 트래픽을 클래스별로 분류해 각 클래스별 큐에 저장한다. 헤더 필드 등 다양한 기준으로 분류 가능
- 전송 순서: 가장 높은 우선순위 큐에 패킷이 있으면 그 큐에서 먼저 전송한다. 같은 클래스 내에서는 FCFS로 처리
Round Robin Scheduling(라운드 로빈 스케줄링)
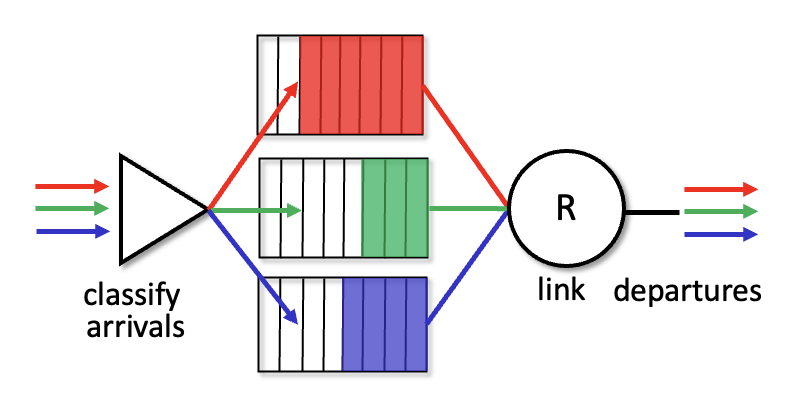
- 분류 및 큐잉: 트래픽을 클래스별로 분류해 각 클래스별 큐에 저장
- 전송 순서: 서버가 각 클래스 큐를 순환(cyclically)하며, 한 번에 하나씩 패킷을 전송
Weighted Fair Queuing(WFQ, 가중치 공정 큐잉)

- 일반화된 라운드 로빈: 각 클래스 i에 가중치 wi를 부여, 한 사이클마다 클래스별로 가중치에 비례해 서비스 제공
- 최소 대역폭 보장: 각 트래픽 클래스별로 최소 대역폭을 보장할 수 있음
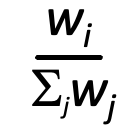
Network Neutrality(네트워크 중립성) 개념 및 내부 원리
- Network Neutrality(네트워크 중립성)이란, 인터넷 서비스 제공자(ISP, Internet Service Provider)가 모든 인터넷 트래픽을 차별 없이 동등하게 취급해야 한다는 원칙이다. 즉, ISP는 특정 콘텐츠, 웹사이트, 애플리케이션, 서비스, 장치, 송신자, 수신자, 프로토콜 등에 따라 속도, 접근성, 품질을 차별해서는 안 된다.
네트워크 중립성의 세 가지 측면
기술적(Technical): ISP가 자원(대역폭, 버퍼 등)을 어떻게 분배·할당할지에 대한 문제이다.
- 패킷 스케줄링(packet scheduling), 버퍼 관리(buffer management) 등이 실제 구현 메커니즘이다.
사회·경제적(Social, Economic):
- 자유로운 표현 보호(free speech), 혁신과 경쟁 촉진(innovation, competition) 등 사회적·경제적 가치를 지향한다.
법적(Legal):
- 각 국가별로 법적 규칙과 정책이 다르며, 법에 의해 네트워크 중립성이 강제될 수 있다.
네트워크 중립성의 핵심 원칙
- Equal Treatment of Data(데이터 동등 처리): 모든 인터넷 트래픽을 동등하게 취급해야 한다.
- No Blocking(차단 금지): 합법적인 콘텐츠, 서비스, 애플리케이션, 장치에 대한 접근을 차단해서는 안 된다.
- No Throttling(속도 저하 금지): 특정 콘텐츠, 서비스, 애플리케이션의 속도를 인위적으로 저하시켜서는 안 된다.
- No Paid Prioritization(유료 우선순위 금지): 돈을 더 내는 서비스나 콘텐츠에 대해 '패스트 레인(fast lane)'을 제공해서는 안 된다.
미국 FCC의 2015년 네트워크 중립성 규칙
2015년 미국 FCC(Federal Communications Commission)는 "Order on Protecting and Promoting an Open Internet"를 통해 세 가지 명확한 규칙을 제시했다.
- No Blocking: 합법적인 콘텐츠, 애플리케이션, 서비스, 장치에 대한 차단 금지
- No Throttling: 합법적인 인터넷 트래픽의 품질 저하나 속도 저하 금지
- No Paid Prioritization: 유료 우선순위 제공 금지
이 규칙들은 "합리적인 네트워크 관리(reasonable network management)" 범위 내에서 예외가 있을 수 있다.
네트워크 중립성의 실질적 의미
- 사용자가 어떤 웹사이트(예: Netflix, YouTube, Wikipedia 등)에 접속하든 ISP는 모두 동일한 품질과 조건으로 접속을 보장해야 한다.
- ISP가 특정 서비스(예: 스트리밍, 게임, 뉴스 등)만 빠르게 해주거나, 특정 업체와 계약을 맺고 그 업체만 우대하는 것은 네트워크 중립성 위반이다.
- 네트워크 중립성이 없으면, ISP가 트래픽을 차별적으로 관리하여 시장 경쟁과 혁신이 저해될 수 있다.
ISP: Telecommunications Service vs Information Service
미국에서는 ISP가 "Telecommunications Service(통신 서비스)"인지 "Information Service(정보 서비스)"인지의 구분이 매우 중요하다.
Telecommunications Service(통신 서비스, Title II):
- 공통 운송사업자(common carrier) 의무가 적용된다.
- 합리적인 요금, 비차별성, 규제 대상
Information Service(정보 서비스, Title I):
- 공통 운송사업자 의무 없음(비규제)
- FCC가 필요시 제한적 권한만 행사
이 구분에 따라 ISP에 대한 규제 강도가 달라진다. 예를 들어, 2015년 FCC는 ISP를 Title II(통신 서비스)로 재분류해 강력한 네트워크 중립성 규제를 적용했다.
국가별 차이
각국의 법·정책, 사회적 환경에 따라 네트워크 중립성 해석과 적용 방식이 다르다.
미국, 유럽, 인도 등 주요 국가마다 규제 수준과 법적 틀이 상이하다.
요약
네트워크 중립성은 기술적, 사회적, 법적으로 ISP가 모든 인터넷 트래픽을 동등하게 처리해야 한다는 원칙이다. 핵심은 차단·속도 저하·유료 우선순위 금지이며, ISP의 서비스 분류(통신/정보 서비스)에 따라 규제 강도가 달라진다.
이 원칙은 자유로운 정보 접근, 혁신, 공정 경쟁, 표현의 자유를 보호하는 데 핵심적 역할을 한다.