DB란
DB = 집합
DBMS = SW
redundancy = 중복성
중복된 데이터들이 생길수 있고 그로 인해 효율성이 떨어질수 있다 -> DBMS가 중복성을 관리한다.
DB 내부 동작
- 사용자가 쿼리 요청
- query parser가 알맞는 함수 호출
- storage manager가 알맞게 데이터 조작
- 디스크 스토리지에 실제로 write, read된다

애플이케이션으로 많은 데이터의 변화를 관리하기 힘들다.
그러므로 파일시스템으로 파일에 저장하는것 보단 DB 시스템에 저장하는걸로 해결한다.
DB 시스템이 필요한 이유
DBMS없이 파일 시스템으로 데이터를 관리한다면??
- Data redundancy and inconsistency: 중복된 데이터(중복성), 한쪽이 변경됐는데 중복된 부분은 변경이 안됨(일관성)
- Difficulty in accessing data: 예를들면 처음에는 텍스트 밖에 없을거라고 작성했다가, 이미지등 다양한 데이터를 관리하기 시작한다. 새로운 포맷 나올때마다 그에 맞게 프로그램을 작성해야된다.
- Data isolation: 데이터가 흩어져있거나 다른 형식으로 저장돼있을때, 사용자는 일관적인 방법으로 접근할 수 있도록 지원해준다.
- Integrity problems: 예를 들어 월급이 0원보다 낮는경우처럼 그런 실수에 대한 예외 처리 로직을 대신 수행해준다.
- Atomicity problems: DB수행은 원자적이어야된다 즉, 수행되는 도중에 결과를 유저한테 보여주면 안된다. 아래 그림처럼 중간에 일관적이지 않은 상태를 보여주는 문제가 생긴다.
- Concurrent-access anomalies: DBMS는 mutual exclusion(lock)을 보장해준다. 아래 그림처럼 두 연산이 동시에 각자 read해서(1000을 읽는다)해서 중간단계에 답을 구하고 덮어씌우는 동시성 문제가 생긴다.
- Security problems: DBMS는 모든 유저가 정해진 정보만 볼수 있도록 적절하게 권한 준다. 만약 파일 시스템이면 파일마다 그룹과 유저에 대해 복잡하게 권한 설정을 해야된다.



모델의 뜻

모델은 개념적인 것, 간단하게 표현만 한것이다.
큰 가격 없이 간단하게 시뮬레이션 하거나 일반인들도 간단히 이해하기 쉽게 한다.
데이터 모델의 종류
- Data relationships (관계)
- Data semantics (제한 조건)
- Consistency constraints (일관성 제약 조건)
데이터 추상화
데이터베이스를 사용하는 건 비전공자들에게도 이해할만한 추상적인 뷰를 보여주는게 목적이다.
어떻게 물리적으로 저장되는 등의 디테일들을 가리고 논리적인 뷰만 고려한다.
데이터베이스는 효율성을 위해서 복잡한 자료구조로 저장이 돼있는데, DBMS 사용자들은 대부분 비전공자들이다.

DBMS 계층
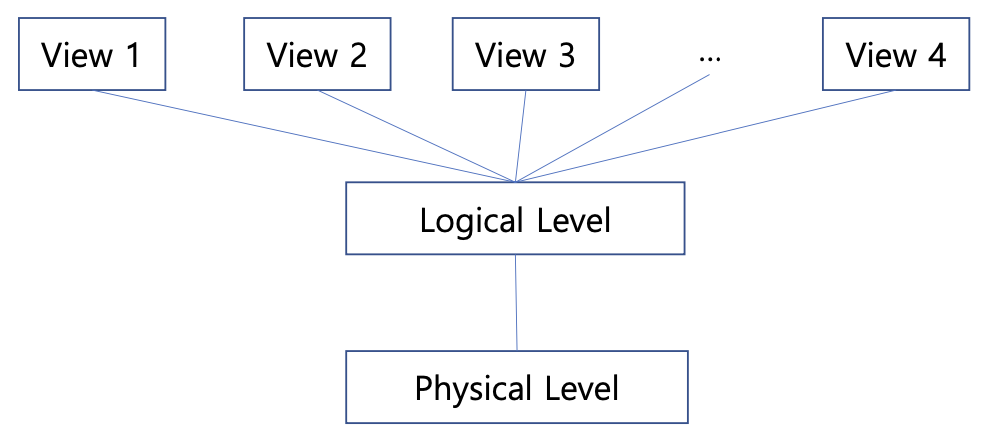
- 뷰: 각 사용자는 자신만의 뷰를 볼 수가 있고 권한에 허락된 데이터만 선별해서 보여준다.
- 논리적인 레벨: DB테이블등(권한X)
- 물리적인레벨: HDD, 플레시메모리에 어떻게 저장돼있는지
스키마(형태)
스키마는 프로그래밍 언어의 type, variable과 비슷하다
- Logical Schema: 데이터 베이스가 어떻게 구성돼있는지 보여준다.
- Physical Schema: 실제로 어떻게 물리적으로 저장돼있는가
물리적 데이터 독립성: 앱은 논리적 스키마랑 연결돼있으므로 물리적 스키마가 어떻게 달라지든 문제가 없다.
인스턴스
특정 시간의 실제 DB의 relation(테이블) 값을 말한다.
Physical data independence 논리적 스키마를 변경 없이 물리적 스키마를 자유롭게 변경할 수 있다.
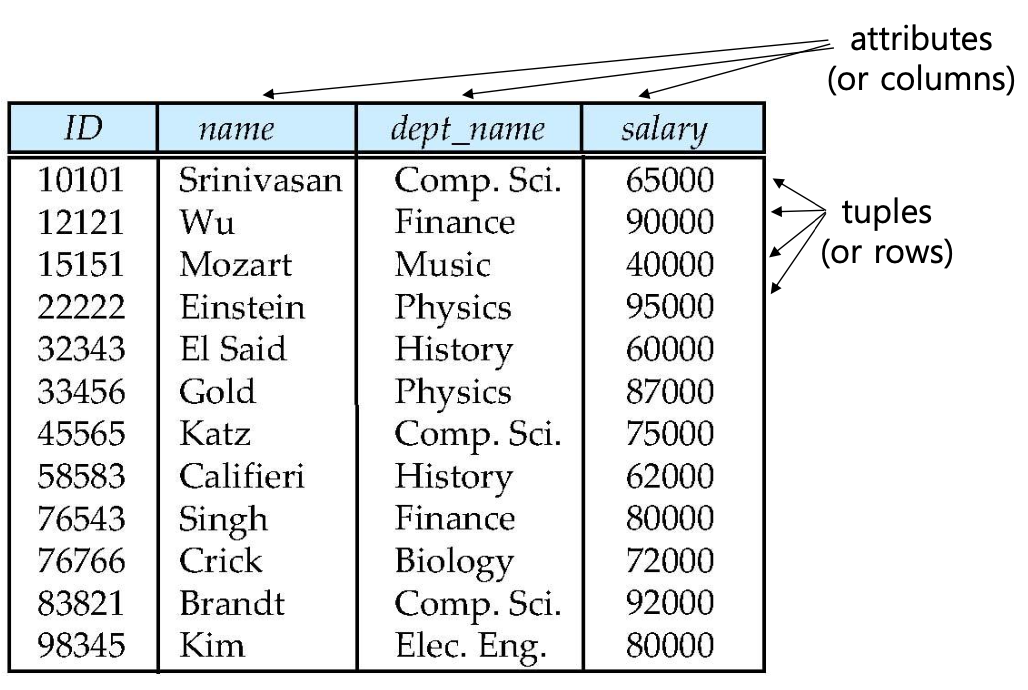
A relation(테이블)
- attributes
- tuples(rows)
- Attribute Types: 각 정해진 값(타입, 0~5등)을 가질수 있고, 이것을 domain이라고 부른다.
- Attribute values: 일반적으론 원자적이다 domain에는 기본적으로 null이 포함돼있다.
R = (A1, A2, …, An ) -> 스키마
예시) instructor 스키마 = (ID, name, dept_name, salary)
r(R) : 스키마 R의 인스턴스 r
DB는 대게로 자동 정렬 안한다.
DB는 효율적인 구조로 만들기 위해서 여러 relations로 구성된다.
하나의 relation에 때려박으면 공간낭비 같은 데이터의 반복과, null 값으로 채우기 때문이다.
Key : attributes를 조합해서 만들수 있는 집합
- superkey: 고유키 조건을 만족할때
- candidate key: superkey 중에서 제일 작은 단위로 구성된 후보키.
- primary key: candidate key중에 하나(유저가 임의로 설정)
- Foreign key: 반드시 다른 relation(테이블)에도 존재해야된다.
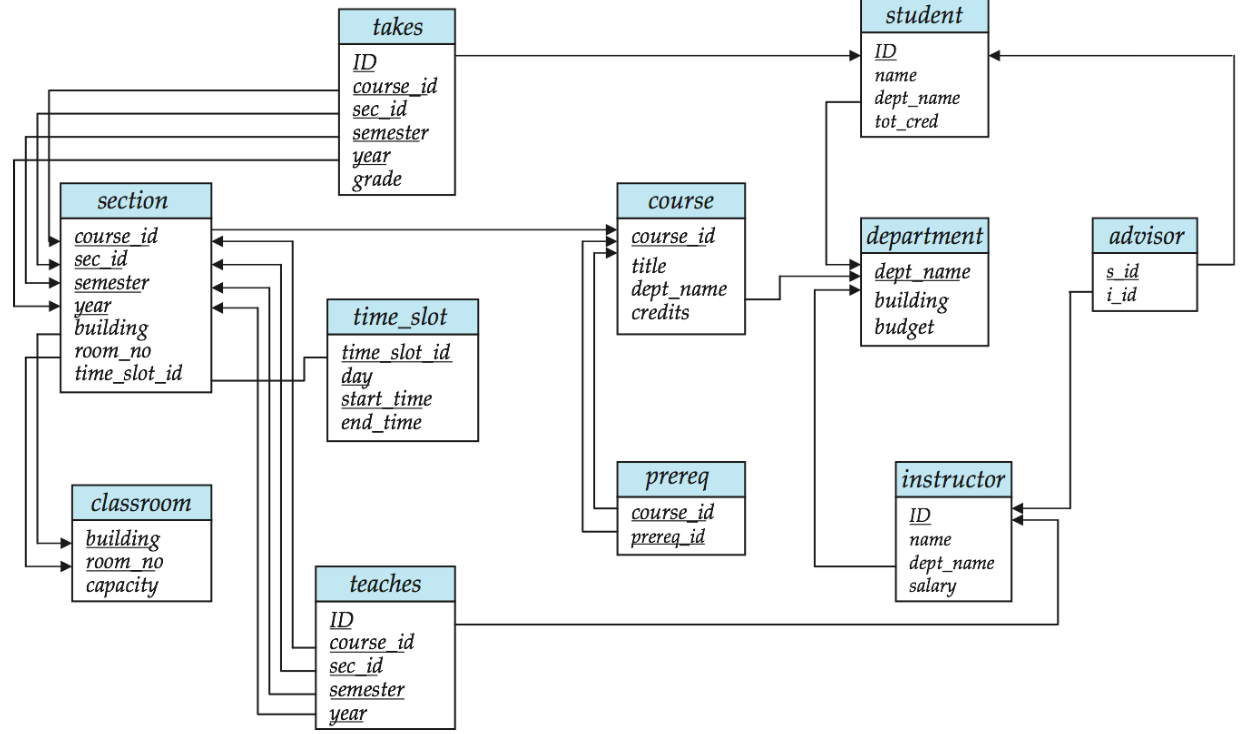
대학 DB의 스키마 다이어그램 예시
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 뷰(View) 정의와 사용, 삽입 (0) | 2025.03.26 |
|---|---|
| [데이터베이스] 조인 연산의 종류와 조건 (0) | 2025.03.26 |
| [데이터베이스] 기초 SQL (2) (0) | 2025.03.22 |
| [데이터베이스] 기초 SQL (1) (0) | 2025.03.16 |
| [데이터베이스] 관계 대수(Relational algebra)와 기본적인 SQL (0) | 2025.03.12 |



댓글