CPU Scheduling
CPU가 실행할 프로세스를 선택하는 행위를 CPU 스케줄링이라고 한다.
Basic Concepts
CPU가 놀지 않고 효율을 극대화하기 위해 스케줄링 알고리즘이 필요하다.
레디 큐(ready queue) 에 여러 프로세스가 대기 중일 때(멀티프로그래밍 환경에서) 의미가 있다.
Instruction Cycle
- CPU execution
- I/O wait : 이때 CPU는 사용되지 않음
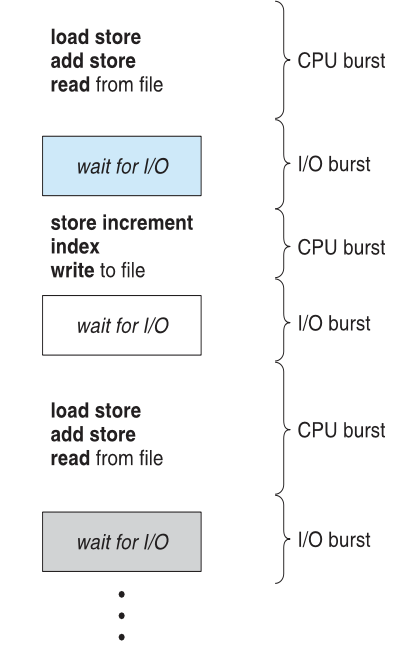
프로세스는 CPU burst → I/O burst → ... 형태로 번갈아가며 수행된다.
이때 CPU burst의 분배가 스케줄링의 핵심이다.
CPU Scheduler
Short-term Scheduler
레디 큐에서 실행할 프로세스를 선택하고, CPU 실행 권한을 부여한다.
프로세스 상태 변화에 따라 스케줄러가 작동하는 경우
- running → waiting
- running → ready (할당 시간 종료)
- waiting → ready (우선순위 높은 프로세스 등장 시 현재 실행 중인 프로세스를 선점)
- running → terminated
- 1, 4번은 nonpreemptive (비선점형)
- 2, 3번은 preemptive (선점형)
1, 4는 프로세스가 자의로 CPU를 반납하고,
2, 3은 외부에 의해 CPU를 뺏기는 상황이다.
Preemptive Scheduling
선점형 스케줄링은 실행 중인 프로세스가 있어도,
우선순위가 더 높은 프로세스가 도착하면 강제로 CPU를 선점할 수 있다.
Nonpreemptive Scheduling
프로세스가 CPU를 자의로 반납할 때까지,
스케줄러는 개입하지 않는다.
Preemptive 방식에서 고려사항
- 공유 데이터 접근 시 충돌 문제
- 커널 모드 작업 중 선점 가능 여부
- OS의 중요한 활동 도중 인터럽트 처리 방식
Dispatcher (커널 내부 모듈)
디스패처는 선택된 프로세스에게 CPU를 넘겨주는 역할을 한다.
디스패처의 주요 기능
- Context switching
- User mode로 전환
- 유저 프로그램의 적절한 지점으로 제어 이동(jump)
Dispatch latency
디스패처가 CPU를 이전 프로세스에서 새 프로세스로 넘기기까지의 지연 시간
Scheduling Criteria
- CPU utilization: CPU가 놀지 않도록 최대한 활용 (높을수록 좋음)
- Throughput: 단위 시간당 완료된 프로세스 수 (많을수록 좋음)
- Turnaround time: 하나의 작업이 걸리는 총 시간 (작을수록 좋음) : 실행을 완료하기 까지 총시간
- Waiting time: ready queue에서 대기한 총 시간
- Response time: ready 큐에 들어간 순간부터 첫 실행까지 걸린 시간
First-Come, First-Served (FCFS) Scheduling
먼저 ready 큐에 도착한 프로세스를 먼저 실행 (FIFO와 유사)
Gantt Chart 예시

- P1 = 0, P2 = 24, P3 = 27
- Average waiting time = (0 + 24 + 27) / 3 = 17
다른 순서였다면:

- P1 = 6, P2 = 0, P3 = 3 → 평균 3
Convoy Effect
긴 프로세스 뒤에 짧은 프로세스가 있으면, 긴 프로세스때문에 짧은 프로세스가 영향을 끼치고 전체 시스템의 응답성이 저하될 수 있다.
만약에 CPU-bound 프로세스 하나와 여러 I/O-bound 프로세스가 있으면 convoy effect가 발생할 수 있다.
Shortest-Job-First (SJF)

CPU burst time이 짧은 프로세스를 우선 실행
→ 이론상 평균 waiting time이 가장 낮음
현실적 어려움
- 프로세스의 CPU burst 시간을 미리 알기 어렵다
- 사용자에게 직접 물어보는 방식은 비현실적
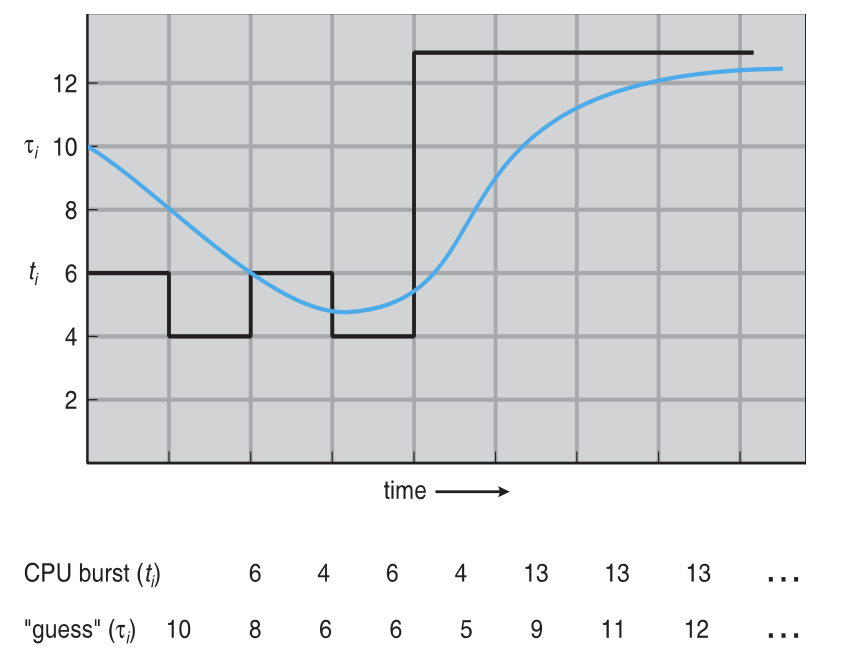
Estimating the Next CPU Burst (근사치)
이전 burst를 기반으로 다음 CPU burst를 예측해서 근사치를 아래 방법으로 구할 수 있다.
Exponential Averaging
- tₙ: 실제 n번째 CPU burst 시간
- τₙ: n번째 예측값
- τₙ₊₁ = α · tₙ + (1 - α) · τₙ
- 일반적으로 α = 0.5
α 값에 따른 영향
- α = 0 → 과거만 반영 (τₙ₊₁ = τₙ)
- α = 1 → 현재만 반영 (τₙ₊₁ = tₙ)
공식 전개:
- τₙ₊₁ = α · tₙ + (1 - α)α · tₙ₋₁ + (1 - α)²α · tₙ₋₂ + ... + (1 - α)ⁿ⁺¹ · τ₀
- α와 (1 - α)가 모두 1 이하이기 때문에, 뒤로 갈수록 각 항의 가중치는 점점 작아짐
1. Preemptive(선점형) – Shortest Remaining Time First (SRTF) 확장
- 실행 중이라도 더 짧은 프로세스가 도착하면 CPU를 빼앗긴다.
2. Non-preemptive(비선점형) – SJF
- 실행되면 끝날 때까지 CPU를 점유
Shortest-remaining-time-first (SJF)
선점형 스케쥴러로, 실행 중이라도 더 짧은 프로세스가 도착하면 CPU를 빼앗긴다.

Average waiting time = [(10-1)+(1-1)+(17-2)+(5-3)]/4 = 26/4 = 6.5
Priority Scheduling
모든 프로세스에 priority number(정수)를 할당하고, 숫자가 작을수록 우선순위가 높다.

- Preemptive: 실행 중에 더 높은 우선순위의 프로세스가 오면 현재 실행 중인 프로세스를 쫓아낸다.
- Nonpreemptive: 실행 중인 프로세스가 끝날 때까지 다른 프로세스가 CPU를 점유하지 못한다.
SJF는 예상 CPU burst time을 기준으로 하는 Priority Scheduling의 특수한 형태이다.
문제점
- Starvation: 우선순위가 낮은 프로세스는 CPU를 계속 할당받지 못할 수 있음
해결책
- Aging: 시간이 지날수록 프로세스의 우선순위를 점차 높여 starvation을 방지함
Round Robin 알고리즘

- 프로세스는 time quantum(q) 단위로 CPU를 할당받아 실행
- 정해진 시간이 지나면 CPU를 반환하고, 다음 프로세스로 넘어감
- 모든 프로세스에게 공평하게 실행 시간을 분배하는 방식
변수
- q: time quantum
- n: ready queue에 있는 프로세스 수
장점
- 어떤 프로세스도 (n - 1) * q 이상 기다리지 않음 (→ starvation 문제 해결)
q 값에 따른 특징
- q가 너무 크면 → FCFS와 비슷해짐
- q가 너무 작으면 → context switch 오버헤드 증가
- 반드시 context switch time < q 조건을 만족해야 효율적임

예시 (q = 4)
- Average waiting time = (6 + 4 + 7) / 3 = 5.67
- Turnaround time = (30 + 7 + 10) / 3 = 15.6
- Response time = (0 + 4 + 7) / 3 = 3.6
특성 요약
- 일반적으로 SJF보다 평균 turnaround time은 더 크지만,response time은 더 우수하다.
- q는 보통 10ms ~ 100ms,context switch time은 10μs 이하여야 한다.
Time Quantum과 Context Switch Time
- 스케줄링 효율성을 위해 context switch time < time quantum을 유지해야 한다.
- CPU bursts의 80%는 q보다 작아야 한다.

Multilevel Queue (Ready Queue)

- Ready Queue를 여러 개의 큐로 나눠 사용하는 방식
- 예:
- foreground (interactive) → Round Robin
- background (batch) → FCFS
특징
- 큐 간 프로세스 이동은 없음 (Feedback큐에선 있다)
- 각 큐마다 다른 스케줄링 알고리즘 적용 가능
큐 간 스케줄링 방식
- Fixed Priority Scheduling: 높은 우선순위의 큐부터 우선 처리 (starvation 위험 있음)
- Time Slice 방식: 각 큐에 일정 시간 할당 (예: foreground:background = 8:2)
Multilevel Feedback Queue
- 프로세스가 큐 간 이동 가능
- 낮은 우선순위 큐에 오래 머문 프로세스를 높은 우선순위 큐로 올릴 수 있어 aging 구현 가능
스케줄링 정책 설계 시 고려사항
- 큐의 개수
- 각 큐의 스케줄링 알고리즘
- 프로세스의 upgrade/demote 시점
- 초기 진입 시 어느 큐에 들어갈지
예시

- Q₀: Round Robin (8ms)
- Q₁: Round Robin (16ms)
- Q₂: FCFS
스케줄링 방식
- 새 작업은 Q₀에 진입 → 8ms 실행
- 미완료 시 Q₁로 이동 → 16ms 실행
- 그래도 미완료 시 Q₂로 이동 → FCFS로 마무리
- CPU 사용량이 많은 프로세스는 점점 뒤로 밀려난다
- CPU 사용량이 적은 프로세스는 우선 처리된다
- 현재 예시에서는 aging 미구현 상태
Thread Scheduling
- 지금까지는 프로세스를 기준으로 한 스케줄링
- 스레드를 지원하는 시스템에서는 스레드를 기준으로 스케줄링 수행
Process-Contention Scope (PCS)
- 사용자 스레드 라이브러리 수준의 스케줄링
- 하나의 프로세스 내에서 스레드들 간 우선순위 결정
- many-to-one 또는 many-to-many 모델에서는 user thread → LWP에 매핑
System-Contention Scope (SCS)
- 운영체제가 커널 스레드 단위로 스케줄링
- 커널 스레드는 운영체제 수준에서 CPU를 직접 할당받음
Pthread Scheduling (POSIX)
POSIX에서는 스레드 생성 시 PCS 또는 SCS 중 하나를 명시할 수 있음.
- PTHREAD_SCOPE_PROCESS → PCS 방식: 프로세스 내 스레드 간 경쟁
- PTHREAD_SCOPE_SYSTEM → SCS 방식: 커널이 모든 스레드 대상으로 스케줄링
Linux와 macOS는 PTHREAD_SCOPE_SYSTEM만 지원함
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
// 스레드가 실행할 함수 선언
void *runner(void *param);
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM_THREADS]; // 스레드 ID 배열
pthread_attr_t attr; // 스레드 속성 객체
// 기본 스레드 속성 초기화
pthread_attr_init(&attr);
// 현재 스케줄링 범위(scope) 확인
if (pthread_attr_getscope(&attr, &scope) != 0) {
fprintf(stderr, "Unable to get scheduling scope\n");
} else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS\n");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM\n");
else
fprintf(stderr, "Illegal scope value.\n");
}
// 스케줄링 방식을 시스템 수준으로 설정
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
// NUM_THREADS 개수만큼 스레드 생성
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i], &attr, runner, NULL);
// 각 스레드가 종료될 때까지 대기
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
return 0;
}
// 스레드가 실행할 함수 정의
void *runner(void *param) {
// 작업 수행 영역 (현재는 비어 있음)
pthread_exit(0); // 스레드 종료
}
리눅스: 1:1 스레드 모델
- 리눅스의 pthread는 1 user thread = 1 kernel thread
- 전부 커널에서 스케줄링
- → PTHREAD_SCOPE_PROCESS는 의미가 없으므로 무시됨
macOS: Mach 커널 기반 1:1 스레드 모델
- macOS도 모든 pthread는 커널 스레드
- 사용자 수준에서만 경쟁하는 PCS는 구현되지 않음
즉, 두 운영체제는 유저 스레드만을 위한 스케줄링 계층을 따로 두지 않는다.
PCS가 가능한 구조는 예전의 many-to-many 모델 또는 many-to-one 모델에서만 PCS가 의미 있음.
'CS 지식 > 운영체제 (OS)' 카테고리의 다른 글
| [운영체제] OS의 스레드 종류(User, Kernel)와 관련 아키텍처 소개 (1) | 2025.04.13 |
|---|---|
| [운영체제] OS의 프로세스(Process)의 개념과 구조, IPC 매커니즘 (0) | 2025.04.13 |
| [운영체제] OS의 구조와 서비스 종류 소개, 시스템 프로그램과 시스템 콜 소개 (0) | 2025.04.13 |
| [운영체제] OS의 듀얼모드와 작업(Operations)의 종류와 관리 기능 소개 (0) | 2025.04.13 |
| [운영체제] OS의 개념과 구조, 컴퓨터 시스템 아키텍처 소개 (1) | 2025.04.13 |




댓글