Classification of Physical Storage Media
- Volatile Storage
- 전원이 꺼지면 데이터가 소실됨
- 예: 캐시 메모리, 메인 메모리 등
- Non-Volatile Storage
- 전원이 꺼져도 데이터가 유지됨
- 예: Secondary Storage, Tertiary Storage, 배터리 백업 메모리 등
- 저장 매체 선택에 영향을 주는 요소
- 데이터 접근 속도 (Access Speed) : DRAM > SSD
- 단위 데이터당 비용 (Cost per Unit) : SSD > DRAM
- 신뢰성 (Reliability) : DRAM > SSD
Storage Hierarchy
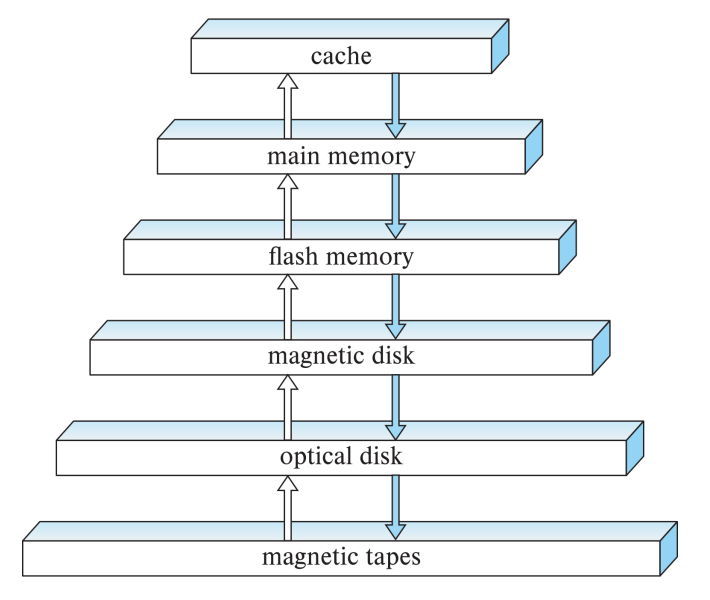
- Primary Storage
- 가장 빠르지만 Volatile
- 예: Cache, Main Memory
- Secondary Storage (On-line Storage)
- Non-Volatile, 중간 수준의 접근 속도
- 예: Flash Memory, Magnetic Disks
- Tertiary Storage (Off-line Storage)
- Non-Volatile, 가장 느린 접근 속도
- 주로 아카이브 용도로 사용됨
- 예: Magnetic Tape (엄청난 가성비 때문에 데이터센터에서 잘 쓴다), Optical Storage (CD, DVD)
- Magnetic Tape
- 순차 접근 (Sequential Access)
- 1~12TB 용량
- 소수의 드라이브, 다수의 테이프
- Jukebox 시스템은 페타바이트(Petabytes) 저장 가능
Storage Interfaces
- Disk Interface Standards
- SATA (Serial ATA): 최대 6 Gbps 전송 속도 (SATA 3)
- SAS (Serial Attached SCSI): 최대 12 Gbps (SAS v3)
- NVMe (Non-Volatile Memory Express): PCIe 인터페이스 기반, 최대 24 Gbps 지원
- 연결 방식
- 대부분 디스크는 컴퓨터에 직접 연결
- Storage Area Network (SAN): 고속 네트워크로 여러 디스크를 서버와 연결 (Block device)
- Network Attached Storage (NAS): 네트워크 파일 시스템 프로토콜을 사용하여 파일 시스템 인터페이스 제공
Flash Storage
- NAND Flash vs NOR Flash(SSD로는 잘쓰지 않는다.)
- NAND Flash
- 저장 용도로 널리 사용됨, NOR보다 저렴
- 페이지 단위 읽기 (512B ~ 4KB)
- 페이지 읽기 속도: 20 ~ 100 마이크로초
- 순차 읽기와 랜덤 읽기의 차이가 크지 않음
- 페이지는 한 번만 쓰기 가능, 다시 쓰기 위해서는 먼저 Erase 필요
- NAND Flash
- Solid State Disk (SSD)
- 내부적으로 여러 개의 Flash Storage를 사용
- SATA 인터페이스: 최대 500 MB/s
- NVMe PCIe: 최대 3 GB/s
Flash Storage 특징
- Erase Operation
- Erase Block 단위로 삭제 (256KB ~ 1MB, 128~256 페이지)
- 삭제 시간: 2 ~ 5 밀리초
- Flash Translation Layer (FTL)
- 논리적 페이지 주소 → 물리적 페이지 주소로 매핑
- 매핑 정보는 Flash Page의 label 필드에 저장
- 지우는 동안 기다리지 않기 위해 재매핑 수행

- Wear Leveling
- Erase Block은 약 100,000 ~ 1,000,000번 삭제 후 신뢰성 상실
- 균등한 쓰기를 통해 특정 블록이 집중적으로 마모되는 것을 방지
SSD Performance Metrics
- IOPS (Input/Output Operations Per Second)
- Random 4KB Reads: 약 10,000 IOPS
- Random 4KB Writes: 약 40,000 IOPS
- SSD는 병렬 읽기 지원
- QD-32 (32개의 병렬 요청 시):
- SATA: 100,000 IOPS (4KB reads)
- NVMe PCIe: 350,000 IOPS (4KB reads)
- 4KB writes: 100,000 IOPS 이상 (모델에 따라 더 높을 수 있음)
- QD-32 (32개의 병렬 요청 시):
- Sequential Read/Write 전송 속도
- SATA3: 약 400 MB/s
- NVMe PCIe: 2 ~ 3 GB/s
- Hybrid Disks (하이브리드 디스크)
- 소량의 Flash Cache + 대용량의 Magnetic Disk 조합
Storage Class Memory (SCM)
- 3D-XPoint 메모리 기술 (Intel 주도)
- 제품명: Intel Optane
- 2017년부터 SSD 인터페이스로 출하
- Flash SSD보다 낮은 지연시간 제공
- 2018년에는 메모리 인터페이스 버전 발표
- Main Memory 수준의 속도로 단어 단위 직접 접근 가능 (Direct Access)
- 2022년 이후
- Intel Optane 3D-XPoint Memory 단종 (Deprecated)
- 새로운 기술: CXL-Memory
File Organization
- 데이터베이스는 여러 개의 파일(files) 로 구성됨.
- 각 파일은 레코드(records) 의 sequence이다.
- record = attribute (key - value 형태)
- 각 레코드는 필드(fields) 의 sequence이다.
DB 저장하기 위한 간단한 접근:
- 고정 크기(fixed-length) 의 레코드 가정
- 각 파일은 하나의 레코드 타입만 포함
- 서로 다른 relation(테이블)은 서로 다른 파일로 저장
- 모든 레코드는 하나의 디스크 블록, Page(4kb)보다 작다고 가정
파일 구성?
아래에 설명할 방식은 Page(4kb)에 레코드를 저장하는 방식이다.
파일은 여러개의 page를 담고있고, 디스크 I/O는 “페이지(Page)” 단위로 발생한다.
즉, 파일 전체를 한 번에 I/O하지 않고, 필요한 페이지 단위로만 읽고 쓰기 때문에 페이지 단위로 저장하는 방식을 설명하겠다
Fixed-Length Records의 경우
단순한 테이블 저장 방식 접근:

- 레코드 i는 n * (i – 1) 바이트부터 시작 (n: 레코드 크기)
- 블록 경계를 넘지 않도록 조정 해야한다. (한 record를 읽기 위해서 I/O가 여러번 일어나게 되므로)
레코드 삭제 방법의 종류 :
1. 레코드 i+1 ~ n을 한 칸씩 앞으로 이동 (record 3 삭제 예시)
나머지 레코드를 땡겨오는 방식으로 파일을 compact하게 사용할 수 있으나, shift 오버헤드가 상당히 크다.

2. 마지막 레코드 n을 삭제된 i 위치로 이동
삭제된 레코드3을 삭제하고 그 자리에 마지막 레코드인 11을 넣어서 shift 오버헤드를 방지 하는 방법인다.
그러나 ordering(순서)을 보장할 수 없다

3. 레코드를 이동하지 않고 free list에 삭제된 위치를 연결
삭제된 레코드를 실제로 지우지 않고, ‘빈 자리 목록’으로 연결시켜 놓는다. (이것도 순서 보장을 완벽히는 할 수 없다.)
- 장점: 삭제/삽입 시 빠르게 처리 가능 (빈 자리를 재활용할 수 있음)
- 단점: 구현이 복잡해질 수 있고, 레코드가 실제로는 흩어지게 됨 → 탐색 성능 저하 가능

Variable-Length Records의 경우
가변 레코드가 필요하게되는 이유
- 다양한 레코드 타입을 하나의 파일에 저장 가능
- 가변 길이 타입 (e.g. varchar) 지원
반복 필드 허용 가능(옛 데이터 모델에서 사용됨)
가변 길이 레코드 저장 방식
[고정 길이 필드1][고정 길이 필드2][가변길이_메타데이터1(offset, length)][가변길이_메타데이터2(offset, length)]...[가변길이_데이터]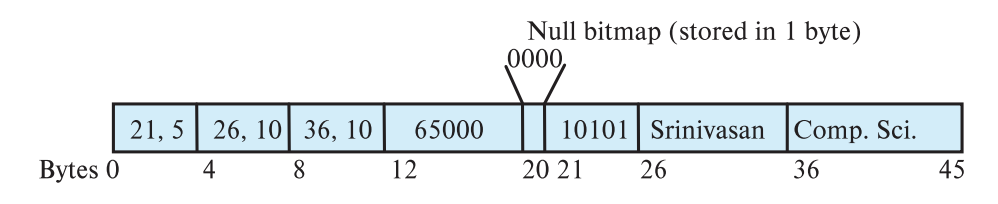
- 속성(attribute)값들은 순서대로 저장된다.
- 앞쪽(고정 길이 필드)에 실제 데이터의 정보(<offset, length>쌍으로 이루어진 배열) 를 저장한다
- 뒷쪽(가변 길이 필드)에는 가변 길이 속성(Variable length attributes)이 저장되는데, <offset, length> 쌍으로 이루어진 배열에 의해 참조된다.
- 각 속성마다 어디(offset)에 얼마의 길이(length)만큼의 데이터가 있는지를 명시함
- Null 값은 null-value bitmap으로 표현
- 예: 속성이 4개일 경우, 1010은 1번째와 3번째 속성이 null임을 의미
장단점:
- 장점: 유연한 저장 구조, 공간 효율성
- 단점: 구조가 복잡하며, 접근 시 계산이 필요함
Variable-Length Records: Slotted Page Structure 방식
Slotted Page Structure란, 가변 길이 레코드를 효율적으로 저장하기 위한 구조로 Block header, free space, record로 나뉜다 offset정보가 저장된다.

슬롯 헤더(Slotted Page Header)는 다음 정보를 포함:
- 레코드 수 (number of record entries)
- 페이지 내 빈 공간의 끝 위치 (end of free space)
- 각 레코드의 위치와 크기 (location and size of each record) -> offset
- 레코드는 페이지 내에서 이동 가능하며, 빈 공간 없이 연속적으로 재정렬됨
- 레코드를 직접 가리키는 포인터 대신, 헤더에서 레코드의 엔트리(시작주소)를 가리키는 포인터 사용
Slotted Page Structure 예시
- 슬롯 헤더: 레코드 1 → 오프셋 1000, 레코드 2 → 오프셋 900
- 레코드들은 페이지의 끝부터 거꾸로 채워짐
- 빈 공간은 헤더와 레코드 사이의 공간으로 존재
- 레코드 접근은 헤더의 offset array를 통해 수행됨
1. 초기 모습
Block header, free space가 존재하고 record는 아직 안들어간 모습이다.

2. 첫번째 record 삽입
record는 <key, value>로 돼있는 튜플인데, <30, 내용> 이라는 record가 뒷쪽 부터 삽입된다.

3. 슬록헤더에 Record offset array에 원소 삽입 및 정렬(초기 원소이므로 정렬할 필욘 없다.)
아래 보라색으로 나와있는 배열 record offset array로 key값 기준으로 정렬(sorted keys)이 돼있는 배열이다.
각 배열에는 <offset, length> 레코드가 각 저장돼있다.
아래는 <1000, 24> 레코드가 record offset array의 첫번째 인덱스로 저장이 되고, key=30기준으로 상시 정렬이 되는 상태이다.

4. 슬롯헤더에 metadata에 record 갯수가 기록이 된다.

4. 두번째 record 삽입
<50, value> 레코드가 이전 record의 offset이전에 저장된다.

5. 슬롯헤더에 Record offset array에 원소 삽입 및 정렬(딱히 순차적으로 넣으면 되므로 필요없다.)
<900, 100>으로 돼있는 record offset 원소가 array에 삽입된다.

6. 세번째 record 삽입 (만약에 key 순서가 맞지 않다면?)

5. 슬롯헤더에 Record offset array에 원소 삽입 및 정렬
<800, 100>으로 돼있는 record offset 원소가 array에 삽입되고, key값을 기준으로 다시 정렬된다.
반면 record content area는 shift의 오버헤드를 방지 하기 위해서 재배치를 하지 않고, Record offset array만 정렬된다.

Storing Large Objects (BLOB/CLOB)
- 일반 레코드는 페이지 크기보다 작아야 함
- 대용량 객체(LOB: Large Object)는 다음과 같은 방식으로 저장 가능:
- 파일 시스템에 별도 저장 -> 외부 파일 시스템의 포인터로 저장. inconsistency 문제가 생길수 있음
- DBMS 내부에서 파일처럼 관리
- 다수의 튜플로 나누어 별도 relation에 저장
- 예: PostgreSQL의 TOAST (The Oversized-Attribute Storage Technique)
Organization of Records in Files
- Heap: 자유롭게 공간이 있는 위치에 레코드 저장 = slotted page랑 비슷함.
- Sequential: 검색 키 값 기준으로 순차적 저장
- Multitable Clustering:
- 여러 relation의 레코드를 하나의 파일에 저장
- 예: department와 instructor를 같은 블록에 저장
- 관련된 튜플들을 물리적으로 가까이 배치해 I/O 효율성 증가
- B+ Tree:
- 정렬 유지
- 삽입/삭제가 있어도 순서를 유지함
- Hashing:
- 해시 함수 기반으로 레코드를 저장할 블록 결정
Heap File Organization

- 레코드를 임의 위치에 저장
- 한 번 저장된 레코드는 일반적으로 이동하지 않음
힙 파일 구성 : Free-space map
- Free-space map은 디스크 블록마다 얼마나 공간이 비어 있는지를 기록하는 자료 구조이다.
- 각 블록마다 하나의 entry가 있으며, 이 entry는 몇 비트 혹은 1바이트 미만으로 구성된다.
- 예를 들어, 3비트 per 블록일 경우 가능한 값은 0부터 7까지이며, 이를 8로 나누어 비어 있는 비율로 해석한다.
- 예: 값이 4이면 4 ÷ 8 = 0.5 → 해당 블록의 50%가 비어 있다는 의미
1단계 Free-space map

- 아래와 같은 배열이 있다고 가정한다:
- 각 숫자는 해당 블록의 비어 있는 정도를 나타내는 값이다.
- 4개씩 묶어서 구분한 것은 2단계 요약 맵 생성을 위한 기준이다.
2단계 Free-space map

- 상위 맵에서는 위의 배열을 4개씩 묶어 각 묶음에서 최대값만 추출하여 저장한다.
- 결과적으로 생성되는 2단계 맵은 다음과 같다:
- 즉, 각 묶음에서 가장 많은 free-space를 가진 블록의 상태를 요약해 저장한다.
기타 특성
- Free-space map은 주기적으로 디스크에 저장된다.
- 일부 entry 값이 오래되었거나 잘못된 값이어도 무방하며, 이후 탐지 및 복구가 가능하다.
Sequential File Organization
링크드 리스트를 사용한다. 순서를 유지해준다.
- 순차 처리가 필요한 애플리케이션에 적합
- 검색 키 값 기준으로 정렬됨

삽입과 삭제
- 삭제: 포인터 체인 사용
- 삽입:
- 위치에 공간 있으면 삽입
- 없으면 오버플로 블록에 삽입
- 포인터 체인 갱신 필요

- 주기적으로 파일을 reorganize 해 순차적 순서를 복원해야 함
Multitable Clustering File Organization

보통 테이블 당 한 파일에 저장을 했으나, 조인 연산 할때마다 두개의 파일에 두번 I/O 액세스를 해야된다.
-> 합치는것을 multitable clustering이라 한다.
- 여러 관계(relation) 를 하나의 파일 에 클러스터링 저장
- 예: department와 instructor 레코드들을 같은 블록에 저장
- 장점:
- 조인(department ⨝ instructor) 또는 특정 부서와 소속 강사 조회에 유리
- 단점:
- 특정 관계만 조회하는 경우에는 비효율적 -> 파일이 커지므로
- 가변 크기 레코드로 인해 복잡성 증가
- 특정 relation의 레코드를 연결하기 위해 포인터 체인 사용
Column-Oriented Storage

데이터사이언스/데이터분석할때는 튜플기반이 아닌 colum 단위로 데이터를 저장하는 방식이 유리하다
- Columnar Storage / Column-Oriented Storage라고도 불림
- 하나의 relation(테이블)의 각 속성(attribute)을 별도의 컬럼 단위 파일로 저장
- 각 속성(column)을 독립적으로 접근할 수 있도록 하여, 특정 속성만 조회 시 I/O 효율을 극대화
- 장점:
- 분석/OLAP(Online Analytical Processing)에 적합
- 동일 속성의 데이터가 모여 있어 압축 효율이 높음
- 단점:
- 레코드 단위 접근이 많은 경우 비효율적
Data Dictionary (System Catalog)
- 메타데이터(metadata)를 저장하는 시스템 테이블
- 유저가 만든 데이터를 저장된게 아니라, 데베 시스템을 유지 위한 데이터이다.
- 즉, 데이터에 대한 데이터
저장 정보:
- 릴레이션에 대한 정보
- 테이블(relationship)의 이름
- 속성(attribute)의 이름, 타입, 길이
- 뷰(view)의 정의
- 무결성 제약조건 (integrity constraints)
- 사용자 정보, 패스워드, 회계 정보
- 통계 및 설명 데이터 (e.g., 튜플 수)
- 물리적 저장 방식 정보 (e.g., sequential, hash 등)
- 인덱스 정보 (→ Chapter 14에서 상세 설명 예정)
Relational Representation of System Metadata
- 메타데이터 역시 관계형 테이블로 디스크에 저장된다.
- 하지만 실제 시스템 동작 시 메모리 내에서는 특별한 자료구조로 변환하여 효율적 접근이 가능하도록 설계됨
'CS 지식 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 버퍼와 인덱싱 개념과 종류 (Buffer and index in DBMS) (0) | 2025.05.08 |
|---|---|
| [데이터베이스] 정규화(Normalization)와 함수 종속성, BCNF분해, 3NF분해, 종속성 규칙과 공리 (0) | 2025.04.10 |
| [데이터베이스] 모델링, 관계집합, E-R 다이어그램(ERD), Cardinality (매핑관계) (0) | 2025.04.04 |
| [데이터베이스] 권한과 권한 그룹(역할), 상속, 뷰 권한 (grant, revoke, role) (1) | 2025.04.01 |
| [데이터베이스] 트랜잭션과 무결성 제약 조건, 도메인 (0) | 2025.04.01 |



댓글