Write Optimized Indices와 LSM Tree, Skip list, Redis zset
Write Optimized Indices
B+ tree는 write-intensive workload(쓰기 중심 작업) 환경에서 성능이 저조할 수 있다.
- 모든 internal node가 메모리에 있다고 가정해도, leaf node당 한 번의 I/O가 필요하다.
- 자기 디스크(magnetic disk) 사용 시, 디스크당 초당 100번 미만의 insert 처리 성능을 보인다.
- 플래시 메모리(flash memory)에서는 insert마다 한 페이지를 overwrite한다.
쓰기 비용(write cost)을 줄이기 위한 대표적 접근법 중 하나가 Log-structured merge tree(LSM tree)이다.
Log Structured Merge (LSM) Tree
LSM tree는 write-intensive workload를 위해 설계된 인덱스 구조이다.
- 빠른 삽입(fast insertion)이 가능하다.
- 검색 성능은 moderate(적당한 수준)이다.
다양한 key-value store 시스템에서 널리 사용된다.
- 예시: BigTable, HBase, Cassandra, RocksDB, WiredTiger, InfluxDB, ScyllaDB 등
LSM Tree의 구조와 동작
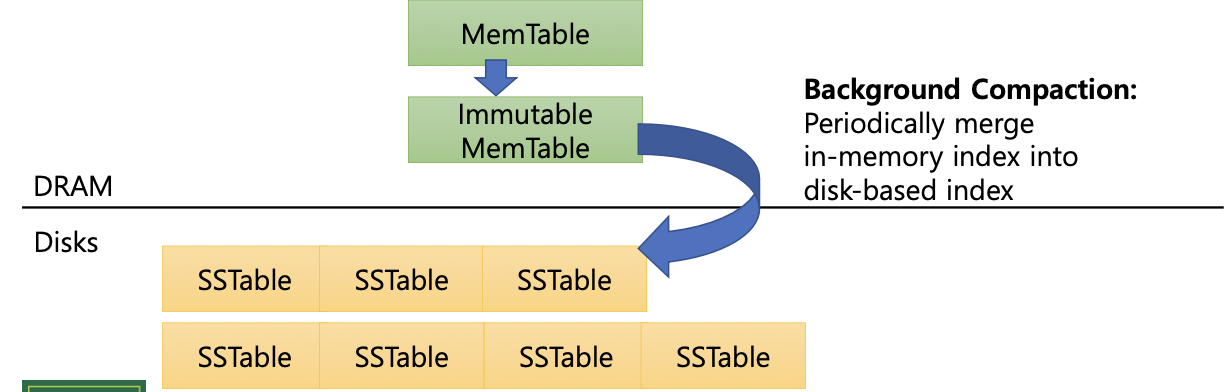
- 데이터는 먼저 메모리 상의 MemTable에 삽입된다.
- MemTable이 가득 차면 immutable MemTable로 전환된다.
- immutable MemTable은 주기적으로 디스크 기반의 SSTable로 merge(compaction)된다.
- 이 과정을 background compaction이라고 하며, 메모리 인덱스를 디스크 인덱스로 병합하는 역할을 한다.
- 결과적으로 DRAM에는 MemTable, 디스크에는 여러 개의 SSTable이 존재하게 된다.
LSM Tree의 삽입 과정
데이터 삽입(insertion)은 MemTable의 head부터 tail 방향으로 진행된다.
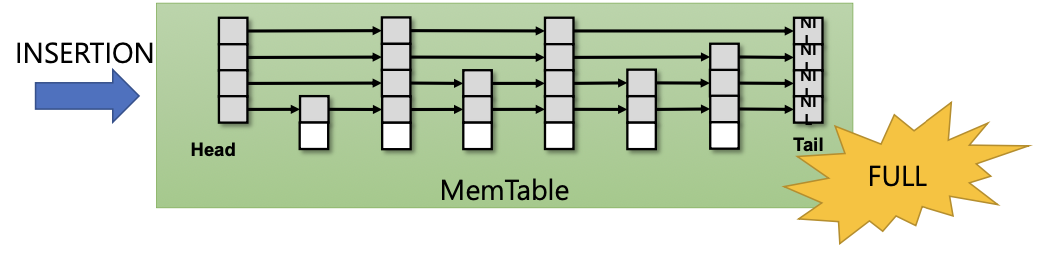
- 위는 skip list 자료구조로 돼있고, 데이터를 모았다가 한번에 Disk에 insert하기 위함이다.
- MemTable이 가득차게되면 수정 불가 상태로 전이한다.
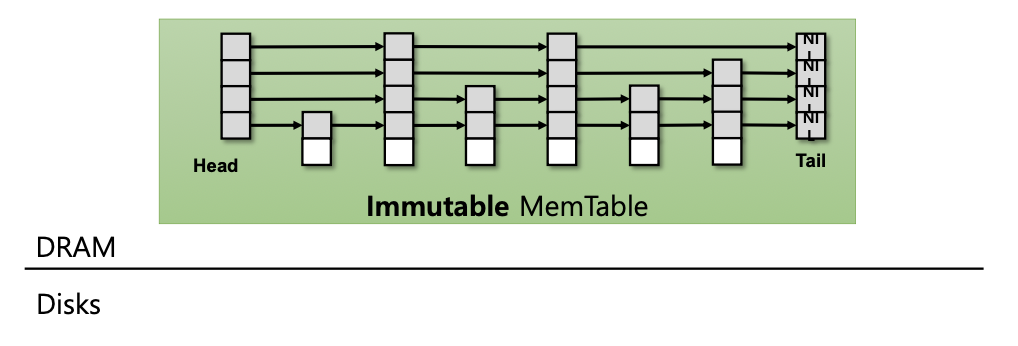
- 가득차게 돼서 수정불가(immutable)한 상태가 된 모습이다.
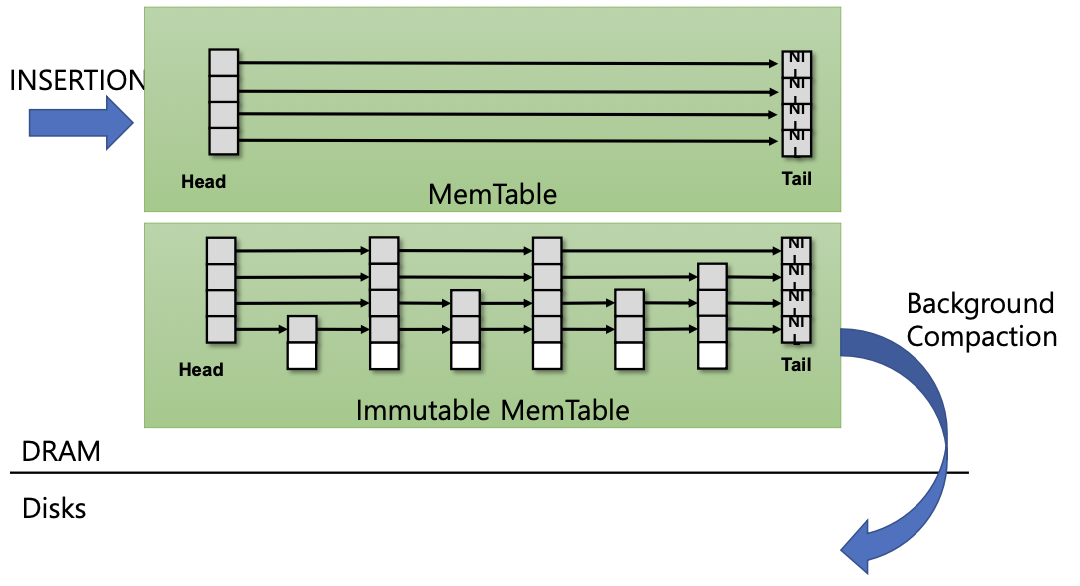
- background thread에 의해서 disk에 쓰이게 된다.
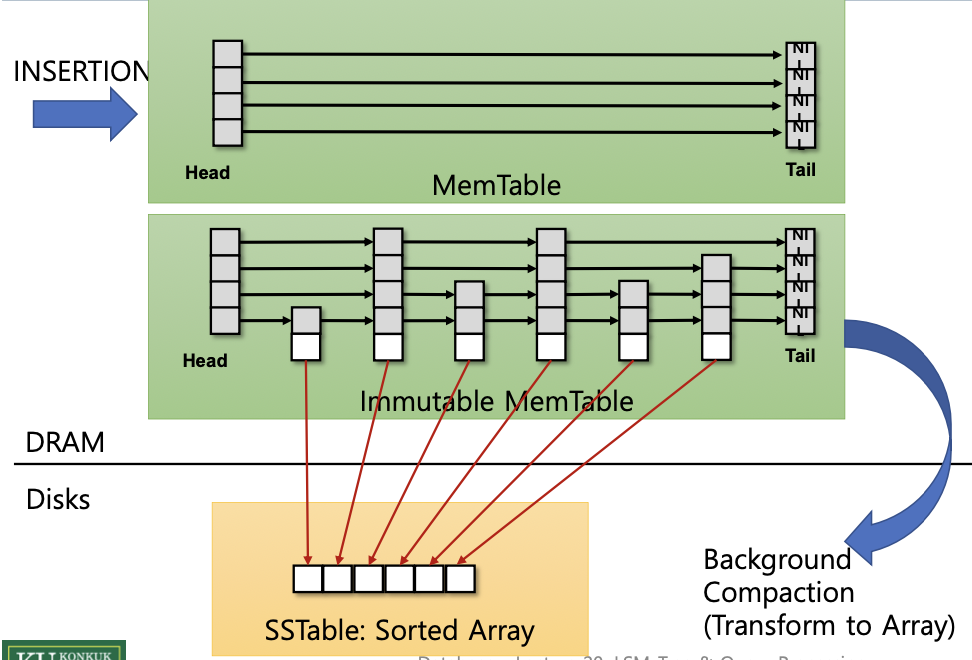
- SSTable로 정렬되면서 비동기적으로 쓰여진다. 이 연산은 병목 현상의 원인이 된다.
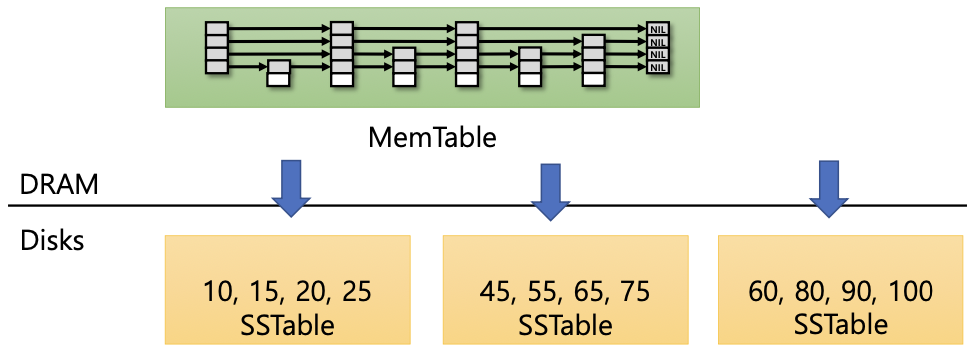
- 위 결과 예시를 보면 key의 범위가 겹치는것을 확인할수 있다. 이는 그저 정렬해서 저장했을뿐이다.
- Compaction은 중복 데이터 제거, 오래된 데이터 삭제, 범위 정렬 유지 등 역할을 한다.
- 이상적 시나리오: 메모리 쓰기는 매우 빠르고, 디스크 compaction도 충분히 빠르게 처리되어 MemTable이 block되지 않는다.
LSM Tree는 write 성능이 중요한 환경에서 B+ tree의 한계를 극복하기 위한 대표적인 데이터 구조로, 실제로 다양한 대규모 분산 데이터베이스에서 표준적으로 사용된다.
현실의 LSM 트리: 병목과 문제점
(1) Write Amplification Problem (쓰기 증폭 문제)
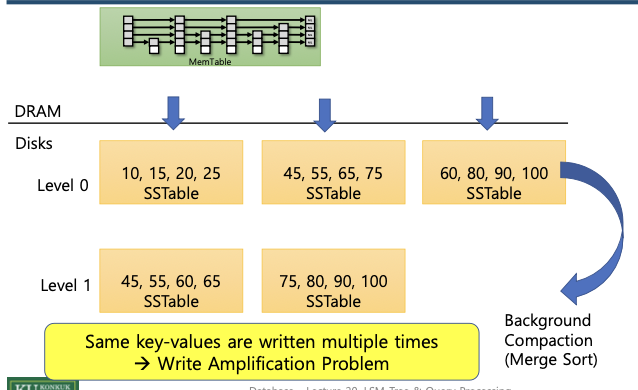
- 같은 key-value가 여러 번 디스크에 기록된다.
- Compaction 과정에서 동일 데이터가 여러 SSTable을 거치며 반복적으로 merge되어, 실제 쓰기 I/O가 증가한다.
(2) Write Stall Problem (쓰기 정체 문제)

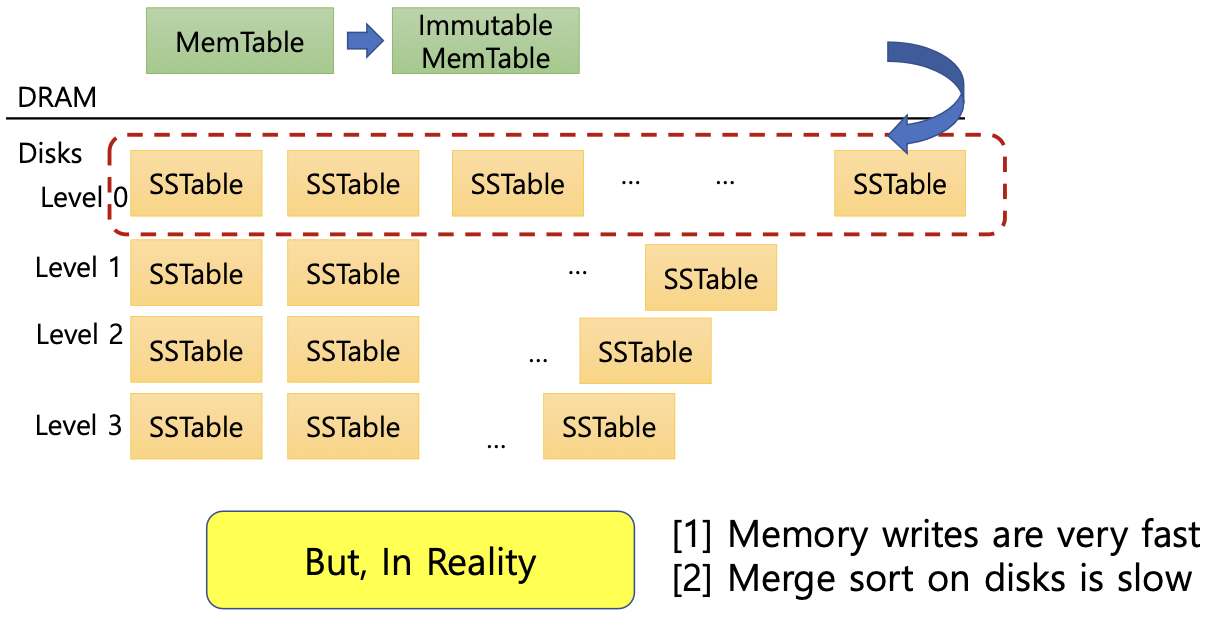
- MemTable이 가득 차서 immutable 상태가 되었는데, 디스크의 compaction(merge sort)이 충분히 빠르지 않으면, 새로운 MemTable을 만들 수 없다. (더 이상 쓰기 연산을 수행 할 수 없다.)
- 이때 쓰기 작업이 일시 중단(stall)된다.
- 즉, 메모리 쓰기는 매우 빠르지만, 디스크 merge sort가 느려서 전체 쓰기 처리량이 병목에 걸린다.
4. 실제 동작 요약
- 이상적: MemTable → Immutable MemTable → SSTable → Compaction이 자연스럽게 이어짐
- 현실: Compaction이 느리면, SSTable이 쌓이고, MemTable flush가 막히며, 쓰기 정체(write stall)가 발생
SkipList 개념 및 연산 과정
SkipList: Randomized Data Structure
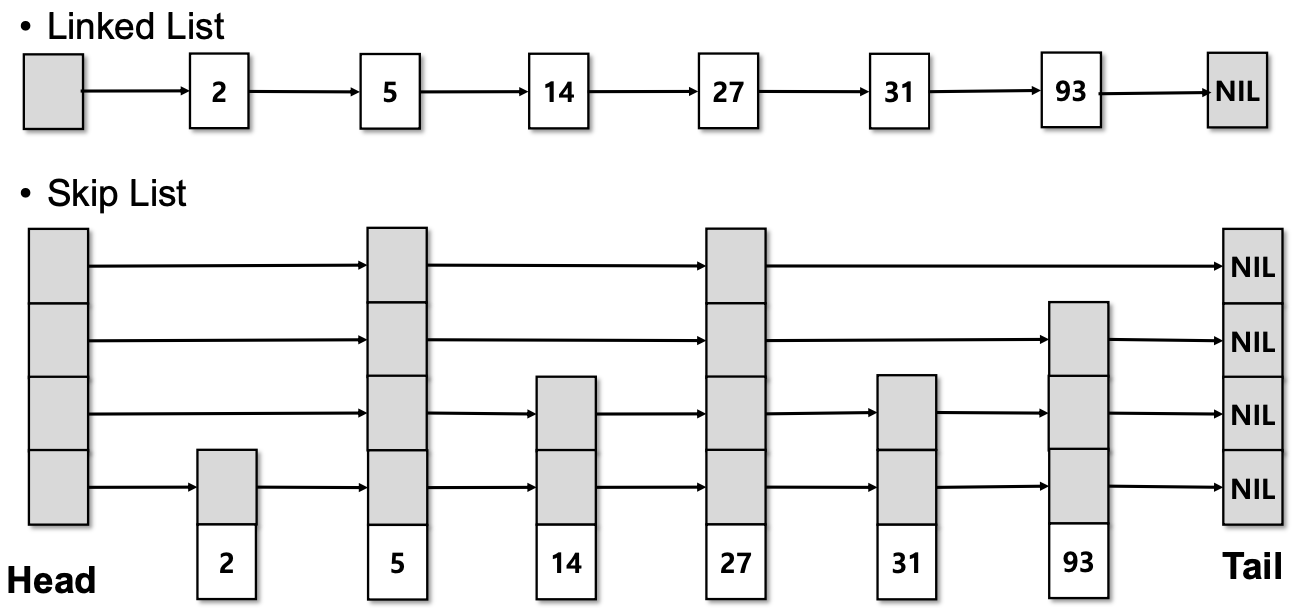
- SkipList는 linked list(연결 리스트) 기반의 randomized data structure(랜덤화 자료구조)이다.
- 일반적인 linked list는 모든 노드를 순차적으로 탐색해야 하므로, 탐색 시간이 길어진다.
- SkipList는 여러 레벨(level)로 구성된 포인터 구조를 사용하여, 상위 레벨에서 노드를 건너뛰며 빠르게 탐색할 수 있다.
- 각 노드는 1개 이상의 레벨에 포함될 수 있으며, 레벨이 높을수록 더 많은 노드를 건너뛸 수 있다.
- Head와 Tail 노드가 각각 시작과 끝을 나타낸다.
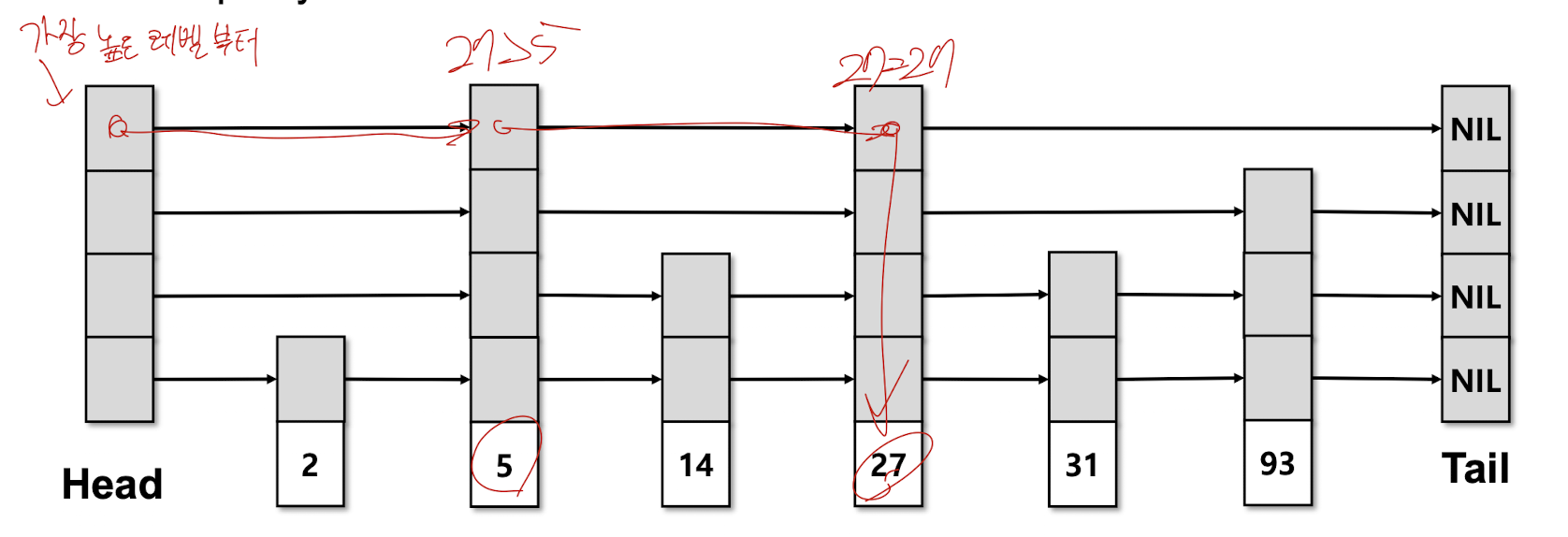
SkipList Lookup
- 특정 key(예: 27)를 탐색할 때, 상위 레벨부터 시작해 오른쪽으로 이동하며 key를 찾는다.
- 현재 노드의 오른쪽 값이 찾는 key보다 크거나 같을 때, 한 단계 아래 레벨로 내려간다.
- 이 과정을 반복하여 최종적으로 key를 포함하는 노드에 도달한다.
- SkipList의 탐색 시간은 평균적으로 log(n)이다.
key 27 탐색 예시
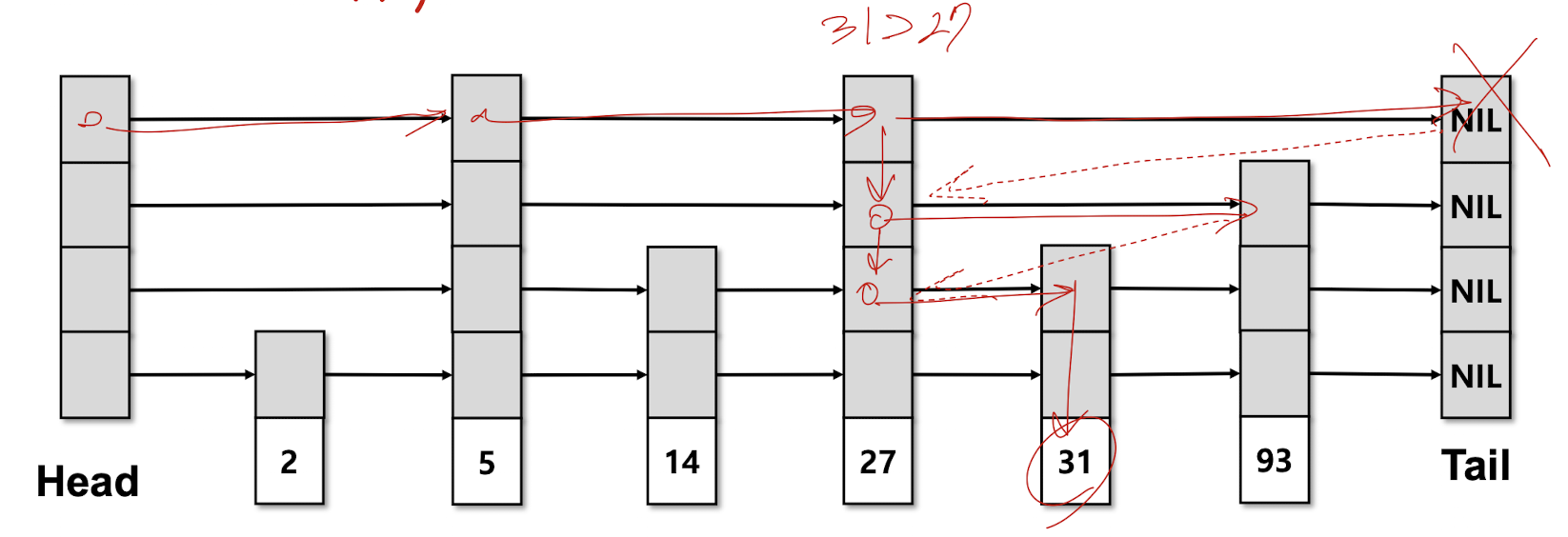
key 31 탐색 예시
SkipList Insert
예시: key 20을 level 3으로 삽입하는 경우

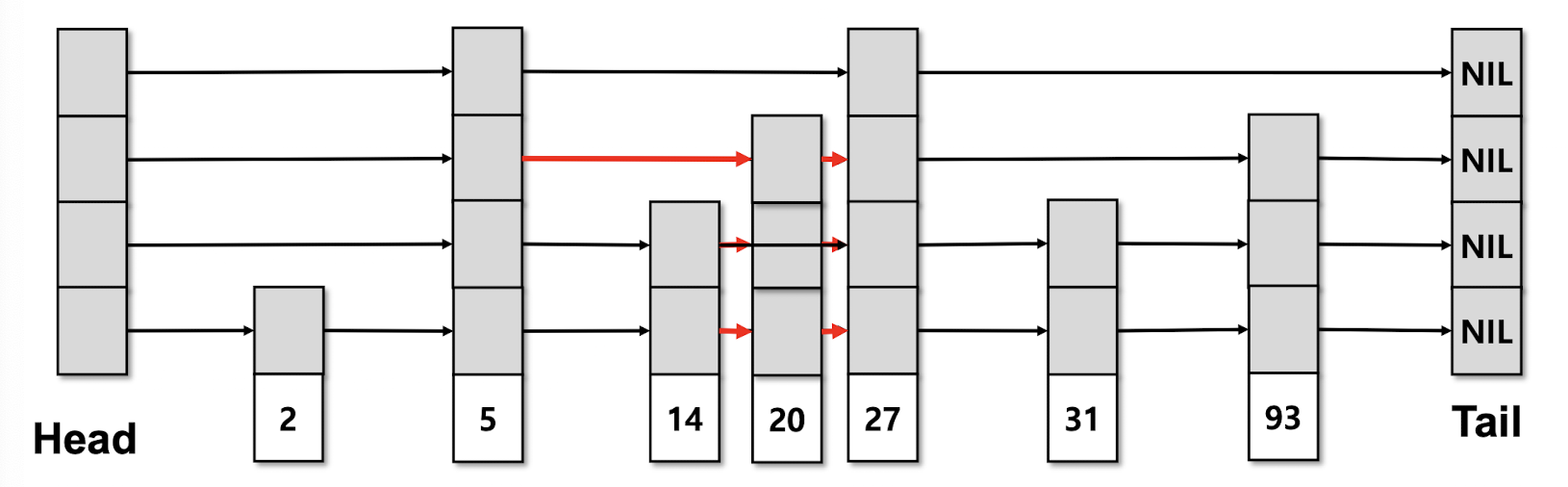
- 삽입 위치를 찾기 위해 lookup과 동일한 방식으로 경로를 탐색한다.
- key 20이 들어갈 위치의 포인터들을 새 노드로 연결한다.
- 삽입된 노드는 3개 레벨에 걸쳐 포인터를 가진다.
- 각 레벨마다 기존 노드의 포인터를 새 노드로 갱신한다.
삽입 연산 역시 평균적으로 log(n)의 시간 복잡도를 가진다.
SkipList Delete
예시: key 14를 삭제하는 경우
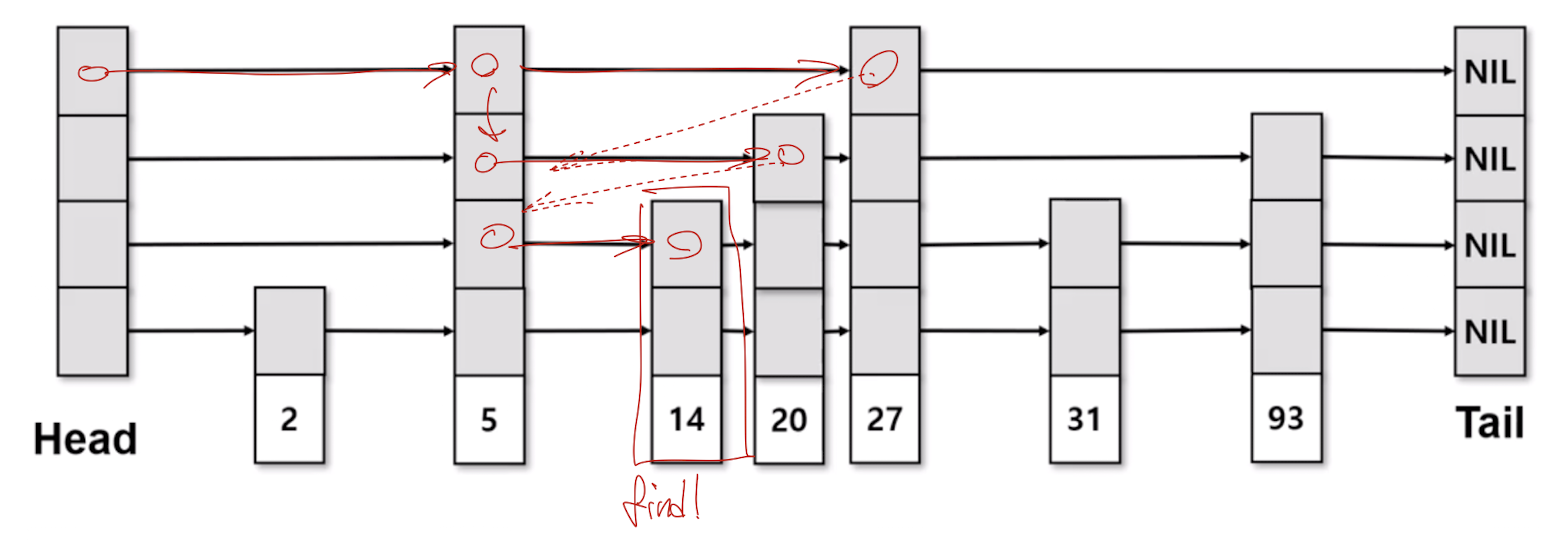

- 삭제할 key의 위치를 lookup 방식으로 찾는다.
- 각 레벨에서 삭제 대상 노드를 건너뛰도록 포인터를 재연결한다.
- 모든 레벨에서 해당 노드가 연결 해제되면 삭제가 완료된다.
삭제 연산 또한 평균적으로 log(n)의 시간 복잡도를 가진다.
- SkipList는 단순한 구조와 효율적인 탐색, 삽입, 삭제 연산을 동시에 제공하는 대표적인 randomized data structure이다.
- 특히 LSM Tree 등 write-intensive 시스템에서 인덱스 구조로 널리 활용된다.
Hash Table(해시 테이블) 개념
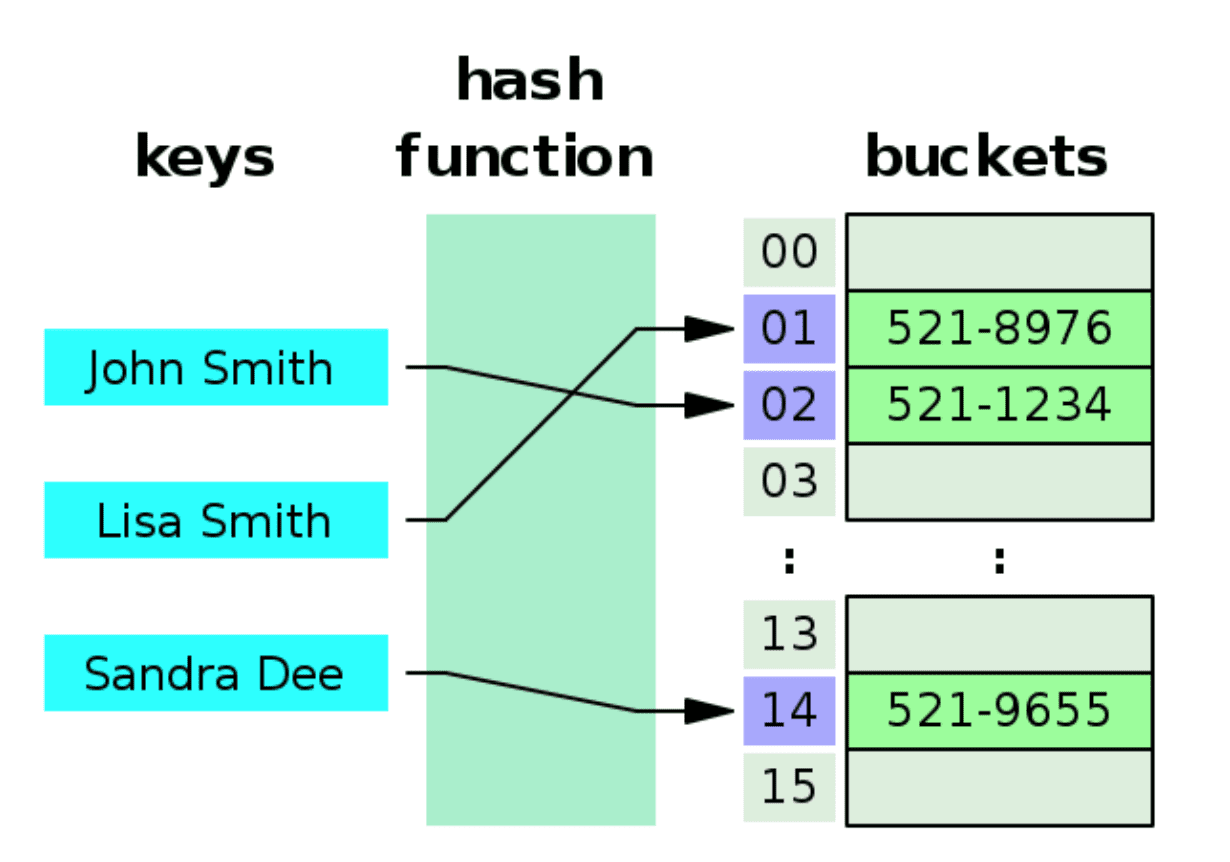
- Hash Table은 key-value 쌍 데이터를 저장하는 자료구조이다.
- key에 해시 함수(hash function)를 적용하여 배열의 인덱스를 계산하고, 해당 위치에 데이터를 저장한다.
- 삽입, 조회, 삭제 연산이 평균적으로 O(1) 시간복잡도를 가진다.
- 해시 충돌(collision)이 발생할 수 있는데, 이는 서로 다른 key가 같은 해시값을 갖는 경우이다.
- 충돌 해결 방식으로는 chaining(체이닝, 연결 리스트로 충돌 키를 저장) 또는 open addressing(개방 주소법, 빈 슬롯을 찾아 저장)이 있다.
- 해시 테이블의 크기가 너무 작으면 충돌이 많이 발생해 성능이 저하될 수 있으므로, 적절한 크기로 동적 확장(resize)하는 기능이 필요하다.
- 해시 테이블은 key의 존재 여부를 빠르게 확인할 수 있다는 점이 가장 큰 장점이다.
Redis ZSet(Sorted Set)의 내부 동작 원리

ZSet의 데이터 구조
Redis의 ZSet(정렬 집합)은 각 요소가 고유한 member(문자열)와 score(실수값)로 구성된다.
ZSet은 내부적으로 Hash Table과 Skip List 두 자료구조를 동시에 사용한다.
1. Hash Table 역할
- key: member (문자열)
- value: score (실수값)
용도:
- member의 존재 여부를 O(1)로 확인
- 특정 member의 score를 O(1)로 조회
- ZADD, ZREM, ZSCORE 등에서 빠른 접근성 제공
예시:
- ZADD로 member "user1"의 score를 100으로 추가 → hash table에 ("user1", 100) 저장
- ZSCORE로 "user1"의 score 조회 시 hash table에서 바로 반환
2. Skip List 역할
- 각 노드는 (member, score) 쌍으로 구성
- score를 기준으로 항상 정렬된 상태를 유지
- 용도:
- score 순 정렬, 범위 검색, 순위(rank) 계산 등에서 효율적
- ZRANGE, ZRANGEBYSCORE, ZRANK, ZREVRANK 등에서 사용
- Skip List는 평균적으로 O(log n) 시간복잡도로 삽입, 삭제, 탐색이 가능
- 삽입/삭제 시 score 기준으로 노드 위치를 찾아 skip list를 갱신
ZSet 주요 연산의 내부 동작
ZADD (member, score 추가/갱신)
- Hash Table에서 member 존재 여부 확인
- 이미 있으면 기존 score를 얻음
- Skip List에서 기존 score 위치의 노드를 삭제(기존 member라면)
- Hash Table에 (member, score) 저장 또는 갱신
- Skip List에 (member, score) 노드를 score 기준으로 삽입
ZREM (member 삭제)
- Hash Table에서 member 존재 여부 확인
- Hash Table에서 해당 member 삭제
- Skip List에서 해당 score 위치의 노드 삭제
ZSCORE (member의 score 조회)
- Hash Table에서 member의 score를 O(1)로 바로 반환
ZRANK/ZREVRANK (member의 순위 조회)
- Skip List에서 score 기준으로 탐색하여 해당 member의 순위를 계산 (O(log n))
ZRANGE/ZRANGEBYSCORE (범위 조회)
- Skip List에서 score 또는 rank 범위에 해당하는 노드들을 순차적으로 탐색하여 결과 반환
ZSet의 구조적 장점과 최적화
- Hash Table은 member→score 매핑, 존재 확인, score 조회 등 단일 member 기반 연산에 최적화
- Skip List는 score 정렬, 범위/순위 연산 등 집합 전체를 대상으로 하는 연산에 최적화
- 두 자료구조는 항상 동기화되어 유지된다:
- member가 추가/삭제/갱신될 때마다 hash table과 skip list 모두에서 동작이 일어난다.
- ZSet의 요소가 적을 때는 ziplist(압축 리스트)로 저장하다가, 임계값을 넘어서면 hash table + skip list 구조로 자동 전환된다.
Redis ZSet의 활용 예시
- 실시간 랭킹 시스템: 사용자 점수에 따라 순위 산출 및 범위별 조회
- 게임 리더보드: score 기준으로 상위 n명 조회, 사용자 점수 갱신
- 우선순위 큐: score를 우선순위로 활용한 데이터 처리
반응형




댓글