1. 개요

공공데이터포털 API를 호출하여 대용량 데이터를 S3 RAW 영역에 적재하고, AWS Glue를 통해 ETL 작업을 수행하는 배치 파이프라인을 구축 중이었다.
배치 작업(Batch Job)은 AWS Lambda를 사용했다. 핵심 요구사항은 '최소 비용'이었기 때문에, Lambda의 메모리를 512MB와 같이 낮게 제한하며 테스트를 진행했다. 이 과정에서 두 가지 주요 문제를 만났고, 이를 해결하며 페이지네이션(Pagination), 스트리밍(Streaming), 그리고 S3의 고수준/저수준 API 차이에 대해 명확히 알게 되었다.
2. 문제 1: Runtime.OutOfMemory (메모리 초과)
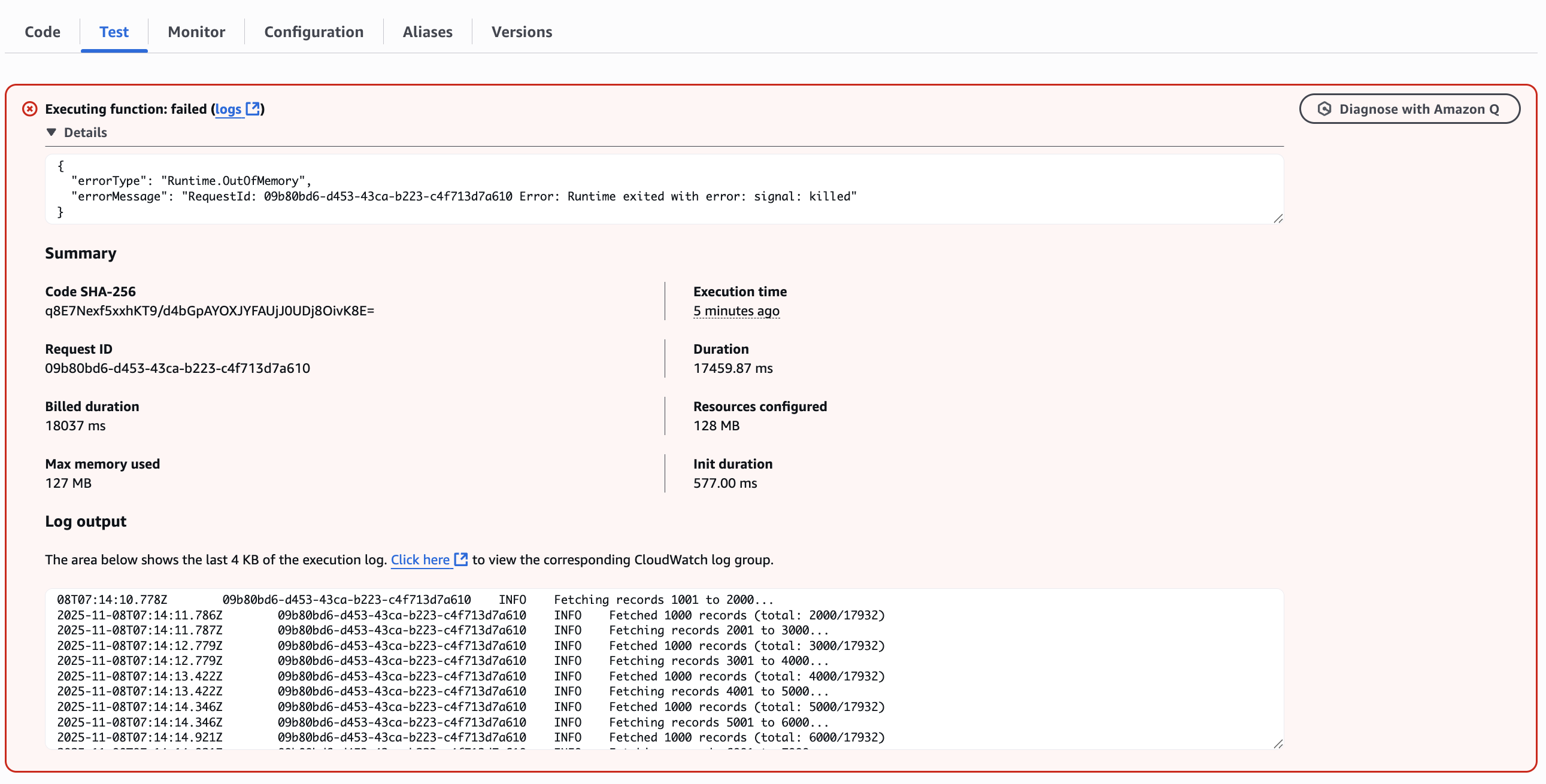
초기 코드는 API가 제공하는 페이지네이션(Pagination)을 활용했다. while 반복문으로 1,000건씩 API를 호출한 뒤, 응답받은 데이터를 Lambda 메모리의 allRows라는 단일 배열(Array)에 계속 누적(push)시켰다.
반복문이 모두 종료된 후, 메모리에 쌓인 1GB가 넘는 allRows 배열을 JSON.stringify를 통해 직렬화하고 PutObjectCommand로 S3에 한 번에 업로드하려 했다.
// 문제의 초기 로직 (개념)
const allRows = [];
let startIndex = 1;
// 1. 페이지네이션으로 1,000건씩 API 호출
while (startIndex <= totalCount) {
const batchData = await fetchBatch(startIndex);
// 2. 응답 데이터를 메모리의 'allRows' 배열에 누적
allRows.push(...batchData.row); // <- 이 지점에서 메모리 사용량 폭증
startIndex += 1000;
}
// 3. 누적된 모든 데이터를 한 번에 S3에 업로드
await s3Client.send(new PutObjectCommand({
Bucket: S3_RAW_BUCKET,
Key: 'single-large-file.json',
Body: JSON.stringify(allRows) // <- 이 시점에 OutOfMemory 발생
}));- 원인: API 응답 데이터의 총량이 Lambda에 할당된 메모리(512MB)를 초과했다. 1GB가 넘는 데이터를 단일 배열에 모두 저장하려다 Runtime.OutOfMemory 오류가 발생했다.
3. 1차 해결 시도: 스트리밍(Streaming) 도입
OutOfMemory 문제를 해결하기 위해, 데이터를 메모리에 '쌓아두는' 방식이 아닌, API 응답을 받는 즉시 S3로 '흘려보내는' 스트리밍(Streaming) 기법을 도입했다.
개념: 스트리밍(Streaming)이란?
스트리밍은 데이터를 한 번에 모두 로드하여 처리하는 것이 아니라, 데이터가 '흐르는' 동안 순차적으로 처리하는 방식이다. 이 경우, Lambda는 1,000건의 API 응답(JSON)을 받으면, 이 응답 스트림(response.body)을 메모리에 저장하지 않고 즉시 S3로 전달한다.
이 방식을 적용하면 Lambda는 데이터를 중개할 뿐 메모리를 거의 사용하지 않으므로, 128MB의 최소 메모리로도 GB 단위의 데이터를 처리할 수 있다.
적용: 작은 파일로 분할 적재 (Split Files)
while 반복문 로직을 수정했다. 1,000건의 API 응답이 올 때마다 allRows 배열에 push하는 대신, part_001.json, part_002.json 과 같은 작은 파일로 즉시 S3에 분할 적재하도록 변경했다.
// 스트리밍 시도 코드 (1차 수정)
let startIndex = 1;
let partIndex = 1;
while (startIndex <= totalCount) {
const response = await fetch(apiUrl); // 1,000건 API 호출
const partS3Key = `part_${partIndex}.json`;
console.log(`Streaming to S3: ${partS3Key}`);
const uploadParams = {
Bucket: S3_RAW_BUCKET,
Key: partS3Key,
// Node.js 스트림(ReadableStream)을 Body로 직접 전달
Body: response.body,
ContentType: 'application/json'
};
// 저수준(low-level) API로 스트림 업로드 시도
await s3Client.send(new PutObjectCommand(uploadParams));
startIndex += 1000;
partIndex++;
}- 결과: 이 로직으로 Runtime.OutOfMemory 문제는 완벽히 해결되었다. 하지만, 곧바로 새로운 문제가 발생했다.
4. 문제 2: Unable to calculate hash for flowing readable stream

메모리 문제는 해결했지만, S3 업로드 단계에서 Unable to calculate hash for flowing readable stream (흐르는 스트림의 해시를 계산할 수 없음)이라는 치명적인 오류가 발생했다.
- 원인: AWS S3 SDK의 PutObjectCommand는 저수준(low-level) API이다.
- 이 API는 데이터 무결성 검증을 위해 업로드 전에 Content-Length(파일 전체 크기) 또는 Content-MD5(파일 해시) 값을 S3 서버에 알려주려 시도한다.
- 하지만 response.body는 '흐르는 스트림'이다. 데이터 수신이 완료되기 전까지는 전체 크기나 해시를 미리 알 수 없다. SDK가 '흐르는 데이터'의 해시 계산에 실패하며 오류를 반환한 것이다.
5. 최종 해결: S3 고수준(High-Level) API, @aws-sdk/lib-storage 적용
이 문제는 스트리밍(대용량 파일) 업로드를 위해 특별히 설계된 고수준(high-level) API를 사용하여 해결했다.
- 해결: PutObjectCommand 대신, @aws-sdk/lib-storage 라이브러리의 Upload 클래스를 사용했다. 이 라이브러리는 Lambda 런타임에 기본 내장되어 있어 별도 .zip 배포가 필요 없다.
- 작동 방식:
- Upload 클래스는 스트림을 입력받으면, Content-Length를 미리 알 필요가 없다.
- 대신, 스트림 데이터를 내부적으로 정해진 크기(기본 5MB)의 "조각(Chunk)"으로 나눈다.
- 이 조각들을 S3 멀티파트 업로드(Multipart Upload) 프로토콜을 사용해 병렬로 전송한다.
- 모든 조각의 전송이 완료되면 S3에서 하나의 파일로 조합한다.
// 최종 해결 코드
// @aws-sdk/lib-storage는 Lambda 런타임에 기본 내장
import { Upload } from "@aws-sdk/lib-storage";
import { S3Client } from "@aws-sdk/client-s3";
const s3Client = new S3Client({});
// ... while 반복문 내부 ...
const response = await fetch(apiUrl); // API 호출
// 1. 고수준 API 'Upload' 인스턴스 생성
const parallelUploads3 = new Upload({
client: s3Client,
params: {
Bucket: S3_RAW_BUCKET,
Key: partS3Key,
Body: response.body, // 스트림을 그대로 전달
ContentType: 'application/json'
}
});
// 2. 스트림이 완료될 때까지 멀티파트 업로드 실행
await parallelUploads3.done();
console.log(`Part ${partIndex} uploaded successfully.`);
최종 코드(민감 정보 제거)
LLM이용해서 민감한 정보를 MASKED로 바꿨다
import { S3Client } from '@aws-sdk/client-s3';
import { GlueClient, StartJobRunCommand } from '@aws-sdk/client-glue';
// PutObjectCommand 대신 lib-storage의 Upload를 임포트합니다.
import { Upload } from "@aws-sdk/lib-storage";
// --- 설정 (고정값) ---
const S3_RAW_BUCKET = "food-donor-raw-data-v1";
const GLUE_JOB_NAME = "food-donor-ETL-job-v1";
const API_BASE_URL = "http://openapi.seoul.go.kr:8088";
const MAX_BATCH_SIZE = 1000;
// AWS SDK 클라이언트 초기화
const s3Client = new S3Client({ region: process.env.AWS_REGION || 'ap-northeast-2' });
const glueClient = new GlueClient({ region: process.env.AWS_REGION || 'ap-northeast-2' });
export const handler = async (event, context) => {
console.log('Event received:', JSON.stringify({
...event,
service_key: event.service_key ? "***MASKED***" : undefined // 민감 정보 마스킹
}, null, 2));
const { district_name: DISTRICT, service_key: SERVICE_KEY, api_endpoint: API_ENDPOINT } = event;
if (!DISTRICT || !SERVICE_KEY || !API_ENDPOINT) {
throw new Error('Missing required parameters: district_name, service_key, api_endpoint');
}
const today = new Date().toISOString().split('T')[0];
const s3KeyPrefix = `raw_data/${DISTRICT}/${today}/`;
try {
// =========================================================
// 1. 전체 데이터 개수 확인 (Step 1)
// =========================================================
console.log(`Step 1: Checking total data count for district: ${DISTRICT}`);
// countCheckUrl log 시에는 서비스키 마스킹 처리
const countCheckUrl = `${API_BASE_URL}/${SERVICE_KEY}/json/${API_ENDPOINT}/1/1/`;
const maskedCountCheckUrl = countCheckUrl.replace(SERVICE_KEY, '****MASKED****');
console.log(`Count check URL: ${maskedCountCheckUrl}`);
const countResponse = await fetch(countCheckUrl, { headers: { 'Accept': 'application/json' } });
if (!countResponse.ok) throw new Error(`Count check API request failed: ${countResponse.status}`);
const countData = await countResponse.json();
const countDataKey = Object.keys(countData).find(key => key !== 'RESULT');
if (!countDataKey) throw new Error('Unable to find data key in count response');
const countDataObject = countData[countDataKey];
if (countDataObject?.RESULT && countDataObject.RESULT.CODE !== 'INFO-000') {
throw new Error(`API Error (Count): ${countDataObject.RESULT.MESSAGE || 'Unknown error'}`);
}
const totalCount = countDataObject?.list_total_count;
if (!totalCount || totalCount === 0) {
console.log('No data found for this district.');
return { statusCode: 200, body: 'No data found, ingestion skipped.' };
}
console.log(`Total data count: ${totalCount}`);
// =========================================================
// 2. 데이터 스트리밍 및 S3에 분할 저장 (Step 2)
// =========================================================
console.log(`Step 2: Fetching and streaming all ${totalCount} records in batches of ${MAX_BATCH_SIZE}...`);
let startIndex = 1;
let partIndex = 1;
while (startIndex <= totalCount) {
const endIndex = Math.min(startIndex + MAX_BATCH_SIZE - 1, totalCount);
// 마스킹된 API URL 로깅
const apiUrl = `${API_BASE_URL}/${SERVICE_KEY}/json/${API_ENDPOINT}/${startIndex}/${endIndex}/`;
const maskedApiUrl = apiUrl.replace(SERVICE_KEY, '****MASKED****');
console.log(`Fetching records ${startIndex} to ${endIndex} from: ${maskedApiUrl}`);
const response = await fetch(apiUrl, { headers: { 'Accept': 'application/json' } });
if (!response.ok) throw new Error(`API request failed: ${response.status} at batch ${startIndex}`);
// [메모리 최적화 + 해시 오류 해결]
// PutObjectCommand 대신 S3 멀티파트 업로더 (Upload)를 사용합니다.
const partS3Key = `${s3KeyPrefix}part_${partIndex.toString().padStart(5, '0')}.json`;
console.log(`Streaming to S3: s3://${S3_RAW_BUCKET}/${partS3Key}`);
const parallelUploads3 = new Upload({
client: s3Client,
params: {
Bucket: S3_RAW_BUCKET,
Key: partS3Key,
Body: response.body, // 스트림을 Body로 직접 전달
ContentType: 'application/json'
},
partSize: 1024 * 1024 * 5, // 5MB 단위로 조각내어 업로드
queueSize: 4 // 동시 4개 파트 업로드
});
// 업로드가 완료될 때까지 기다립니다.
await parallelUploads3.done();
console.log(`Part ${partIndex} uploaded successfully.`);
startIndex = endIndex + 1;
partIndex++;
}
console.log(`Successfully fetched and streamed all ${totalCount} records into ${partIndex - 1} parts.`);
// =========================================================
// 3. Glue ETL Job 실행 트리거
// =========================================================
const glueS3InputPath = `s3://${S3_RAW_BUCKET}/${s3KeyPrefix}`;
console.log(`Triggering Glue Job: ${GLUE_JOB_NAME} with input path: ${glueS3InputPath}`);
const glueParams = {
JobName: GLUE_JOB_NAME,
Arguments: {
'--S3_INPUT_PATH': glueS3InputPath,
'--DISTRICT_NAME': DISTRICT,
'--EXECUTION_DATE': today
}
};
const glueResponse = await glueClient.send(new StartJobRunCommand(glueParams));
console.log(`Glue Job started: ${glueResponse.JobRunId}`);
return {
statusCode: 200,
body: JSON.stringify({
message: 'Data ingestion and streaming completed successfully',
district: DISTRICT,
s3Folder: glueS3InputPath,
glueJobRunId: glueResponse.JobRunId
})
};
} catch (error) {
console.error('Error in handler:', error);
return {
statusCode: 500,
body: JSON.stringify({
error: 'Data ingestion failed',
message: error.message
})
};
}
};6. S3 적재 결과 확인
수정된 Lambda 함수를 실행한 결과, S3 RAW 버킷에 데이터가 의도한 대로 적재된 것을 확인했다.
- 저장 경로 (Prefix): s3://[버킷명]/raw_data/[구이름]/[날짜]/ (예: raw_data/gwangjin/2025-11-09/)
- 저장 파일: 해당 경로(폴더) 내부에 API가 분할 호출된 횟수만큼 part_00001.json, part_00002.json, ..., part_00500.json 형태의 파일들이 생성되었다.
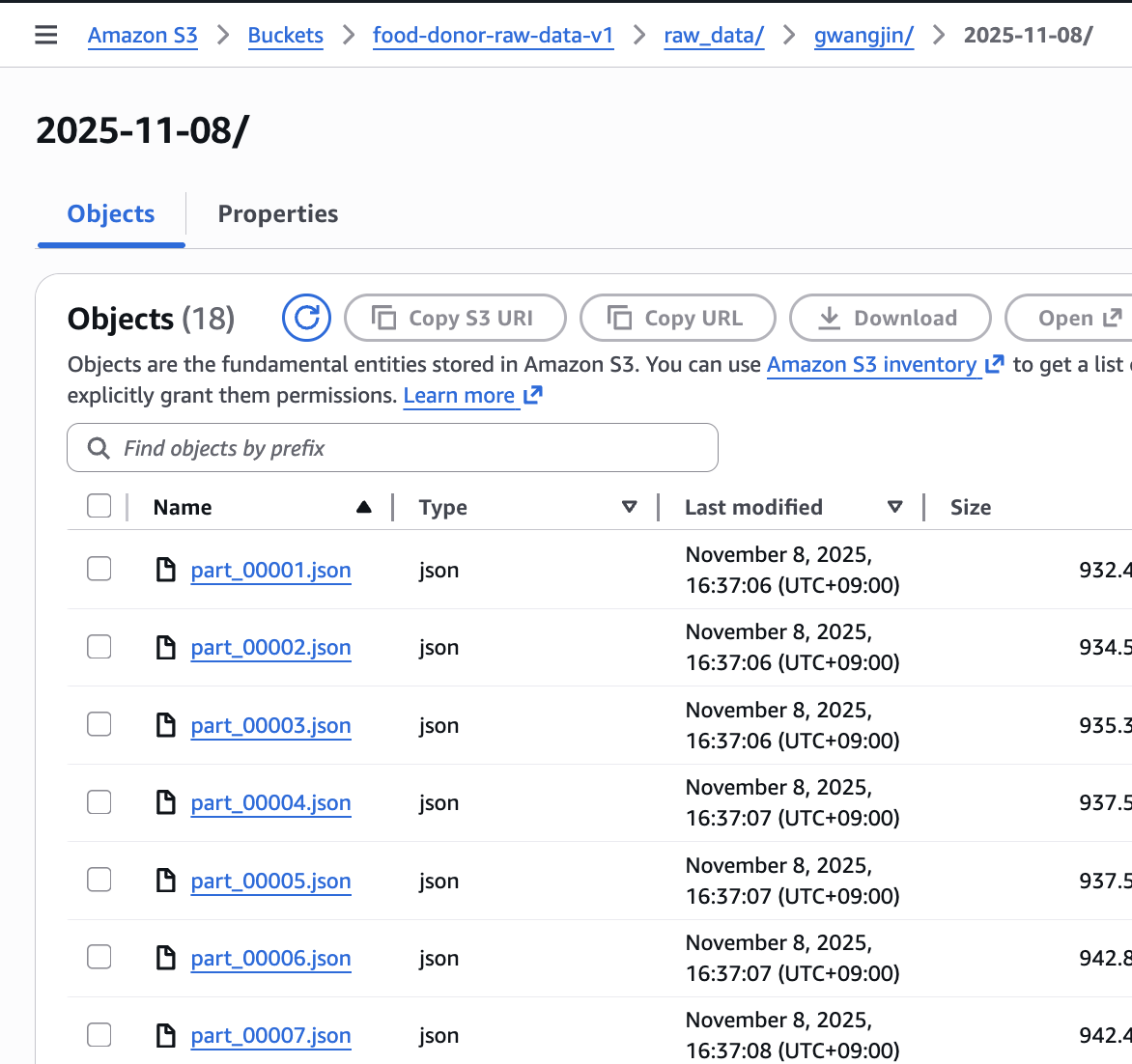
이 방식은 아키텍처의 다음 단계인 AWS Glue 작업에 최적화되어 있다. Glue/Spark는 part_N.json 같은 개별 파일을 읽는 것이 아니라, raw_data/gwangjin/2025-11-09/ 폴더 자체를 입력으로 지정하면 내부의 모든 part 파일들을 하나의 거대한 테이블처럼 자동으로 인식하여 ETL 작업을 수행한다.
7. 결론 및 배운 점
- Runtime.OutOfMemory (메모리 누적): Lambda에서 대용량 데이터를 처리할 때, 데이터를 변수나 배열에 누적(Accumulation)하면 메모리 초과가 발생한다.
- 스트리밍(Streaming) 및 분할 적재: 이를 해결하기 위해 API 응답을 받는 즉시 S3로 '흘려보내는' 스트리밍 기법을 사용했다. 이 과정에서 데이터는 part_N.json 형태의 작은 파일로 S3에 분할 적재된다.
- Unable to calculate hash... (저수준 API 한계): 스트리밍 시 PutObjectCommand (저수준 API)를 사용하면, 스트림의 크기나 해시를 미리 알 수 없어 업로드에 실패한다.
- @aws-sdk/lib-storage (고수준 API): 스트리밍 데이터 업로드는 Upload 클래스 (고수준 API)를 사용하는 것이 정답이다. 이 클래스는 멀티파트 업로드를 자동으로 처리하여, 메모리 효율성과 안정성을 모두 확보하며 '최소 비용' 요건을 달성할 수 있다.
'Troubleshooting > AWS' 카테고리의 다른 글
| [AWS] 스타트업에서 일당 받고 일일 FinOps 해준 후기 - 인프라 비용 87% 감축 기록 (2) | 2026.03.21 |
|---|---|
| [AWS] API Gateway와 Lambda 연동 시 제어권 문제 트러블 슈팅 (프록시 통합) (0) | 2025.11.16 |
| [AWS Athena] S3 Parquet 파티션 빅데이터 쿼리 엔진 설정 (테이블/파티션 인식 불가 트러블 슈팅) (0) | 2025.11.09 |
| [AWS Glue] PySpark: 스트리밍된 분할 JSON을 Parquet +Partitioning기법을 이용해서 칼럼 기반 데이터로 전처리로 전환 (0) | 2025.11.09 |
| [Linux] Swap memory를 이용해서 메모리 부족 해결 (aws ec2) (0) | 2025.01.25 |




댓글