개요

공공데이터포털 API를 호출하여 대용량 데이터를 S3 RAW 영역에 적재하고, AWS Glue를 통해 ETL 작업을 수행하는 배치 파이프라인을 구축 중이었다.
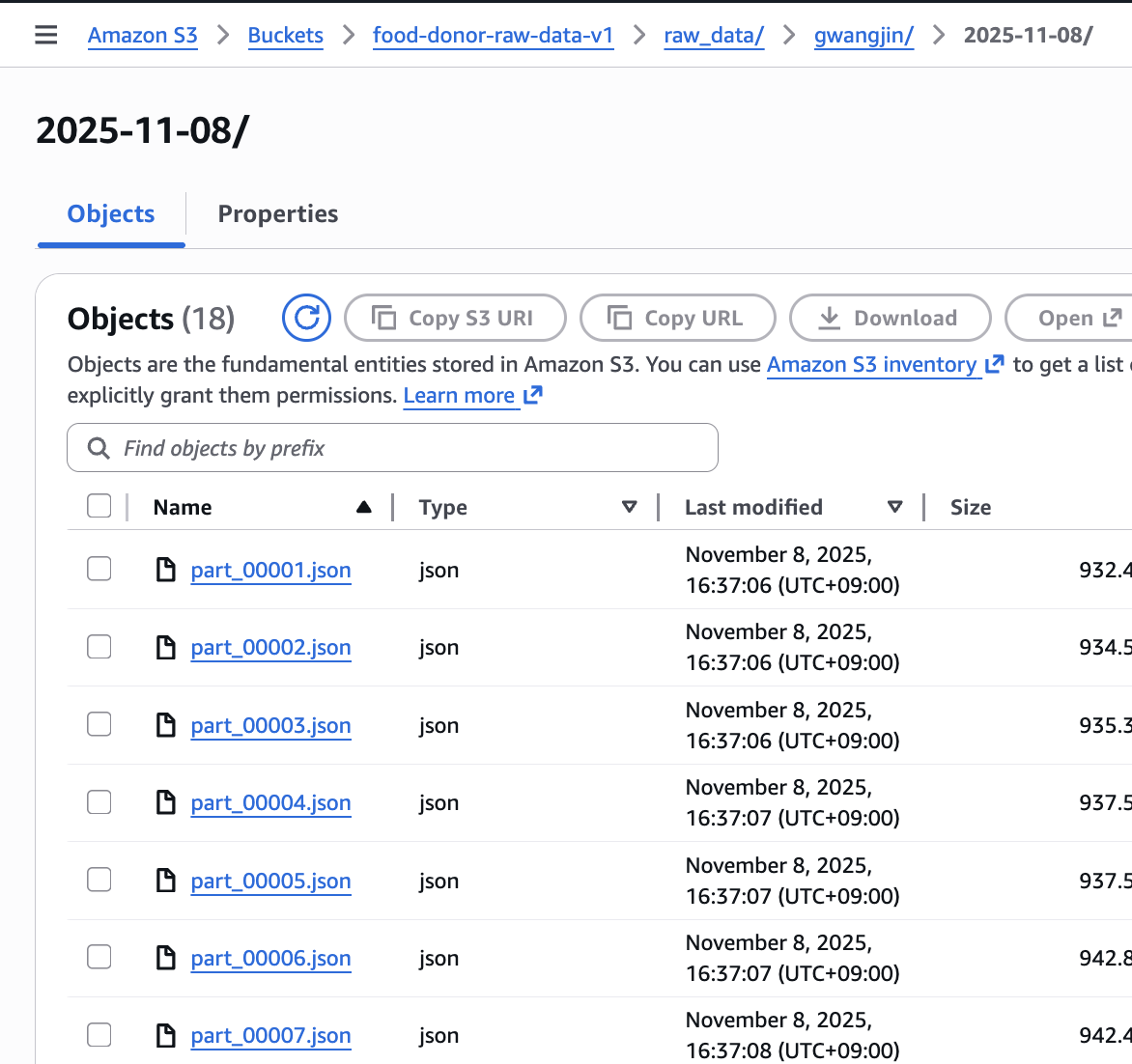
이전 단계(Lambda 스트리밍)로 인해 S3 RAW 버킷에 데이터가 '단일 JSON 파일'이 아닌, part_N.json 형태의 '분할된 파일 폴더'로 적재되기 시작했다. 이로 인해 기존의 '단일 파일'을 읽도록 설계된 AWS Glue Job이 더 이상 작동하지 않게 되었다.
이 글은 이 Glue (PySpark) 스크립트를 수정하는 과정을 다룬다. '폴더' 입력을 처리하고, '동적 JSON 키'를 파싱하며, 나아가 Athena 쿼리 비용 최적화를 위해 Parquet과 파티셔닝(Partitioning)을 적용한 개념과 과정을 설명한다.
1. 단일 파일을 처리하던 Glue Job (pyspark)
이전 아키텍처에서 AWS Glue Job (food-donor-ETL-job-v1)은 S3 RAW 버킷에 적재된 '단일 통 JSON 파일'(예: gwangjin-2025-11-08.json)을 읽어 처리하는 역할을 맡고 있었다.
# 9가지 전처리 로직 적용
# 실제 API 응답 필드명: MGTNO, BPLCNM, DTLSTATENM, RDNPOSTNO, RDNWHLADDR, SITETEL, X, Y, SNTUPTAENM
processed_df = (
df
# 3. 'DTLSTATENM' (상세영업상태명)이 "영업"인 데이터만 필터링
.filter(col("DTLSTATENM") == "영업")
# 1. 컬럼명 변경: 'MGTNO' (관리번호) -> 'id'
.withColumnRenamed("MGTNO", "id")
# 2. 컬럼명 변경: 'BPLCNM' (사업장명) -> 'name'
.withColumnRenamed("BPLCNM", "name")
# 4. 'RDNPOSTNO' (도로명우편번호) -> 'post_number' (결측치 처리)
.withColumn("post_number",
when((col("RDNPOSTNO") == "") | col("RDNPOSTNO").isNull(), "제공안됨")
.otherwise(col("RDNPOSTNO"))
)
# 5. 'RDNWHLADDR' (도로명주소) -> 'address' (결측치 처리)
.withColumn("address",
when((col("RDNWHLADDR") == "") | col("RDNWHLADDR").isNull(), "제공안됨")
.otherwise(col("RDNWHLADDR"))
)
# 6. 'SITETEL' (전화번호) -> 'phone_number' (모든 공백 제거)
.withColumn("phone_number", regexp_replace(col("SITETEL"), "\\s+", ""))
# 7. 'X' (좌표정보 X) -> 'longitude' (공백 제거)
.withColumn("longitude", trim(col("X")))
# 8. 'Y' (좌표정보 Y) -> 'latitude' (공백 제거)
.withColumn("latitude", trim(col("Y")))
# 9. 'SNTUPTAENM' (위생업태명) -> 'type'
.withColumnRenamed("SNTUPTAENM", "type")
)
# 최종적으로 필요한 컬럼만 선택
final_df = processed_df.select(
"id", "name", "post_number", "address",
"phone_number", "longitude", "latitude", "type"
)- 입력: Lambda가 S3 RAW 버킷에 저장한 단일 통 JSON 파일 (예: gwangjin-2025-11-08.json) 1개.
- 처리: 이 단일 파일을 읽어 9가지 전처리 로직(필터링, 컬럼명 변경 등)을 적용했다.
- 출력: S3 Processed 버킷에 단일 처리 결과물을 저장했다.
이 스크립트는 입력이 '파일 1개'라고 가정하고 작성되었기 때문에, glueContext.create_dynamic_frame의 paths 옵션에 특정 파일 경로가 지정되어 있었다.
2. Lambda의 변경으로 입력이 바뀜
하지만, 이전 [Part 4]에서 Lambda의 Runtime.OutOfMemory 문제를 해결하기 위해 스트리밍(Streaming)과 멀티파트 업로드(Multipart Upload)를 도입했다.
이로 인해 S3 RAW 버킷의 데이터 적재 방식이 근본적으로 변경되었다.
- 단일 파일 (X): gwangjin-2025-11-08.json (1GB)
- 다수 분할 파일 (O): .../raw_data/gwangjin/2025-11-08/ 라는 폴더 안에 part_00001.json, part_00002.json, ..., part_00500.json 등 수백 개의 작은 파일로 분할 적재되기 시작했다.
[문제 발생]
- 기존 Glue Job은 이 '폴더'를 읽도록 설계되지 않았다.
- 각 part_N.json 파일은 {"LOCALDATA_XXXXX_00": {"row": [...]}} 와 같이 동적인 루트 키(Root Key)를 가지고 있어, 기존의 정적 스키마로는 데이터를 읽을 수 없게 되었다.
3. 해결 상황 (Solution): PySpark 스크립트 수정 및 최적화
기존 Glue Job을 '폴더' 입력과 '동적 JSON' 구조에 대응하고, 나아가 '최소 비용'을 위한 데이터 형식으로 변환하도록 PySpark 스크립트를 대폭 수정했다.
개념 1: Parquet (파케이) - '최소 비용'의 핵심
데이터를 가공할 때, 단순히 정제만 하는 것이 아니라 분석 비용까지 고려해야 한다.
- JSON/CSV (로우 기반): 데이터를 행(Row) 단위로 저장한다. SELECT name FROM table 쿼리를 실행해도, name 컬럼만 필요함에도 불구하고 모든 행의 모든 컬럼(id, address, phone...)을 다 읽어야 한다.
- Parquet (컬럼 기반): 데이터를 컬럼(Column) 단위로 저장한다. SELECT name FROM table 쿼리를 실행하면, S3에서 정확히 name 컬럼 데이터만 읽는다.
Parquet 포맷은 필요한 컬럼만 읽기 때문에 데이터 스캔량을 획기적으로 줄여주며, 이는 Athena 쿼리 비용 절감에 직결된다. (Athena는 스캔한 데이터 양으로 과금) 또한 압축률이 뛰어나 S3 저장 비용도 절감된다.
개념 2: 파티셔닝 (Partitioning)
파티셔닝은 S3 데이터를 특정 값(예: 날짜, 지역)을 기준으로 폴더를 나눠 저장하는 기법이다.
- 예시: s3://.../partition_date=2025-11-08/district=gwangjin/
- 효과: Athena에서 WHERE district = 'gwangjin' 쿼리를 실행하면, Athena는 다른 'district' 폴더는 스캔조차 하지 않고 gwangjin 폴더만 스캔한다.
Parquet(컬럼)과 파티셔닝(폴더)을 조합하면, Athena가 스캔하는 데이터 양을 최소화하여 쿼리 비용과 성능을 극대화할 수 있다.
Glue Job 설정
Glue Studio에서 '최소 비용'을 위해 Job 설정을 변경했다.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3ListAccess",
"Effect": "Allow",
"Action": "s3:ListBucket",
"Resource": [
"arn:aws:s3:::food-donor-raw-data-v1",
"arn:aws:s3:::food-donor-processed-data-v1"
]
},
{
"Sid": "S3ReadAccessRaw",
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::food-donor-raw-data-v1/*"
]
},
{
"Sid": "S3WriteAccessProcessed",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::food-donor-processed-data-v1/*"
]
}
]
}- IAM Role: S3 Raw(읽기) / Processed(쓰기) 권한을 가진 커스텀 역할(Glue-S3-Access-Role)을 지정했다.
- Worker type: G.1X (표준, 1 DPU)
- Requested number of workers: 2
- [최소 비용 핵심] Glue Spark Job은 최소 2 DPU(G.1X * 2개)가 필요하다. AWS 기본값(5 또는 10) 대신 최소값인 2로 설정하여, 1회 실행 비용을 수백 원 수준으로 낮췄다.
- Job timeout (minutes): 10
- 기본값(8시간)은 스크립트 오류 시 '비용 폭탄'을 유발할 수 있다. 실제 작업 시간(2~3분)을 고려해 10분으로 안전하게 제한했다.
- Job bookmark (북마크): Disable
- 북마크는 '이미 처리한 파일'을 기억하는 기능이다. 우리는 매번 "새로운 날짜의 폴더"를 통째로 처리하므로 이 기능이 불필요했다.
PySpark 스크립트 수정
1. S3 '폴더' 읽기
create_dynamic_frame의 connection_options을 '파일'이 아닌 '폴더' 경로(INPUT_PATH)로 변경했다.
# 2. S3 Raw 데이터 읽기
data_source = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": True},
connection_type="s3",
# '파일'이 아닌 '폴더' 경로를 지정
connection_options={"paths": [INPUT_PATH]},
format="json",
transformation_ctx="data_source"
)2. 동적 JSON 키 파싱 (Explode)
Glue가 읽어온 DataFrame의 컬럼명은 LOCALDATA_072404_GJ 처럼 동적이다. jsonPath를 쓸 수 없으므로, Spark의 explode 함수를 사용해 이 문제를 해결했다.
# 3. 데이터 정제 (Spark/PySpark 로직)
df = data_source.toDF()
# 컬럼명이 동적이므로 첫 번째 컬럼 이름을 찾음
columns = df.columns
first_column = columns[0] # 예: "LOCALDATA_XXXXX_GJ"
# 동적 키 하위의 'row' 배열을 추출하고 펼치기(explode)
df = df.select(explode(col(f"{first_column}.row")).alias("row_data"))
# row_data 구조체를 평탄화 (row_data.MGTNO -> MGTNO)
df = df.select("row_data.*")
# (이후 9가지 전처리 로직 적용...)
processed_df = (
df
.filter(col("DTLSTATENM") == "영업")
.withColumnRenamed("MGTNO", "id")
# ... (기타 8개 로직) ...
)
# 다시 Glue DynamicFrame으로 변환
processed_dyf = DynamicFrame.fromDF(final_df, glueContext, "processed_dyf")3. Parquet 및 파티션 적용 저장
최종 write_dynamic_frame 단계에서 format="parquet"을 지정하고, output_path에 파티션 경로(.../partition_date=.../district=.../)를 동적으로 생성했다.
# 4. S3 Processed 버킷에 Parquet + 파티션으로 저장
output_path = f"s3://{S3_OUTPUT_BUCKET}/partition_date={EXECUTION_DATE}/district={DISTRICT_NAME}/"
glueContext.write_dynamic_frame.from_options(
frame=processed_dyf,
connection_type="s3",
connection_options={"path": output_path},
format="parquet", # Parquet 지정
transformation_ctx="data_sink"
)
4. 최종 결과: 분석에 최적화된 데이터
Glue Job 실행이 성공하고, S3 Processed 버킷(food-donor-processed-data-v1)을 확인했다.


- 경로: partition_date=...와 district=...로 S3 파티션 폴더가 생성되었다.
- 파일: part-....c000.snappy.parquet 형태의 파일이 생성되었다.
- parquet: 데이터가 컬럼 기반으로 저장되었다.
- snappy: Snappy 코덱으로 압축되어 저장 공간을 절약했다.

이 데이터 구조는 AWS Glue Crawler가 자동으로 스키마를 감지하여 Data Catalog에 테이블을 생성할 수 있으며, Amazon Athena는 이 Parquet 파일과 파티션을 즉시 인식하여 최소 비용으로 데이터를 쿼리할 수 있다.
최종 코드
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
# PySpark의 SQL 함수 임포트 (전처리에 필수)
from pyspark.sql.functions import col, when, trim, regexp_replace, lit, explode
# 1. Lambda로부터 Job 인수를 받음
# Lambda에서 전달하는 인자: --S3_INPUT_PATH, --DISTRICT_NAME, --EXECUTION_DATE
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'S3_INPUT_PATH', 'DISTRICT_NAME', 'EXECUTION_DATE'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# --- 설정 ---
S3_OUTPUT_BUCKET = "food-donor-processed-data-v1" # 처리된 데이터가 저장될 버킷
INPUT_PATH = args['S3_INPUT_PATH'] # Lambda가 넘겨준 원본 파일 경로
DISTRICT_NAME = args['DISTRICT_NAME'] # 구 이름 (예: "gwangjin", "nowon")
EXECUTION_DATE = args['EXECUTION_DATE'] # 파티션 생성을 위한 날짜
# =========================================================
# 2. S3 Raw 데이터 읽기
# =========================================================
# S3에 저장된 JSON 파일들을 읽어 Glue DynamicFrame으로 변환
# Lambda에서 저장한 구조: { LOCALDATA_072404_NW: { row: [...] } }
# jsonPath 없이 전체 JSON을 읽고, DataFrame에서 row 배열 추출
data_source = glueContext.create_dynamic_frame.from_options(
format_options={"multiline": True},
connection_type="s3",
connection_options={"paths": [INPUT_PATH]}, # 폴더 경로: 모든 part_*.json 파일 읽기
format="json",
transformation_ctx="data_source"
)
# =========================================================
# 3. 데이터 정제 및 필터링 (Spark/PySpark 로직)
# =========================================================
# DynamicFrame을 Spark DataFrame으로 변환
df = data_source.toDF()
# JSON 구조: { LOCALDATA_072404_NW: { row: [...] } }
# 동적 키(첫 번째 컬럼)를 찾아서 그 안의 row 배열을 추출
# 컬럼명이 동적이므로 첫 번째 컬럼을 사용
columns = df.columns
if len(columns) == 0:
raise ValueError("No columns found in the data")
# 첫 번째 컬럼(동적 키)의 row 배열을 추출
first_column = columns[0]
df = df.select(explode(col(f"{first_column}.row")).alias("row_data"))
# row_data 구조체를 평탄화하여 개별 컬럼으로 변환
df = df.select("row_data.*")
# 9가지 전처리 로직 적용
# 실제 API 응답 필드명: MGTNO, BPLCNM, DTLSTATENM, RDNPOSTNO, RDNWHLADDR, SITETEL, X, Y, SNTUPTAENM
processed_df = (
df
# 3. 'DTLSTATENM' (상세영업상태명)이 "영업"인 데이터만 필터링
.filter(col("DTLSTATENM") == "영업")
# 1. 컬럼명 변경: 'MGTNO' (관리번호) -> 'id'
.withColumnRenamed("MGTNO", "id")
# 2. 컬럼명 변경: 'BPLCNM' (사업장명) -> 'name'
.withColumnRenamed("BPLCNM", "name")
# 4. 'RDNPOSTNO' (도로명우편번호) -> 'post_number' (결측치 처리)
.withColumn("post_number",
when((col("RDNPOSTNO") == "") | col("RDNPOSTNO").isNull(), "제공안됨")
.otherwise(col("RDNPOSTNO"))
)
# 5. 'RDNWHLADDR' (도로명주소) -> 'address' (결측치 처리)
.withColumn("address",
when((col("RDNWHLADDR") == "") | col("RDNWHLADDR").isNull(), "제공안됨")
.otherwise(col("RDNWHLADDR"))
)
# 6. 'SITETEL' (전화번호) -> 'phone_number' (모든 공백 제거)
.withColumn("phone_number", regexp_replace(col("SITETEL"), "\\s+", ""))
# 7. 'X' (좌표정보 X) -> 'longitude' (공백 제거)
.withColumn("longitude", trim(col("X")))
# 8. 'Y' (좌표정보 Y) -> 'latitude' (공백 제거)
.withColumn("latitude", trim(col("Y")))
# 9. 'SNTUPTAENM' (위생업태명) -> 'type'
.withColumnRenamed("SNTUPTAENM", "type")
)
# 최종적으로 필요한 컬럼만 선택
final_df = processed_df.select(
"id", "name", "post_number", "address",
"phone_number", "longitude", "latitude", "type"
)
# 다시 Glue DynamicFrame으로 변환
processed_dyf = DynamicFrame.fromDF(final_df, glueContext, "processed_dyf")
# =========================================================
# 4. S3 Processed 버킷에 결과 저장
# =========================================================
# Athena 쿼리 성능과 비용 절감을 위해 Parquet 형식으로, 날짜와 구 이름 파티션을 생성하여 저장
# 파티션 구조: partition_date=2025-01-15/district=gwangjin/
output_path = f"s3://{S3_OUTPUT_BUCKET}/partition_date={EXECUTION_DATE}/district={DISTRICT_NAME}/"
glueContext.write_dynamic_frame.from_options(
frame=processed_dyf,
connection_type="s3",
connection_options={"path": output_path},
format="parquet", # Parquet은 Athena 쿼리 비용을 크게 절감시킵니다.
transformation_ctx="data_sink"
)
job.commit()5. 결론 및 배운 점
- Glue '폴더' 입력: glueContext.create_dynamic_frame의 paths 옵션은 단일 파일뿐만 아니라 폴더 경로를 지정할 수 있다. Glue/Spark는 해당 폴더 내의 모든 파일(예: part_N.json)을 자동으로 병합하여 단일 프레임으로 읽어들인다.
- 동적 JSON 파싱 (Explode): jsonPath로 스키마를 지정하기 어려운 동적 키 구조(예: {"LOCALDATA...": ...})는, toDF()로 Spark DataFrame 변환 후, 첫 번째 컬럼(columns[0])을 동적으로 찾아 explode 함수를 적용하여 'row' 배열을 효과적으로 평탄화(Flatten)할 수 있다.
- Parquet (컬럼 기반) 저장: Athena 쿼리 비용은 '스캔한 데이터 양'에 비례한다. JSON (로우 기반) 대신 Parquet (컬럼 기반) 포맷으로 저장하면, 쿼리에 필요한 컬럼만 읽어 스캔량을 최소화하고 비용을 획기적으로 절감할 수 있다.
- 파티셔닝 (Partitioning): write_dynamic_frame의 path에 partition_date=.../district=.../ 와 같은 'Key=Value' 형태의 폴더 구조를 지정하면 데이터가 파티셔닝된다. Athena는 WHERE 절의 파티션 키를 사용해 불필요한 폴더/파일 스캔을 아예 건너뛰어(Pruning) 비용과 속도를 최적화한다.
- Glue Job 비용 최적화: Spark Job은 최소 2 DPU (G.1X, 2 workers)로 실행 가능하다. 기본값(5~10 DPU)을 그대로 사용하지 않고 최소한으로 설정하며, Job timeout을 짧게(예: 10분) 설정하여 스크립트 오류로 인한 '비용 폭탄'을 방지해야 한다.
'Troubleshooting > AWS' 카테고리의 다른 글
| [AWS] API Gateway와 Lambda 연동 시 제어권 문제 트러블 슈팅 (프록시 통합) (0) | 2025.11.16 |
|---|---|
| [AWS Athena] S3 Parquet 파티션 빅데이터 쿼리 엔진 설정 (테이블/파티션 인식 불가 트러블 슈팅) (0) | 2025.11.09 |
| [AWS Lambda] 빅데이터 배치 처리 파이프라인 구축 도중 Runtime.OutOfMemory 발생하여 Streaming + Chunk 기법 적용 (0) | 2025.11.09 |
| [Linux] Swap memory를 이용해서 메모리 부족 해결 (aws ec2) (0) | 2025.01.25 |




댓글