https://oliveyoung.tech/2023-10-02/c10-problem/
고전 돌아보기, C10K 문제 (C10K Problem) | 올리브영 테크블로그
오래된 과거에서 시작하는 Node.js의 비동기 처리로의 여정
oliveyoung.tech
자세한 I/O Multiplexing과 epoll과 시스템 콜 관련한 내용은 다음 포스트에서 다루고, 이번 포스트에서는 기본 아키텍처와 프로세스 모델을 통한 컨텍스트 스위칭 오버헤드 개선에 대해서 다루겠다.
Nginx가 Non-blocking I/O Multiplexing과 epoll 시스템 콜 이용해서 대용량 처리하는 원리
https://ego2-1.tistory.com/27 C10K 문제로 살펴보는 서버 아키텍처와 커널 I/O의 진화개요 C10K 문제란, 단일 서버가 동시에 10,000명(Concurrent 10K connections) 이상의 클라이언트와 연결을 유지하며 통신할 수
konkukcodekat.tistory.com
C10K Problem이란?
단일 서버가 동시에 10,000명 이상의 클라이언트와 연결을 유지하며 통신할 수 있도록 네트워크 소켓 처리 성능을 최적화하는 문제를 말한다.
Apache(Legacy) vs Nginx(Modern) 비교
| 항목 | Apache (Legacy) | Nginx (Modern) |
| 모델 | Thread/Process based | Event-Driven & Asynchronous |
| I/O 처리 | Blocking I/O (기다림) | Non-blocking I/O (안 기다림) |
| 연결 방식 | 1 Connection = 1 Thread | 1 Worker = N Connections (Multiplexing) |
| 메모리 | 접속자 수에 비례해 폭증 (무거움) | 접속자 늘어도 거의 일정 (가벼움) |
| CPU 효율 | Context Switching 비용 높음 | Context Switching 최소화 (CPU 100% 활용) |
| 핵심 기술 | select / poll (O(n)) | epoll / kqueue (O(1)) |
1. Apache의 방식: Blocking I/O & Thread/Process Model
당시 표준이었던 Apache(MPM Prefork/Worker)의 방식이 너무 무거워서 발생한 문제이다.
Apache는 "손님(요청) 한 명당 직원(스레드/프로세스) 한 명을 붙이는 방식"이다.
- Connection 1:1 매핑: 클라이언트가 접속하면 OS는 스레드를 하나 생성한다. 1만 명이 접속하면 스레드 1만 개가 생긴다.
- 메모리 폭발: 스레드 하나당 스택 메모리가 약 1~2MB 필요하다.
- 10,000 Threads * 2MB = 20GB RAM.
- 당시 RAM은 2GB였다. 메모리 부족(OOM)으로 서버가 죽는다.
- Context Switching 지옥: CPU 코어는 1~4개뿐인데, 운영체제는 1만 개의 스레드를 공평하게 실행시키려고 계속 전환(Switching)한다.
- CPU가 실제 일하는 시간보다 "작업 전환하는 시간(Overhead)"이 더 커진다.
- Blocking I/O: 스레드는 DB 조회나 파일 읽기가 끝날 때까지 아무것도 안 하고 멈춰(Block) 있다.
2. Nginx의 해결책: Event-Driven & Asynchronous Non-blocking
구조: Fixed Number of Workers
- Nginx는 접속자가 늘어난다고 프로세스를 더 만들지 않는다.
- 보통 CPU 코어 개수만큼만 Worker Process를 생성한다. (예: 4코어 = 4 워커)
- 효과: 스레드를 만들고 없애는 비용이 없다. CPU 코어 개수와 딱 맞으니 Context Switching이 거의 발생하지 않는다.
핵심 기술: Multiplexing & Event Loop
- 워커는 계속 루프(for (;;))를 돈다.
- 모든 소켓은 Non-blocking이다. "데이터 왔어?" 물어보고 없으면 기다리지 않고 바로 다음 소켓을 확인한다.
- Epoll 시스템 콜: 수천 개의 소켓(FD)을 일일이 확인하면 느리니까(O(n)), 리눅스 커널의 epoll에게 이벤트 트리거된 소켓의 FD를 알려달라고 시킨다(O(1)).
- 워커 프로세스 하나가 수천 개의 Connection을 혼자 관리한다.
- Nginx는 워커 수는 고정하고, 한 명이 수만 명을 비동기로 처리하는 아이디어로 접근했다.
3. Apache vs Nginx 구조
Nginx 프로세스 구조
- Nginx는 실행되면 딱 하나의 Master와 여러 개의 Worker로 나뉜다. 이들은 철저한 상명하복 관계다.
Master Process (관리자)
- 권한: root 권한으로 실행 (80번 포트 바인딩 때문).
- 하는 일: 설정 파일(nginx.conf) 읽기 및 검증, 소켓 열기 (Bind/Listen), Worker 생성(fork), 관리, 종료 신호 전달.
- 중요: 실제 클라이언트 요청 처리는 하지 않는다. 관리만 한다.
Worker Process (일꾼)
- 권한: nginx 또는 www-data 같은 최소 권한 계정으로 실행 (보안상 중요).
- 하는 일: Master가 열어준 소켓을 물려받아 실제 통신 수행. 디스크 I/O, 업스트림 통신, 필터링 등 모든 일을 한다.
- 개수: 보통 auto로 설정하며, CPU 코어 수만큼 생성한다.
4코어 CPU인 내 라즈베리파이(리눅스 OS)에서 실행시키면 자동으로 워커 프로세스가 4개 생성된 것을 볼 수 있다.
자식 프로세스를 한번 kill 해보면

아래와 같이 바로 새 자식 프로세스가 정해진 숫자에 맞춰서 생성되는걸 알 수 있다.

4. 왜 Thread가 아니라 Process인가
"스레드가 프로세스보다 생성 비용도 싸고, 메모리 공유도 돼서 빠르지 않나?" 맞지만, Nginx 개발자(Igor Sysoev)는 속도보다 더 중요한 가치를 위해 프로세스를 선택했다.
(1) 격리와 안정성
- Thread 모델(예: Tomcat, Apache Worker MPM): 모든 스레드가 하나의 메모리 공간(Heap)을 공유한다.
- 만약 스레드 A가 코딩 실수로 잘못된 메모리를 건드려 Segmentation Fault를 일으키면 프로세스 전체가 죽는다. 스레드 B, C, D도 함께 사망한다.
- Nginx Process 모델: 워커들은 완전히 분리되어 있다. 메모리 공간이 독립적이다.
- 워커 1번이 에러로 터져 죽어도, 워커 2, 3, 4번은 멀쩡하다.
- Master는 워커 1번이 죽은 걸 감지하고(SIGCHLD), 즉시 새로운 워커를 채워 넣는다.
(2) Lock-Free (동기화 비용 제거)
- Thread: 공유 자원(변수 등)에 접근할 때 Mutex/Semaphore(락)를 걸어야 한다.
- 스레드가 많아지면 "락 걸고 푸는 시간(Lock Contention)" 때문에 CPU를 낭비한다.
- Process: 공유하는 게 없으니 락을 걸 필요가 거의 없다. 자기 할 일만 한다.
(3) Hot Reload (무중단 설정 변경)
- 프로세스 모델이기 때문에 가능한 기능이다.
- 설정을 바꾸거나 바이너리를 업데이트할 때, 기존 워커는 Graceful Shutdown하고, 새 워커는 지금부터 들어오는 요청을 받으라고 명령할 수 있다.
- 이 교체 과정에서 단 1개의 연결도 끊기지 않는다.
전역변수를 안써도 스레드간 공유가 일어나는 이유
가장 큰 병목은 개발자 변수보다 malloc과 free 그 자체이다.
스레드 1만 개가 동시에 요청을 처리하려면 각각 request 객체와 버퍼를 잡아야 하니 malloc()을 호출한다.
프로세스 내의 Heap 메모리 공간은 하나이다.
만약 스레드 A가 메모리를 자르는 도중에 스레드 B가 끼어들면 메모리 족보(Linked List)가 꼬여서 프로그램이 터진다.
그래서 OS의 메모리 할당자(glibc malloc 등)는 내부적으로 강력한 락(Mutex)을 건다.
락을 안 걸었지만, malloc을 호출하는 순간 1만 개의 스레드가 줄을 선다. CPU는 실제 일하는 시간보다 "메모리 줄 세우기"에 시간을 쓴다.
Nginx는 워커 프로세스끼리는 메모리가 완전히 분리되어 있다. 각자 자기 힙에서 malloc 하니 줄을 서지 않는다. (Lock-Free)
5. 숨겨진 공유 자원
1) CPU 캐시 (False Sharing)
이건 락도 안 걸었는데 느려지는, 아주 악질적인 하드웨어 문제다.
스레드 A는 counter_A 변수를 고치고, 스레드 B는 counter_B를 고친다.
두 변수는 서로 다른데, 우연히 메모리 주소가 가깝게 붙어 있다고 하자.
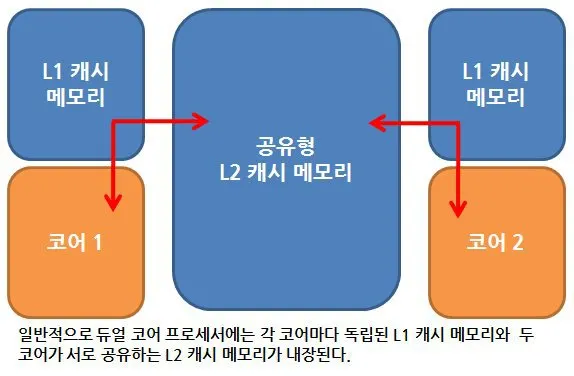
CPU 캐시(L1/L2)는 데이터를 블록 단위(Cache Line, 보통 64바이트)로 가져온다.
counter_A와 counter_B가 같은 캐시 라인에 로딩되면, 한 쪽이 바꾸면 다른 쪽의 캐시 라인은 "무효(Invalid)" 처리가 된다.
코어 2는 다시 RAM에서 데이터를 읽어와야 한다.
스레드가 많을수록 서로 캐시를 무효화시키는 "캐시 핑퐁(Cache Ping-Pong)"이 발생해 CPU 성능이 급락한다.
Nginx는 프로세스 단위로 돌아가기 때문에 메모리 주소가 멀리 떨어져 있고, 각자 전용 코어(Core Affinity)를 쓰기 때문에 캐시 간섭이 거의 없다.
2) 커널 자료구조 (FD Table)
- 리눅스에서 스레드(LWP)는 files_struct(파일 디스크립터 테이블)를 공유한다.
- 새로운 연결이 들어와서 소켓 FD를 생성하거나 닫을 때(open/close), 커널 내부에서 FD 테이블에 락(Spinlock)을 건다.
- 1만 개의 스레드가 동시에 접속하고 끊고를 반복하면 커널 레벨의 병목이 생긴다.
3) 스택 메모리 폭발
- 공유 문제는 둘째 치고, 메모리 용량 자체가 문제다.
- 스레드는 생성될 때마다 각자의 작업 공간인 스택(Stack)을 할당받는다.
- 리눅스 기본 스택 사이즈: 약 2MB ~ 8MB.
- 계산: 접속자 1만 명(10K) × 2MB = 20GB RAM 필요 (서버 램 2GB 시절엔 불가능).
- Nginx(이벤트 기반)는 접속자 하나당 스레드를 안 만든다. 그냥 힙 메모리에 작은 connection 구조체(약 1~4KB) 하나만 만든다.
- 계산: 1만 명 × 2KB = 20MB RAM 필요.
Nginx의 해결 아키텍처
"개발자가 로직상 공유할 데이터를 안 만들면 되는 거 아니냐?" 할 수 있지만, 시스템(OS, Allocator, Hardware)이 기본적으로 공유를 강제하는 부분들이 있다.
- Memory Allocator Lock: malloc 줄 서다가 시간 다 감.
- False Sharing: CPU 캐시끼리 싸우다가 성능 저하.
- Context Switching: 1만 개 스레드 교체 비용.
Nginx의 프로세스 모델은 이 모든 공유 문제를 원천 차단했다. "Share Nothing Architecture"(아무것도 공유하지 않는다). 이것이 Nginx가 하드웨어 스펙을 극한으로 뽑아내며 C10K를 정복한 비결이다.
6. Blocking vs Non-blocking / Sync vs Async
- Blocking vs Non-blocking: 기다릴 것인가, 딴 일을 할 것인가?
- Sync vs Async: 완료 여부를 누가 챙길 것인가?
Blocking I/O (구형 Apache)
- read()를 호출하면 데이터가 다 도착해서 유저 메모리로 복사될 때까지 프로세스가 잠든다(Sleep).
- 기다리는 동안 CPU는 놀고 있다. 그래서 Apache는 스레드를 수천 개 만들어야 했다.
Non-blocking I/O (Busy Wait)
- 소켓을 O_NONBLOCK으로 만든다. read()를 호출했을 때 데이터가 없으면 즉시 1(EAGAIN)을 리턴한다.
- 프로세스는 안 멈추지만, 데이터가 왔는지 확인하려고 계속 read를 호출하는 무한 루프(Polling)를 돈다. CPU를 100% 낭비한다. 실무에선 절대 단독으로 안 쓴다.
Synchronous Non-blocking I/O Multiplexing (Nginx의 핵심)
- Nginx는 모든 연결 소켓을 Non-blocking으로 만든다 (accept4(..., SOCK_NONBLOCK)).
- 워커는 절대 I/O 때문에 멈추지 않는다.
- Blocking은 어디서? (epoll_wait):
- Nginx도 Blocking을 한다. 단, read 하느라 기다리는 게 아니라 "이벤트가 오길" 기다리는 것이다.
- epoll_wait 함수 자체가 Blocking이다. 하지만 여기서 기다리는 건 "1만 개의 소켓 중 하나라도 신호가 오나?"를 감시하는 거라 효율적이다.
- epoll이 데이터 준비된것을 이벤트 트리거하면, 데이터를 읽는 작업(read)은 Nginx 워커가 직접(Sync) 해야 한다.
- 데이터를 kernel space 에서 user space 으로 복사하는 그 찰나의 순간에는 CPU를 쓴다.
7. Context Switching : 프로세스 전환 비용에 대한 분석
- Context Switching: CPU가 A 작업을 하다가 B 작업으로 넘어갈 때, 현재 상태를 저장하고 불러오는 비용
- Apache vs Nginx
- Apache: 접속자 수만큼 스레드를 만듦 → 스레드 간 컨텍스트 스위칭 비용이 증가
- Nginx: CPU 코어 수만큼만 워커를 만듦 → 컨텍스트 스위칭 최소화
1. Context Switching 오버헤드
OS가 프로세스 A에서 프로세스 B로 전환할 때, 사용자 눈에는 "잠깐 멈춤"이지만 하드웨어 레벨에서는 Flush와 Reload 일어남.
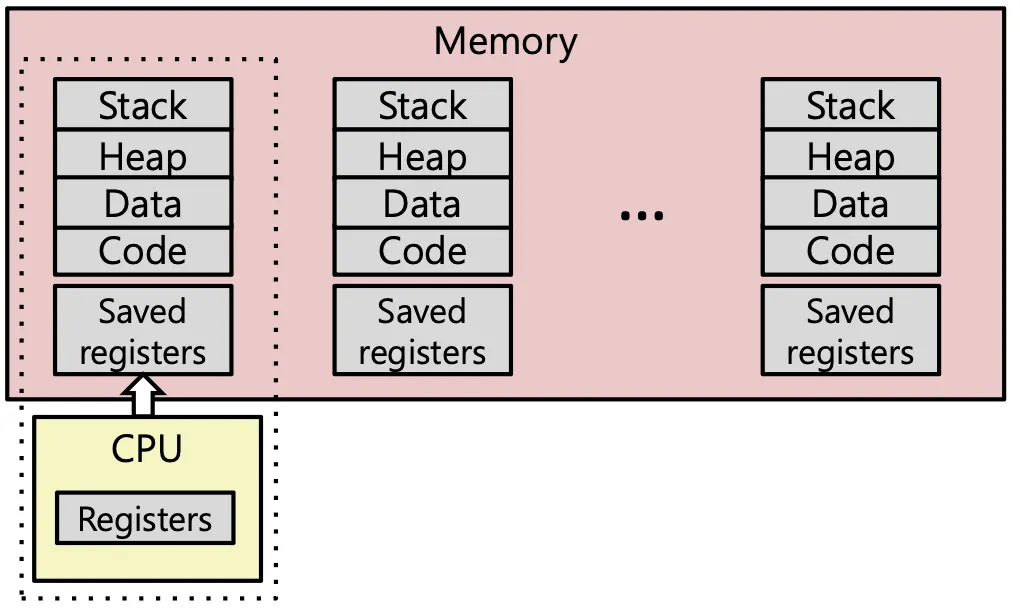
| Direct Cost | 레지스터(PC, SP 등) 저장 및 복구 | Very Low (수 ns) |
| Indirect Cost 1 | Cache Pollution (L1/L2/L3) | High (수백 ns ~ 수 ms) |
| Indirect Cost 2 | TLB Flush & Page Walk | Critical (심각한 Latency) |
2. CPU Cache Pollution (캐시 오염)
상황: Apache (Thread-based)
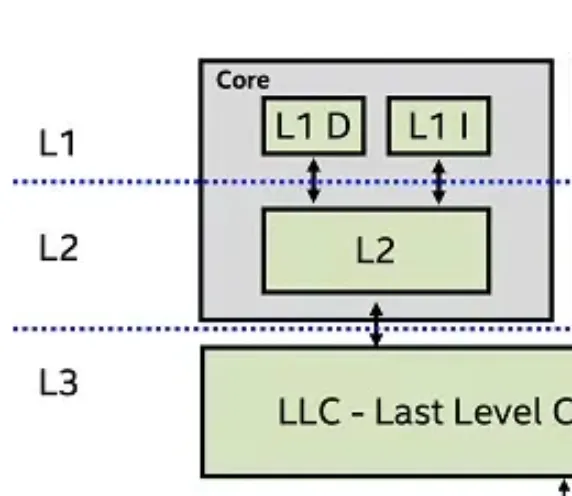
스레드 1만 개가 돌면, OS 스케줄러는 짧은 시간(Time Slice)마다 실행할 스레드를 교체함.
- L1 Instruction Cache (명령어 캐시)
- 스레드 A가 실행하던 코드(함수)가 L1-I에 올라와 있음
- 스레드 B로 전환되는 순간, 스레드 B가 실행할 코드를 다시 RAM에서 가져와야 함
- 결과: 스레드 A가 다시 돌아왔을 때, 자신의 코드는 이미 밀려나고 없음 (Cache Miss)
- L1 Data Cache (데이터 캐시)
- 스레드 A가 다루던 데이터(변수)가 캐시에 따끈따끈하게(Hot) 데워져 있음
- 스레드 B가 들어와서 자신의 데이터를 로딩하며 캐시 라인을 덮어씀
- 결과: Cache Thrashing (캐시 핑퐁) 발생
Nginx의 해결책: "Hot Cache 유지"
Nginx 워커는 context switching을 하지 않고 하나의 루프(for(;;))만 미친 듯이 돈다.
- Instruction Locality: epoll_wait, http_parser 같은 핵심 코드들이 L1-I Cache에 상주한다.
- Data Locality: epoll 이벤트 배열 같은 핵심 자료구조가 L1-D Cache에 계속 남아 있음
- 효과: 메모리(RAM)까지 안 가고 CPU 내부에서 모든 처리가 끝남
3. TLB Flush & Page Walk
Virtual Address → Physical Address 변환을 빠르게 하려고 TLB(Translation Lookaside Buffer)라는 캐시 사용

상황: Apache (Process/Prefork 방식)
프로세스 A에서 프로세스 B로 넘어가면, 가상 주소 공간(Address Space) 자체가 바뀜
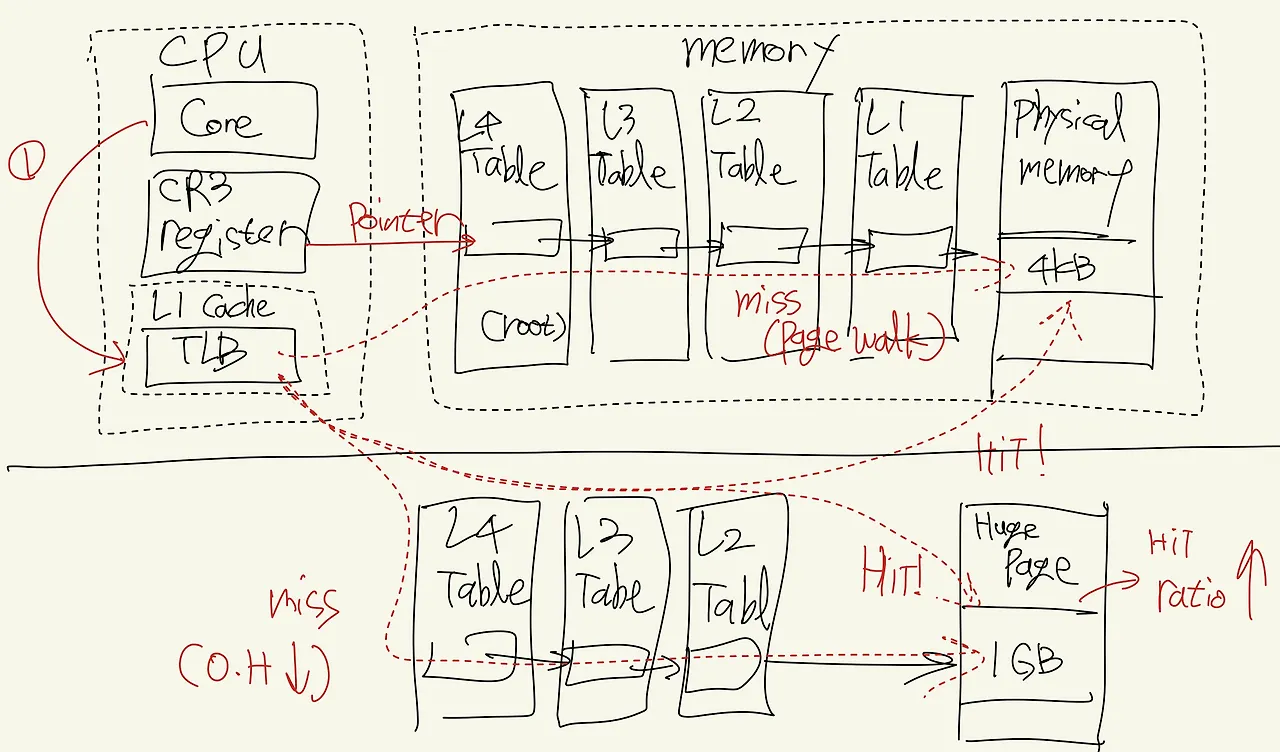
- CR3 레지스터 교체: x86 CPU는 페이지 테이블의 시작 주소를 CR3 레지스터에 담는다. 프로세스가 바뀌면 이 값이 바뀜
- TLB Flush (초기화)
- 주소 체계 변경 → 기존 TLB 데이터는 쓰레기
- CPU는 TLB를 싹 비움(Flush) (PCID 기능이 있지만, 미스율은 높아짐)
- Page Walk (지옥의 산책)
- TLB가 비어 있으니, 다음 메모리 접근 시 Page Walk 발생
- CPU는 실제 물리 메모리의 Page Table(4-level paging)을 하나하나 뒤짐
- 메모리 액세스가 최소 4~5배 느려짐
Nginx의 해결책: "Single Address Space"
Nginx는 하나의 워커 프로세스 안에서 수만 개의 요청을 처리함
- No CR3 Change: 다른 요청을 처리해도 프로세스가 바뀌지 않음
- TLB Hit: 방금 처리한 요청의 메모리 주소 변환 정보가 TLB에 살아있을 확률이 높음
- No Page Walk: 비싼 페이지 테이블 탐색 비용이 0에 수렴
Nginx worker_cpu_affinity
Nginx 설정의 worker_cpu_affinity 는 캐시와 TLB 효율을 극대화하는 핵심 설정이다.
# nginx.conf
worker_processes 4;
# 각 워커를 0번, 1번, 2번, 3번 코어에 강제로 고정(Pinning)함
worker_cpu_affinity 0001 0010 0100 1000;
OS 스케줄러가 멍청하게 워커 1번을 Core 0에서 돌리다가 Core 1로 옮기면 어떻게 될까?
- Core 0의 L1/L2 Cache: 워커 1번 데이터는 다 날아감
- Core 1의 L1/L2 Cache: 워커 1번 데이터는 없음 (Cold Cache)
Nginx는 프로세스마다 코어를 고정 시켜서 Cache Warm-up 상태를 영구히 유지함.




댓글