https://zcbm7008.tistory.com/6
LINUX 커널 네트워크 수신 프로세스
이 글은 Netty 이야기: 커널 관점에서 본 I/O 모델 을 바탕으로 제기 이해하고 부족한 점을 찾아 정리한 글입니다. 아마존 프리 티어에서 작은 개인 프로젝트를 테스트 하면서, 내 프로젝트가 생각
zcbm7008.tistory.com
https://d2.naver.com/helloworld/47667
이번 글에서는 리눅스 커널의 System Call 트레이싱 도구인 strace를 사용하여 실제 런타임에 발생하는 커널 이벤트를 추적하고, 특히 User Space와 Kernel Space 간의 데이터 이동 비용 관점에서 Nginx의 최적화 기법을 심층 분석한다.
리눅스 커널의 네트워크 패킷 처리 과정
Hardware Layer: NIC와 DMA

네트워크 패킷이 랜선을 타고 서버의 NIC에 도달하면, 가장 먼저 하드웨어 레벨의 처리가 시작된다.
DMA (Direct Memory Access)

과거에는 CPU가 모든 I/O 요청을 직접 처리(PIO)했으나, 이는 효율이 매우 떨어졌다. 현대 시스템에서는 DMA가 CPU 대신 NIC의 데이터를 메모리(RAM)로 복사한다. CPU는 전송이 완료되었다는 신호만 받으면 되므로 그동안 다른 작업을 수행할 수 있다.
Ring Buffer
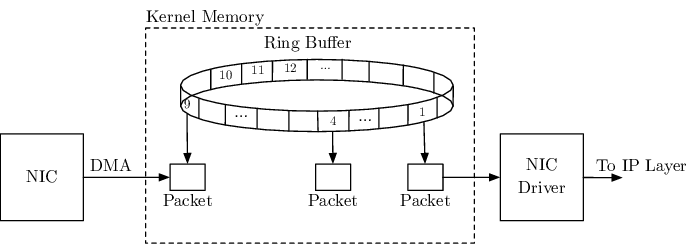
NIC는 수신한 패킷을 DMA를 통해 미리 할당된 커널 메모리 영역인 Ring Buffer에 적재한다. 만약 트래픽이 폭주하여 Ring Buffer가 가득 차게 되면, 이후 들어오는 패킷은 가차 없이 드랍(Drop)된다.
3. Kernel Layer: 인터럽트와 프로토콜 스택


DMA 전송이 완료되면, NIC는 CPU에게 "데이터가 왔다"고 알린다. 이때 두 단계의 인터럽트 처리가 발생한다.
(1) Hard IRQ (하드웨어 인터럽트)
CPU는 하던 일을 멈추고 인터럽트를 처리해야 한다. 하지만 네트워크 패킷 처리는 복잡하고 시간이 오래 걸리는 작업이다. 모든 패킷을 하드 인터럽트 컨텍스트에서 처리한다면, CPU는 키보드나 마우스 입력조차 받지 못하고 멈춰버릴 것이다.
따라서 커널은 최소한의 작업(데이터 수신 확인)만 수행하고, 실제 패킷 처리는 Soft IRQ로 미룬 뒤 즉시 제어권을 반환한다.
(2) Soft IRQ (소프트웨어 인터럽트)와 ksoftirqd

이제 커널 스레드인 ksoftirqd가 바통을 이어받는다. 이 단계에서 실제 프로토콜 처리가 이루어진다.
- sk_buff (Socket Buffer): 리눅스 커널은 패킷을 sk_buff라는 구조체로 관리한다. 이는 데이터 복사를 최소화하기 위해 포인터 조작만으로 계층 간 이동이 가능하도록 설계된 연결 리스트다.
- Protocol Stack (TCP/IP): sk_buff는 ip_rcv (L3, 라우팅 결정) → tcp_rcv (L4, 포트 식별) 함수를 거치며 헤더가 벗겨진다. 커널은 4-Tuple(출발지 IP/Port, 목적지 IP/Port)을 확인하여 해당 패킷을 소유한 소켓을 찾고, Recv Buffer에 데이터를 복사해 넣는다.
5가지 오버헤드

- DMA 오버헤드: NIC에서 커널 메모리로 패킷을 복사하는 비용.
- Hard IRQ 오버헤드: CPU가 하던 일을 멈추고 인터럽트에 응답하는 비용.
- Soft IRQ (ksoftirqd) 오버헤드: 실제 패킷을 파싱하고 프로토콜 스택을 태우는 비용.
- Copy 오버헤드 (핵심): 커널 공간의 데이터를 유저 공간으로 복사하는 CPU 비용.
- Context Switching: read() 호출 시 User Mode ↔ Kernel Mode를 오가는 비용.
Nginx와 같은 고성능 서버는 바로 이 4번과 5번, 즉 '복사 비용'과 '컨텍스트 스위칭'을 극한으로 줄이기 위해 탄생했다.
1. strace 실행
nginx는 유저 프로세스가 여러개 이다 보니까 한 프로세스를 strace하면 시스템 콜 로그를 캡처하기 곤란해서 모든 워커 프로세스를 감시하는 상태에서 HTTP 요청을 보내보았다.

실제 트래픽을 처리하는 Worker Process의 PID를 식별하여 strace를 부착(Attach)하고 HTTP 요청을 전송했을 때 포착된 로그는 다음과 같다.

2. System Call 상세 분석
PDF 자료의 순서에 따라 각 System Call의 역할과 커널 내부 동작을 분석한다.
- epoll_pwait: Nginx의 Event Loop가 대기하는 상태다. 이 함수는 커널에게 제어권을 넘기고, 등록된 FD(File Descriptor)에서 이벤트가 발생할 때까지 프로세스를 Sleep 상태로 전환하여 CPU 자원 소모를 방지한다.
- accept4: 클라이언트의 연결 요청(SYN)을 수락하고 새로운 소켓 FD(13번)를 생성한다. 여기서 SOCK_NONBLOCK 플래그가 사용된 점에 주목해야 한다. 이는 해당 소켓에서의 I/O 작업이 완료되지 않아도 즉시 리턴하게 하여, 단일 프로세스가 블로킹 없이 다중 연결을 처리할 수 있게 한다.
- epoll_ctl: 생성된 소켓(FD 13)을 epoll 인스턴스(FD 10)의 관심 목록(Interest List)에 등록한다. EPOLLET 플래그를 사용하여 Edge Triggered 모드로 동작하도록 설정했다.
- recvfrom: FD 13번 소켓의 수신 버퍼(Receive Buffer)로부터 HTTP 요청 데이터를 User Space 메모리로 읽어 들인다.
- writev: Response Header와 같은 메타데이터를 전송한다. 일반 write가 아닌 writev(Vector I/O)를 사용하여, 메모리에 산재된 여러 버퍼(iov_base)를 단일 System Call로 처리함으로써 Context Switching 오버헤드를 줄인다.
- sendfile: (핵심) 디스크 상의 파일(FD 14) 데이터를 소켓(FD 13)으로 전송한다. 이 지점에서 User Space와 Kernel Space 간의 데이터 이동 방식에 대한 심층적인 이해가 필요하다.
3. Event-Driven 아키텍처와 비동기 I/O의 작동 메커니즘
위 strace 로그는 단순한 System Call의 나열이 아니다. Nginx가 I/O Multiplexing을 통해 단일 프로세스로 수만 개의 연결을 처리하는 Event Loop의 사이클을 적나라하게 보여준다. 이 메커니즘의 핵심은 세 가지로 요약된다.
(1) epoll_wait 중심의 FSM (Finite State Machine)
Nginx Worker Process는 본질적으로 무한 루프를 도는 FSM이다.
로그에서 계속 반복되는 epoll_pwait가 바로 이 루프의 시작점이자 끝점이다.
Blocking 포인트의 단일화
Apache 같은 전통적인 Blocking 모델은 read()나 write()를 호출했을 때 데이터가 없으면 OS가 프로세스를 강제로 재워버린다(Sleep). 반면, Nginx는 모든 I/O(accept4, recvfrom, writev)를 Non-blocking으로 처리한다.
즉, 프로세스가 멈추는 시점은 오직 epoll_pwait를 호출했을 때뿐이다. 할 일이 없을 때만 스스로 CPU를 놓고 대기하는 것이다.
Ready List 소비
epoll_pwait가 리턴됐다는 건, 커널 내부의 Ready List에 처리해야 할 이벤트가 쌓였다는 뜻이다. Worker는 깨어난 직후, 이 리스트에 있는 FD들을 순회하며 일괄 처리(Batch Processing)하고 다시 대기 모드로 돌아간다.
(2) Non-blocking I/O와 Edge Triggered(ET)의 결합
로그에서 확인된 accept4(..., SOCK_NONBLOCK)와 epoll_ctl(..., EPOLLET)의 조합은 Nginx 성능의 핵심이다.
왜 Non-blocking이 필수인가
Edge Triggered(EPOLLET)는 상태가 변하는 그 순간(예: 데이터 도착)에만 딱 한 번 이벤트를 던진다. 만약 버퍼에 데이터가 남았는데 read를 멈추면, 다음 패킷이 올 때까지 영원히 데이터를 안 읽는 Starvation에 빠진다.
그래서 Nginx는 SOCK_NONBLOCK으로 소켓을 열고, EAGAIN 에러가 뜰 때까지 루프를 돌며 버퍼를 바닥까지 긁어서 읽는 전략을 쓴다.
System Call 오버헤드 감소
Level Triggered(LT)는 데이터가 남아있으면 계속 이벤트를 던져서 불필요한 epoll_wait 호출을 유발한다. 반면 ET는 딱 한 번만 깨우므로 Context Switching 비용이 획기적으로 줄어든다.
(3) 커널 자료구조를 통한 O(1) 성능 달성
epoll_ctl은 단순한 등록 함수가 아니라, 커널 메모리 영역(Kernel Space)에 있는 RB-Tree(Interest List)를 조작하는 과정이다.
- Interest List 관리: 동시 접속자가 10만 명이라도 Nginx는 이걸 매번 다 검사하지 않는다. epoll_ctl로 커널 내 RB-Tree에 FD를 박아두면, I/O 이벤트가 터진 놈들만 커널이 알아서 Ready List(Doubly Linked List)로 옮겨준다.
- Scalability: 따라서 epoll_wait가 반환할 때 Nginx가 처리할 데이터 양은 '전체 접속자 수'가 아니라 '지금 활성화된 접속자 수'에만 비례한다. 접속자가 아무리 늘어도 성능이 선형적으로 떨어지지 않고 유지되는 O(1) 근거가 바로 여기에 있다.



댓글