위글은 분산시스템의 예시, 분산시스템의 핵심 특성, 분산시스템의 종류에 대해서 소개한다.
Distributed System Examples
1. 모바일 클라우드 컴퓨팅

모바일 클라우드 컴퓨팅(MCC)은 모바일 기기와 클라우드 컴퓨팅을 결합한 기술로, 모바일 기기의 성능, 저장 용량, 배터리 소모 등의 한계를 극복하기 위해 클라우드 서버에서 연산 및 데이터를 처리하는 개념이다.
요즘은 한 서버내에 여러 가상 머신을 쓰고 있는데, 머신들이 여러개 모여있는 분산 시스템으로 구성한다.
모바일 fog 컴퓨팅
모바일 Fog 컴퓨팅(MFC)은 클라우드 컴퓨팅과 모바일 엣지 컴퓨팅(MEC) 사이에 위치하는 컴퓨팅 모델이다. 클라우드에서 모든 처리를 수행하는 기존 방식과 달리, 네트워크 엣지에서 분산된 노드(Fog 노드)를 활용하여 데이터 처리를 수행한다
엣지 컴퓨팅
엣지 컴퓨팅(Edge Computing)은 데이터가 생성되는 곳(엣지, Edge)에서 가까운 장치에서 데이터를 처리하는 방식이다. Fog 컴퓨팅과 유사하지만, Fog가 네트워크 인프라 전체에서 분산 처리를 하는 개념이라면, 엣지 컴퓨팅은 데이터가 생성된 장치 또는 그 바로 옆에서 처리를 수행하는 개념이다.
요즘은 모바일 클라우드 컴퓨팅 -> 모바일 포그 클라우드 컴퓨팅으로 전환하는 추세이다.
2. 데이터센터
데이터센터(Data Center)는 대규모의 서버, 네트워크 장비, 저장 장치(Storage) 등이 연결된 물리적 인프라로, 수많은 사용자 요청을 처리하고 데이터를 저장·분석하는 역할을 한다.
- core 스위치: 밖(인터넷)으로 나가는 스위치
- aggr 여러 렉을 모아서 집합을 만드는 집합 aggr 스위치
- edge: 여러 서버들을 가지고 있는 렉
- ToR: top of rack 렉 위에 스위치
스위치들은 라우팅 테이블이 있는데 항상 위에서 아래로 가는 방향이었다
3. IoT 시스템
intelligent fog system 사물인터넷(IoT, Internet of Things) 시스템은 수많은 장치(센서, 액추에이터, 엣지 장치, 서버)가 네트워크를 통해 연결되어 데이터를 수집하고 처리하는 형태로, 본질적으로 분산 시스템의 일종이다.
- 엣지(Edge) 계층 – 데이터 생성 및 1차 처리 IoT 센서, 스마트 기기, 웨어러블 장치, CCTV 등이 포함됨.
- 분산 시스템 특성: 다수의 장치가 독립적으로 작동하며 데이터를 병렬로 처리함.
- Fog 계층 – 네트워크 근처에서 데이터 처리 게이트웨이, 라우터, 엣지 서버 등이 위치하며, IoT 장치에서 수집된 데이터를 로컬에서 처리.
- 분산 시스템 특성: 여러 개의 엣지 노드가 분산되어 데이터를 처리하며, 특정 노드가 실패해도 전체 시스템이 동작할 수 있음.
- 클라우드 계층 – 중앙 집중형 분석 및 데이터 저장 클라우드 서버에서 장기적인 데이터 분석, AI 학습, 대규모 저장 기능을 수행.
- 분산 시스템 특성: 여러 개의 클라우드 서버가 협력하여 대규모 연산을 수행하며, 데이터가 복제되어 저장됨.
4. 블록체인 시스템
블록체인은 네트워크에 참여하는 여러 개의 노드(컴퓨터)가 분산된 환경에서 데이터를 공유하고 검증하는 시스템이다. 이는 중앙 서버 없이 독립적으로 운영되며, 각 노드가 동일한 데이터를 유지하고 합의(Consensus) 알고리즘을 통해 무결성을 보장한다. 이러한 특성으로 인해 블록체인은 대표적인 분산 시스템(Distributed System) 중 하나로 분류된다.
p2p 아키텍처 처럼 모든 노드들이 완전히 똑같은 정보를 가지고 있다 데이터센터는 데이터 서버가 죽어도 응답을 할수 있는 가용성 높은 시스템을 위한다면, 블록체인은 데이터의 무결성과 검증을 위해서 한다.
Key Feature of Distributed Systems
분산 시스템의 패러다임: 머신은 항상 죽을 수 있다 라고 항상 생각한다
클라우드: Transparency to User
사용자는 데이터센터 내부의 복잡한 구조를 인식하지 못한 채, 단일 시스템처럼 서비스를 이용한다. 하지만 실제로는 여러 개의 독립적인 컴퓨터가 분산되어 동작하며, 분산 시스템 기술을 통해 이들을 하나의 거대한 컴퓨터처럼 보이게 만든다.
미들웨어: Transparency to Distributed Apps
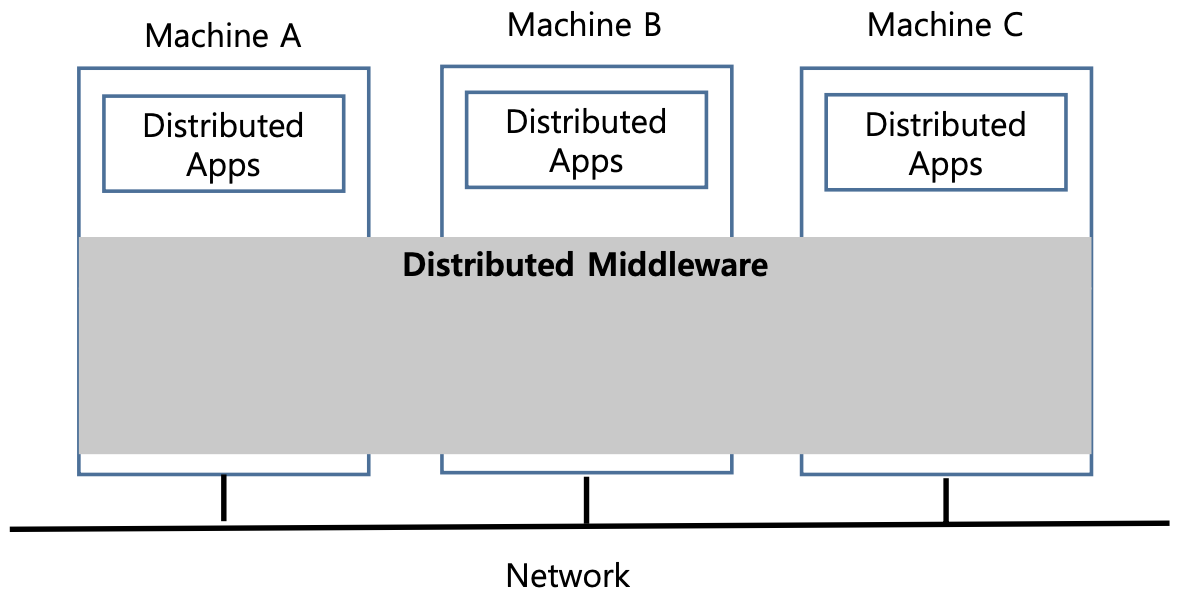
분산시스템이 될려면 개별 컴퓨터들이 마치 하나의 시스템처럼 동작해야 한다 미들웨어가 분산된 환경에서도 애플리케이션이 이를 인식하지 않고 실행될 수 있도록 투명성을 제공한다.
예를 들어 Hadoop은 여러 노드를 제어하며, 이를 통해 애플리케이션이 단일 시스템처럼 데이터를 처리할 수 있도록 한다. Hadoop은 내부적으로 시스템 콜을 수행하여 분산된 자원을 효율적으로 관리한다.
Transparency Aspects
- Access Transparency (접근 투명성) 로컬과 원격 리소스에 동일한 방식으로 접근할 수 있어야 한다. 예: 네트워크 파일 시스템(NFS), 클라우드 스토리지(AWS S3).
- Location Transparency (위치 투명성) 리소스의 실제 물리적 위치와 관계없이 동일하게 접근해야 한다. 예: DNS를 통해 서버 위치가 변경되어도 동일한 도메인으로 접속 가능.
- Migration Transparency (마이그레이션 투명성) 실행 중인 프로세스나 데이터가 다른 노드로 이동해도 영향을 주지 않아야 한다. 예: Kubernetes의 컨테이너 자동 이동, 클라우드의 가상 머신 마이그레이션.
- Relocation Transparency (재배치 투명성) 리소스가 이동하는 동안에도 클라이언트가 끊김 없이 사용할 수 있어야 한다. 예: 클라우드 VM 라이브 마이그레이션.
- Replication Transparency (복제 투명성) 데이터가 여러 서버에 복제되어도 사용자에게는 하나의 데이터처럼 보여야 한다. 예: Google Drive에서 파일이 여러 서버에 저장되지만 하나로 보임.
- Concurrency Transparency (동시성 투명성) 여러 사용자가 동시에 같은 데이터를 접근해도 충돌 없이 일관성이 유지되어야 한다. 예: 데이터베이스의 트랜잭션 관리(ACID), 분산 락.
- Failure Transparency (장애 투명성) 일부 서버가 고장 나도 전체 시스템이 정상적으로 동작해야 한다. 예: AWS S3는 자동 복구 기능을 통해 장애가 발생해도 데이터를 유지.
- Persistence Transparency (지속성 투명성) 데이터가 메모리 또는 디스크 어디에 저장되든 동일한 방식으로 접근 가능해야 한다. 예: 데이터베이스에서 데이터를 저장소와 관계없이 동일한 인터페이스로 접근.
Types of Distributed Computing System
1. High Throughput Computing
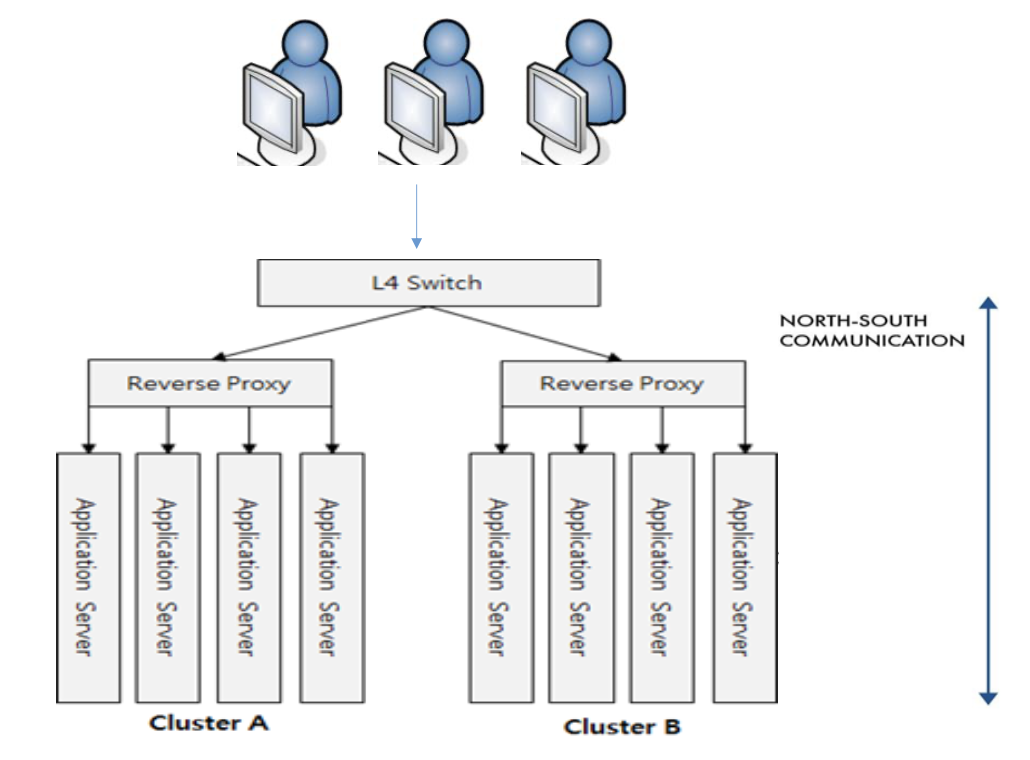
많은 연산을 처리하는 컴퓨팅 방식에는 North-South 트래픽을 처리하는 독립적인 컴퓨팅(Web Service 등)이 있다.
빅데이터의 안정성을 위해 동일한 데이터를 여러 복제본으로 저장하여 가용성을 높인다.
2. Big Data Computing
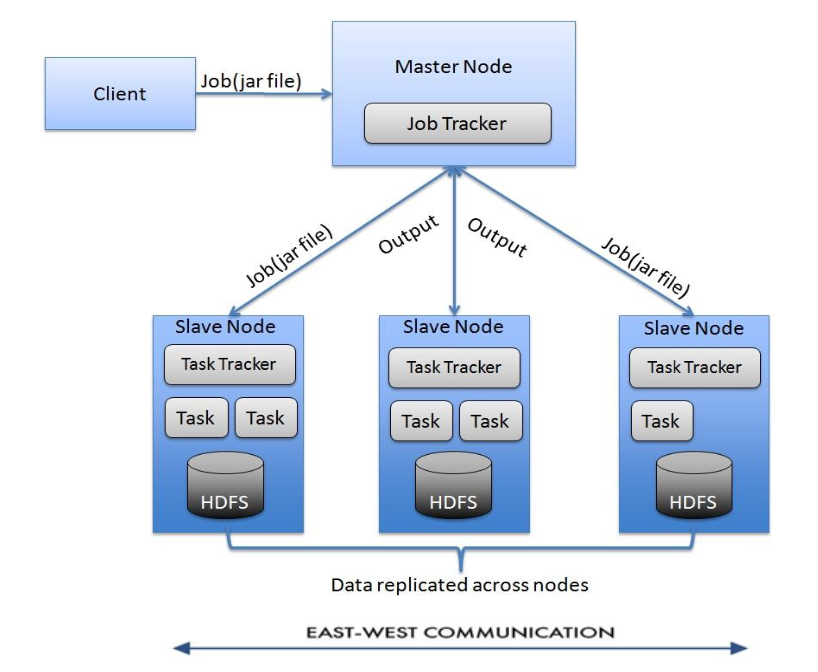
East-West 트래픽은 데이터센터 내부에서 서버 간 데이터를 주고받는 통신을 의미한다.
테라바이트 단위의 대량 데이터를 다룰 때, 최대값을 구하는 등의 연산을 위해 빅데이터 처리가 필요하다.
이 과정에서 데이터 이동이 빈번해지며, 효율적인 처리를 위해 라우팅 테이블을 동적으로 변경해야 한다.
빅데이터 처리는 이러한 East-West 트래픽을 효율적으로 관리하여 대량의 데이터를 분산 처리한다.
East-West Packet은 서버 간 데이터 교환을 최적화하는 네트워크 패킷으로,
Cooperative Computing(협력적 연산) 환경에서 노드들이 데이터를 공유하며 연산을 수행할 때 사용된다.
Hadoop과 같은 분산 컴퓨팅 시스템은 노드 간 데이터를 교환하며 병렬로 연산을 수행한다.
이 과정에서 네트워크 부하를 최소화하고, 데이터 이동을 최적화하기 위해 라우팅 알고리즘과 SDN 기술이 활용된다.
3. P2P 블록체인

블록체인은 블록(데이터)이 체인 형태로 연결된 구조를 가진다.
블록체인의 핵심 개념은 신뢰할 수 없는 환경(Untrustworthy World)에서 신뢰할 수 있는 거래를 가능하게 하는 것이다.
이 과정에서 객체 간 호출과 메시지 전달이 이루어지며, 해시 포인터(Hash Pointer) 함수를 활용하여 데이터 무결성을 보장한다.
Blockchain은 탈중앙화된 원장(Decentralized Ledger) 시스템을 기반으로 한다.
하나의 원장이 아니라 여러 개의 동일한 원장(DB)을 각 노드가 복제하여 보관하며, 이를 통해 데이터 위변조를 방지한다.
블록 스토리지는 데이터를 여러 노드에 분산 저장하는 구조를 갖는다.
토렌트(P2P 파일 공유)는 데이터 전송을 최적화하기 위한 기술이지만,
블록체인은 데이터의 무결성과 신뢰성을 유지하는 데 초점을 둔다.
4. SoS(System of Systems) 시스템

SoS(System of Systems)는 여러 개의 독립적인 시스템이 상호 작용하며 하나의 거대한 시스템을 구성하는 구조이다.
각각의 시스템은 자율적으로 운영되지만, 필요할 때 협력하여 전체적인 기능을 수행할 수 있어야 한다.
SoS 시스템에서는 유저(User), 스토리지(Storage), 컴퓨팅 노드(Computing Node)가 각각 독립적으로 존재한다.
- 유저(User): 데이터를 요청하고 서비스와 상호작용하는 주체.
- 스토리지(Storage): 데이터를 저장 및 관리하는 분산된 데이터 저장소.
- 컴퓨팅 노드(Computing Node): 데이터를 연산하고 처리하는 역할.
이러한 구조를 통해 확장성과 유연성을 극대화하며, 시스템 간의 의존성을 최소화하여 높은 신뢰성을 보장할 수 있다.
5. High Performance GPU Computing

High Performance GPU Computing은 대량의 데이터를 병렬 연산하여 높은 성능을 제공하는 분산 컴퓨팅 방식이다.
기존의 CPU 기반 연산보다 수천 개의 코어를 가진 GPU(Graphics Processing Unit)를 활용하여 병렬 처리를 극대화한다.
분산 시스템의 관점에서 보면, GPU는 여러 개의 독립적인 연산 장치가 하나의 시스템처럼 동작하는 구조를 가진다.
이를 통해 데이터 병렬성(Data Parallelism)을 활용하여 AI, 머신러닝, 빅데이터 분석, 과학 연산 등을 가속할 수 있다.
- 병렬 연산(Parallel Processing): 여러 개의 GPU가 동시에 연산을 수행하여 속도를 향상.
- 확장성(Scalability): 필요에 따라 다수의 GPU를 추가하여 성능을 확장 가능.
- 분산 학습(Distributed Training): 여러 개의 GPU 노드가 협력하여 AI 모델을 학습.
- 고속 데이터 처리: 대량의 벡터 및 행렬 연산을 최적화하여 연산 속도를 극대화.
HPC(High-Performance Computing) 환경에서는 GPU 클러스터를 활용한 분산 컴퓨팅이 필수적이며,
CUDA, OpenCL, TensorFlow 등의 프레임워크를 사용하여 분산된 GPU 노드에서 연산을 병렬로 수행한다.
'CS 지식 > 분산시스템과 컴퓨팅' 카테고리의 다른 글
| [분산시스템] 분산 알고리즘과 Coordinator개념 소개 (Bully Algorithm, Zookeeper Leader) (0) | 2025.04.14 |
|---|---|
| 장애허용성과 TMR, 프로세스 그룹의 개념 설명 (Fault Tolerance, Process Group) (1) | 2025.04.12 |
| Ceph의 소개와 HDFS와 차이 (0) | 2025.04.03 |
| 빅데이터 처리와 람다 아키텍처 소개(Hadoop) (0) | 2025.04.02 |
| 분산시스템의 아키텍처와 운영체제의 종류 (0) | 2025.03.16 |




댓글