Ceph: 고확장성 오브젝트 기반 분산 파일 시스템

Ceph는 오픈소스 객체 기반 분산 파일 시스템으로, 높은 확장성과 가용성, 유연성을 제공하며 다양한 형태의 스토리지 인터페이스(Block, File, Object)를 지원한다. 특히 클라우드 환경에서 VM 백엔드 저장소, 오브젝트 저장소 등으로 널리 활용된다.
1. Ceph의 주요 특징
- Unified Storage: Block, File, Object 스토리지 지원
- Scalable: 수만~10만 개 노드까지 확장 가능 (엑사바이트 단위)
- Active-Active 구조: 모든 컴포넌트가 동시에 읽기/쓰기 처리 가능
- Self-healing: 장애 발생 시 자동 복구
- Open Source: GPL 기반, 다양한 상용 서비스에 활용 가능
- 멀티 OS 지원: CentOS, Ubuntu, RedHat 등에서 운영 가능
- Restful API 지원: S3 호환 API 제공
2. Ceph 아키텍처 및 구성 요소
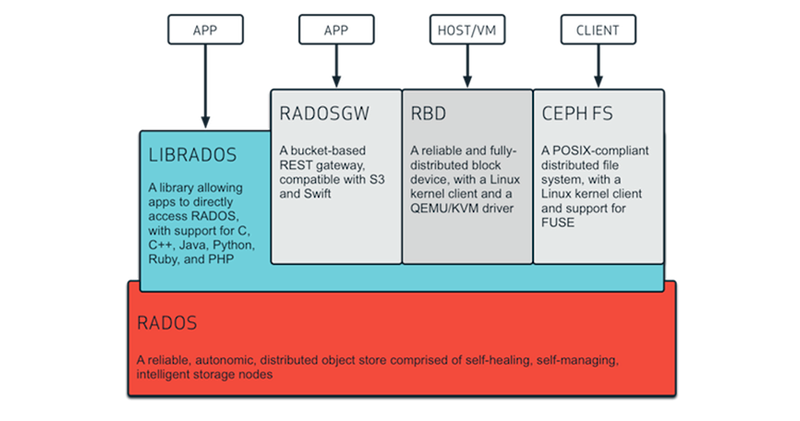

Ceph는 내부적으로 RADOS (Reliable Autonomic Distributed Object Store) 라는 스토리지 계층을 중심으로 구성되어 있으며, 다음과 같은 컴포넌트로 구성된다.
| 구성 요소 | 역할 설명 |
| MON (Monitor) | 클러스터 상태 관리, 멤버십 관리, 컨센서스 수행 (Paxos 기반) |
| OSD (Object Storage Daemon) | 실제 데이터 저장 및 복제, 복구 수행 |
| MDS (Metadata Server) | 파일 시스템(CephFS) 메타데이터 관리 |
| RADOS Gateway (RGW) | RESTful API 제공, S3 호환 오브젝트 저장 |
| Client | 사용자 애플리케이션에서 Ceph 스토리지에 접근 (Block, File, Object 지원) |
MON은 반드시 3개 이상 구성되어야 Paxos 컨센서스 구조가 안전하게 작동함
3. Ceph의 저장 및 접근 방식

🔸 쓰기(Write) 과정
- 클라이언트가 MON에게 상태 및 OSD 위치 질의
- Primary OSD를 할당받아 데이터 저장
- Primary OSD가 다른 Secondary OSD에 복제
- 모든 복제가 완료되면 클라이언트에 ACK 전송
🔸 읽기(Read) 과정
- 클라이언트가 MON 또는 로컬 맵에서 OSD 위치 확인
- OSD에서 데이터를 직접 읽어옴
4. CRUSH 알고리즘: Ceph의 분산 방식 핵심

- CRUSH: Controlled Replication Under Scalable Hashing
- 중앙 인덱스 서버 없이도 데이터를 분산 배치
- 해시 기반 알고리즘으로 데이터 저장 위치를 계산
- 네트워크 오버헤드 없이 빠르게 위치 탐색 가능
- 노드 추가/제거 시에도 데이터 재배치 최소화
5. Ceph의 Replication & Fault Tolerance

- 기본 3중 복제 구조
- Primary OSD가 데이터를 저장한 후, Secondary OSD에 복제 수행
- 복제 완료 후 클라이언트에 성공 응답
- OSD 장애 발생 시 다른 OSD들이 자동으로 데이터를 복제해 복구 (Self-healing)
6. HDFS와 Ceph의 비교
| 항목 | Hadoop HDFS | Ceph |
| 주요 목적 | 병렬 처리 기반 스토리지 | 범용 스토리지 (Block, File, Object) |
| 구조 | Master-Slave | Peer-to-Peer (모든 노드 Active) |
| 메타데이터 관리 | NameNode 단일 관리 | MON + MDS 분산 관리 |
| 장애 복구 방식 | Passive Standby NameNode | 모든 MON Active, Paxos 기반 합의 |
| 데이터 분산 알고리즘 | Rack-aware 복제 | CRUSH 기반 복제 |
| 확장성 | 수천 대까지 가능 | 수만~10만 대 이상까지 가능 |
| 데이터 접근 방식 | Block 기반 | Object 기반 (Block/File/Object 지원) |
| 사용 사례 | 빅데이터 분석, MapReduce | 클라우드 스토리지, VM 백엔드, S3 API |
7. Ceph의 활용 사례
- 클라우드 인프라: OpenStack, Kubernetes의 백엔드 스토리지
- 오브젝트 스토리지: S3 호환 API 제공 (RADOSGW)
- 파일 시스템: POSIX 호환 CephFS 사용
- 딥러닝/머신러닝: 대규모 학습 데이터 저장 및 병렬 처리 환경
- 실시간 분석 플랫폼: 유연한 저장과 고성능 접근을 필요로 하는 환경
8. Ceph 구조 요약 다이어그램
[ Client ]
↓
[ MON ] ←→ [ MON ] ←→ [ MON ]
↓
CRUSH 알고리즘
↓
[ Primary OSD ] → [ Secondary OSD ]
↓
[ MDS ] (CephFS 사용 시)
↓
[ RADOS Gateway ] (S3 API 등)
9. 결론: 언제 Ceph을 사용해야 할까?
- Hadoop HDFS는 대용량 배치 처리에 최적화되어 있으며, MapReduce나 Spark와 같은 빅데이터 처리 프레임워크와 함께 사용된다.
- 반면, Ceph는 다양한 형태의 데이터를 저장할 수 있으며, 실시간 접근성과 고가용성을 제공한다. 특히 다음과 같은 경우에 Ceph가 적합하다:
✅ Ceph 사용이 적합한 경우
- 다양한 형태의 데이터 저장이 필요한 경우
- 오브젝트, 블록, 파일 저장을 하나의 시스템에서 지원
- 고가용성 및 자가 복구(Self-healing)가 중요한 환경
- CRUSH 알고리즘 기반으로 SPOF 없이 안정적 운영 가능
- 확장성이 중요한 환경
- 수천~수만 노드까지 유연하게 수평 확장 가능
- 클라우드 기반 인프라
- OpenStack, Kubernetes의 백엔드 스토리지로 적합
- RADOSGW를 통한 S3 호환 오브젝트 스토리지 제공
- 실시간 및 랜덤 접근이 필요한 경우
- 작은 파일 다수, 빠른 응답 필요 등
- 머신러닝/AI 분석 환경
- 대용량 학습 데이터의 고속 병렬 접근이 필요한 경우
Ceph의 핵심 가치
Ceph는 단순한 분산 저장 시스템을 넘어서, 고신뢰성, 유연성, 확장성을 모두 갖춘 차세대 범용 스토리지 플랫폼이다. 병렬 데이터 분석이 주 목적이라면 HDFS가, 범용 저장 및 클라우드 기반 운영환경에서는 Ceph가 우수한 선택이 될 수 있다.
반응형
'CS 지식 > 분산시스템과 컴퓨팅' 카테고리의 다른 글
| HDFS(하둡 분산 파일 시스템) 구조 및 작동 방식 (0) | 2025.04.03 |
|---|---|
| 하둡(Hadoop)의 아키텍처, 병렬처리, 장애처리 전략 (0) | 2025.04.02 |
| 빅데이터 처리와 람다 아키텍처 소개(Hadoop) (0) | 2025.04.02 |
| 분산시스템의 아키텍처와 운영체제의 종류 (0) | 2025.03.16 |
| 분산시스템과 컴퓨팅의 소개 (0) | 2025.03.10 |




댓글