Issue of Fault Tolerance
- Fault Tolerance는 distributed system(분산 시스템)의 핵심 특성 중 하나로, single-machine system(단일 시스템)과의 중요한 차별점을 이룬다.
- 특히, 분산 시스템에서는 partial failure(부분 실패)의 개념이 존재하며, 이는 시스템의 일부만 고장나는 상황을 의미한다.
- 따라서 분산 시스템 설계의 중요한 목표 중 하나는, 시스템이 이러한 부분 실패로부터 자동으로 회복할 수 있도록 구성하는 것이다.
- 이러한 회복 과정은 전체 성능에 심각한 영향을 주지 않아야 한다.
Stability Quality of Software Systems

Availability
- Availability는 시스템이 즉시 사용 가능한 상태에 있는 특성을 의미한다.
- 즉, 사용자가 요청했을 때 시스템이 동작 가능한 상태를 말한다.
- 시스템이 운영 중(operational)이어야 한다.
수식:
- Uptime: 시스템이 정상적으로 동작한 시간
- Downtime: 시스템이 장애로 인해 사용 불가능했던 시간
- MTBF (Mean Time Between Failures): 평균 고장 간격
- MTTR (Mean Time To Repair): 평균 복구 시간
해석:
- MTBF가 클수록, MTTR이 작을수록 가용성은 증가한다.
- 예: MTBF = 99시간, MTTR = 1시간 → Availability = 99%
Reliability
- Reliability는 시스템이 지속적으로, 고장 없이 작동할 수 있는 능력을 의미한다.
- 즉, 시스템이 오랜 시간 동안 중단 없이 작동할 가능성을 뜻한다.
- 시스템이 정상적으로 동작할 가능성이 높다는 특성이다.
수식:
- 주어진 기간 동안 고장 없이 얼마나 오래 운영되었는지의 비율
- t: 관찰 시간
- MTBF: 평균 고장 간격
해석:
- 시간이 흐를수록 신뢰도는 감소하며, MTBF가 클수록 신뢰도는 천천히 감소한다.
- 시스템의 동작 시간 동안 고장이 발생하지 않을 확률 모델 기반의 정의이다.
Maintainability
- Maintainability는 시스템이 고장났을 때, 이를 얼마나 쉽게 수리하거나 유지 관리할 수 있는지를 나타내는 특성이다.
수식:
- μ (뮤): 수리율 (Repair rate)
- t: 특정 시간 동안의 수리 가능성
- MTTR: 평균 수리 시간
해석:
- μ가 클수록 (즉 MTTR이 작을수록), 시스템은 더 빨리 수리 가능
- 주어진 시간 안에 시스템이 복구될 확률을 의미
Safety
- Safety는 시스템이 일시적으로 잘못 작동하더라도, 치명적인 결과가 발생하지 않아야 하는 상황을 의미한다.
- 예를 들어, 오류가 발생해도 데이터 손실이나 인명 피해 등 큰 피해가 없어야 한다.
Fault와 Fault Tolerance란?
기본 개념
Fault
- Error의 원인이다.
- 시스템 내 문제의 근본적인 발생 원인을 뜻한다.
Error
- 시스템의 상태 중 일부가 잘못된 상태이며, 이로 인해 failure(실패)로 이어질 수 있는 상황이다.
Fail (or Failure)
- 시스템이 약속한 기능을 제공하지 못할 때, 즉 서비스 제공이 불가능한 상태일 때 발생한 것을 말한다.
- 시스템이 동작을 중단하거나, 정상적인 서비스를 제공하지 못하는 경우이다.
Fault Tolerance
- Fault tolerance란 시스템 내 fault가 발생해도, 시스템이 여전히 서비스를 제공할 수 있는 능력을 의미한다.
- 즉, 장애가 발생해도 서비스를 유지할 수 있는 설계가 되어 있는 것이다.
System State Diagram
Types of Faults
Transient Fault
- 한 번 발생하고 다시는 발생하지 않는 일시적 오류
- 예: 전자파를 전송하는 마이크로파 송신기 빔을 새가 지나가는 경우처럼, 일회성 간섭
Intermittent Fault
- 발생했다가 사라지고, 다시 나타나는 불규칙한 오류
- 예: 커넥터의 느슨한 접촉과 같은 상황. 어떤 조건에서만 나타났다 사라지기를 반복함
Permanent Fault
- 해당 구성 요소가 수리되기 전까지 지속적으로 존재하는 오류
- 예: 소프트웨어 버그, 디스크 헤드 충돌 등과 같은 지속적인 장애
Failure Models
| Type of Failure | Description |
| Crash Failure | 서버가 중단되기 전까지는 정상적으로 동작하다가, 갑자기 멈추는 현상 |
| Omission Failure | 서버가 요청에 응답하지 않는 현상 - Receive omission: 요청을 받지 못함 - Send omission: 응답을 보내지 못함 |
| Timing Failure | 서버의 응답이 지정된 시간 간격을 벗어남 시스템이 응답을 너무 빨리 하거나, 너무 늦게 하거나, 적시에 하지 못하는 실패 |
| Response Failure | 서버의 응답이 잘못된 결과를 포함함 - Value failure: 잘못된 값 - State transition failure: 잘못된 상태 전이 |
| Arbitrary Failure | 서버가 임의의 잘못된 동작을 하며, 때로는 악의적일 수 있음 (Byzantine Failure) 가장 일반화된 실패 모델로, 시스템이 임의의 잘못된 행동을 하는 경우 예: 오류가 있지만 그것이 어떤 규칙을 따르지 않고 예측 불가능한 동작을 하는 것 |
Crash Failure
- 정의: 서버가 정상적으로 동작하다가 갑자기 중단되는 상황
- 한 번 중단되면, 다시는 응답을 보내지 않음
- 예시: 운영체제가 멈추고, 재부팅만이 유일한 해결책인 경우
- 의의: 그래서 리셋 버튼을 접근하기 쉬운 곳에 둔 것에는 명확한 이유가 있음
Omission Failure
- 정의: 서버가 클라이언트의 요청에 응답하지 않는 상황
- 두 가지 유형이 존재함
Receive Omission
- 서버가 요청을 받지 못함
- 예: 연결은 되었지만, 요청을 수신할 쓰레드가 존재하지 않음
- 이 경우 서버의 현재 상태에는 영향 없음 (요청 자체를 모름)
- 즉, 서버 입장에서는 변화가 없다.
Send Omission
- 서버가 작업을 완료했으나, 응답을 전송하지 못함
- 예: 전송 버퍼 오버플로우 상황에서 서버가 준비되지 않았을 경우
- 이 경우 서버의 상태는 클라이언트 요청을 이미 처리한 상태
- 즉, 서버가 처리는 했지만 스킵하고 다음 task를 수행하고 있는 상태이다.
Timing Failure
- 정의: 응답이 정해진 시간 간격을 벗어나는 경우
- 예: 서버가 응답을 너무 늦게 주는 경우
- 반대로 너무 빨리 응답하면, 수신 측의 버퍼 부족 등 문제 발생 가능
Response Failure
- 정의: 서버의 응답이 단순히 잘못된 결과일 경우
- 두 가지 하위 유형이 존재함
Value Failure
- 서버가 잘못된 값을 응답하는 경우
- 예: 검색어와 무관한 웹페이지를 반환하는 검색 엔진
State Transition Failure
- 서버가 예상과 다른 방식으로 반응하는 경우
- 예: 서버가 인식하지 못하는 메시지를 받고, 이를 적절히 처리하지 못하는 경우
Arbitrary Failure (Byzantine Failure)
- 서버가 임의의 잘못된 응답을 하며, 오류임을 식별할 수 없는 경우
- 최악의 상황에는, 서버가 다른 서버와 협력하여 악의적인 응답을 생성할 수도 있음
- 이러한 이유로 보안(Security) 도 fault tolerance의 중요한 구성 요소가 됨
- ex) 좀비 컴퓨터
Failure Masking by Redundancy (장애 은폐)
- Fault Tolerance를 달성하기 위한 핵심 방법은 다른 프로세스들이 장애를 인식하지 못하도록 숨기는 것
- Redundancy를 통해 이를 달성할 수 있음
Redundancy의 유형
Information Redundancy
- 추가적인 비트를 사용하여 오류 데이터를 복구함
- 예: Hamming Code 등 오류 정정 코드 (network recovery)
Time Redundancy
- 동일한 작업을 반복 수행함으로써 장애를 회피함
- 주로 transient 또는 intermittent fault에 유용함
- 예: Transaction 재시도, TCP (Retry)
Physical Redundancy
- 추가 장비 또는 프로세스를 통해 일부 구성 요소의 손실이나 오작동에도 시스템 전체가 동작 유지 가능
- 예: 이중화된 서버, RAID 구조의 디스크 시스템
TMR (Triple Modular Redundancy) 구조 설명
- TMR은 세 개의 동일한 모듈(프로세스)을 병렬로 실행하여 하나의 모듈이 실패하더라도 나머지 둘의 결과를 바탕으로 정확한 결과를 도출하는 구조
- 핵심 개념은 다수결(Majority Voting) 방식으로 오류를 탐지하고 무시하는 것
- 일반적으로 1개의 오류를 허용할 수 있으며, 2개 이상 모듈이 일치하면 그 값을 정답으로 채택함
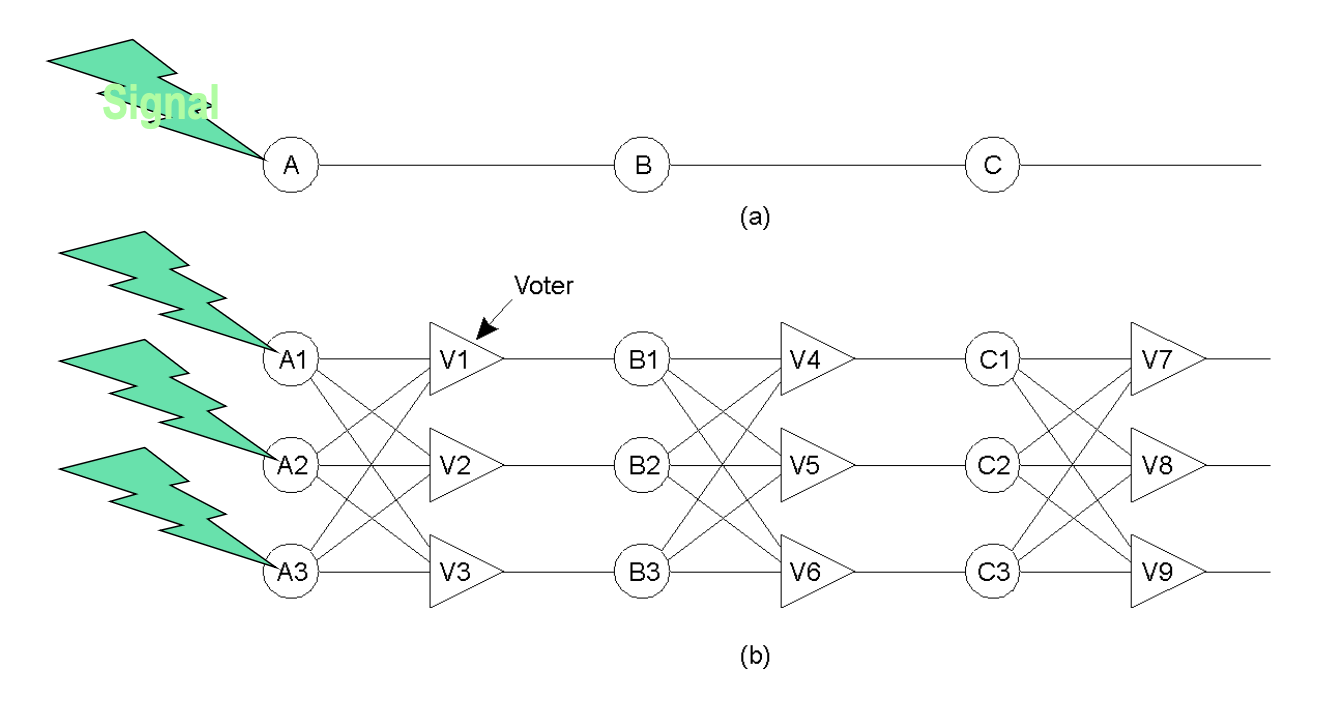
그림 구성 요소 설명
해당 그림은 두 가지 시스템 구조를 비교하고 있다:
(a) 단일 경로 시스템 (비중복 구조)
- 입력 A → B → C로 이어지는 단일 처리 경로
- 단일 노드에 장애가 발생하면 전체 시스템이 실패(failure)할 수 있음
(b) TMR 기반 다중 경로 시스템 (중복 구조)
- 각 처리 단계(A, B, C)가 3개의 모듈로 복제됨: A1~A3, B1~B3, C1~C3
- 각 단계 사이에 Voter(V1 ~ V9)가 존재하여 3개의 출력 중 2개 이상이 일치하는 결과를 채택
- 각 voter는 다수결로 출력 결정
- 입력 Signal은 A1, A2, A3 모두에 전달되며, 병렬 실행 후 다수결로 결과를 결정
단계별 흐름
- 입력(Signal)
- 동일한 입력이 세 개의 A 모듈(A1, A2, A3)에 동시에 주어짐
- 1단계 Voting (V1, V2, V3)
- 각 voter는 세 A 모듈의 출력을 비교하고 다수결로 출력 결정
- A1~A3 → V1~V3 → B1~B3에 전달
- 중간 처리 (B1~B3)
- 각각 독립적으로 처리되고 다시 다중 경로로 다음 단계로 전달
- 2단계 Voting (V4, V5, V6)
- B 단계에서 나온 값을 다시 다수결로 집계하여 C 모듈(C1~C3)로 전달
- 최종 처리 (C1~C3) 및 최종 Voting (V7~V9)
- C 모듈의 결과를 기반으로 마지막 voting 수행
- 최종 출력 결정
TMR의 특징 요약
- 고장 허용 수: 최대 1개의 모듈이 고장나도 시스템은 정확한 결과 제공 가능
- 신뢰도 향상: 다수결 로직으로 인해 단일 오류가 전체 시스템에 영향을 주지 않음
- 복잡도 증가: 3배의 하드웨어 또는 프로세스 필요
- Voting 논리: 각 단계에서 3개의 결과 중 2개 이상이 일치하는 값을 선택
장점
- 높은 Fault Tolerance
- 간단한 다수결 로직으로 오류 제거
- 하드웨어/소프트웨어 혼합 적용 가능
단점
- 리소스 3배 소모
- Voter 자체가 고장날 경우 single point of failure가 될 수 있음
- Voting 결과가 서로 다르면 처리 불가 (ex. 3개 모두 상이할 경우)
Process Group 설계
Design Issues (설계 시 고려 사항)
- 고장난 프로세스를 허용하는 방법은 여러 개의 동일한 프로세스를 그룹(process group)으로 구성하는 것이다.
- Process Group의 도입 목적은 여러 프로세스를 하나의 추상적 단위로 다루기 위함
- 프로세스는 메시지를 보낼 때, 그룹의 구성원 수나 위치에 관계없이 그룹 전체에 전송할 수 있음
- 단, 이러한 Fault Tolerance를 위한 설계에서 중요한 이슈는 얼마만큼의 복제(replication)가 필요한가이다.
Process Group (프로세스 그룹)
- Process Group은 동적(dynamic)일 수 있으며,
- 새로운 그룹을 생성하거나 삭제 가능
- 프로세스는 그룹에 가입하거나 탈퇴할 수 있음
- 하나의 프로세스가 여러 그룹의 멤버가 될 수도 있음
- 그룹과 멤버십을 관리하기 위한 메커니즘이 필요
- 이러한 그룹은 사회 조직(social organization)과 유사한 방식으로 동작함
Flat Groups vs. Hierarchical Groups
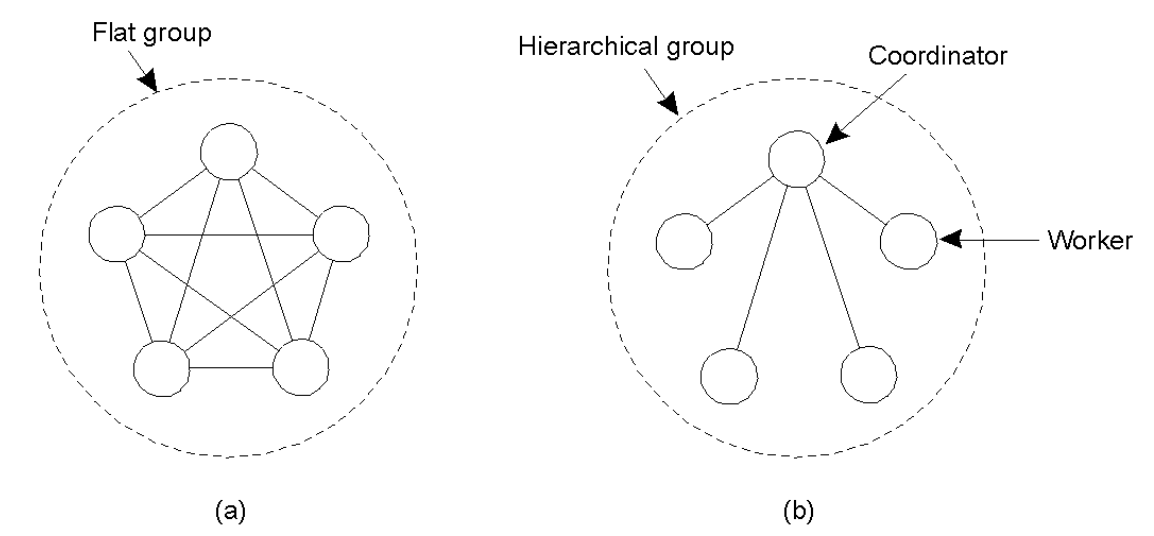
Flat Group (평면 그룹)
- 대칭적 구조를 가지며, 단일 실패 지점(single point of failure)이 없음
- 결정 과정이 복잡하고,
- 어떤 결정을 내리기 위해 투표(vote)가 필요할 수 있음
- 이로 인해 지연과 오버헤드 발생
- 전체적으로 분산된 책임 구조
평면그룹에 분산 알고리즘을 적용하면 계층적 그룹으로 변하기도 한다
Hierarchical Group (계층적 그룹)
- 중앙 관리자(coordinator)가 존재하는 구조
- 관리 및 통제가 쉬움
- 단점: coordinator가 실패할 경우 전체 그룹이 중단될 수 있음
- 즉, 단일 실패 지점 존재
Group Management (그룹 관리)
주요 이슈
- 그룹 통신이 존재할 경우, 다음과 같은 관리 방식이 필요함:
- 그룹의 생성과 삭제
- 프로세스의 가입(join)과 탈퇴(leave)
Centralized Group Server (중앙 집중형 그룹 서버)
- 모든 그룹과 그 멤버십 정보를 데이터베이스에 저장
- Coordinator 또는 Master Node라 불림
장점
- 구조가 단순하고, 구현이 쉬우며 효율적
단점
- 중앙집중형 방식의 공통 단점: 단일 실패 지점이 존재함
Distributed Way (분산 방식)
- 가입 시: 외부 프로세스가 그룹 전체에 메시지를 보내 가입 의사를 알림
- 탈퇴 시: 해당 멤버가 모든 멤버에게 작별 인사 메시지를 보냄
문제점
- 자발적 탈퇴는 명확히 알 수 있으나, 프로세스가 크래시(crash)될 경우는 감지가 어려움
- 다른 멤버들이 해당 프로세스가 응답하지 않음을 통해 실험적으로 판단
- 해당 프로세스가 정말로 죽었는지, 혹은 단순히 느린 것인지를 판단한 후, 그룹에서 제거해야 함
요약
Fault Tolerance (FT)
- 시스템이 부분 실패(partial failure)가 발생하더라도, 전체 성능에 큰 영향을 주지 않고 자동으로 회복할 수 있는 능력
- 분산 시스템 설계의 핵심 목표 중 하나
Stability (Reliability) Quality of System
- Availability: 즉시 사용 가능한 상태
- Reliability: 지속적인 고장 없는 운영
- Maintainability: 고장 시 수리의 용이성
- Safety: 일시적인 오작동 시에도 치명적인 결과가 발생하지 않도록 보장
FT Concepts
- Fault: 오류의 원인
- Error: 시스템 상태 중 실패로 이어질 수 있는 잘못된 상태
- Fail (Failure): 시스템이 서비스 제공을 멈춘 상태
- Fault Tolerance: 오류가 존재하더라도 시스템이 서비스를 지속할 수 있는 능력
FT State Diagram
- 시스템의 상태 전이 관계Normal → Error → Failure
- 오류가 실패로 이어지기 전에 탐지 및 복구가 핵심
Types of Faults
- Transient Fault: 일시적으로 발생 후 사라짐
- Intermittent Fault: 발생과 사라짐을 반복
- Permanent Fault: 복구 전까지 지속되는 영구적인 오류
Failure Models
- Crash Failure: 정상 동작 중 갑자기 중단
- Omission Failure: 응답 누락
- Receive omission / Send omission
- Timing Failure: 응답이 시간 제약 조건을 만족하지 못함
- Response Failure: 잘못된 응답
- Value failure / State transition failure
- Arbitrary Failure (Byzantine Failure): 임의의 잘못된 동작, 때로는 악의적
Redundancy (Failure Masking)
- 장애를 은폐하기 위한 핵심 기술: Redundancy
유형
- Information Redundancy: 오류 복구를 위한 추가 비트 (예: Hamming Code)
- Time Redundancy: 작업을 반복하여 일시적 오류 회피 (예: Transaction 재시도)
- Physical Redundancy: 구성 요소 이중화 (예: 이중화 장비, RAID)
Triple Modular Redundancy (TMR)
- 3개의 동일한 모듈을 병렬 실행
- Majority Voting을 통해 오류 감지 및 무시
- 1개의 오류까지 허용 가능
- 핵심 구성 요소: Voter
Process Group for Process Resilience
- 고가용성을 위한 프로세스 그룹 구성
- 하나의 논리적 단위로 묶어 통신 및 관리를 단순화
- Fault Tolerance를 위해 프로세스 복제 필요
Flat Group
- 대칭적 구조, 단일 실패 지점 없음
- 결정에는 투표 필요 → 복잡도 및 오버헤드 증가
Hierarchical Group
- 중앙 Coordinator 존재
- 단일 실패 지점 존재, 하지만 관리 용이
Group Management (GM)
Centralized Group Management
- Coordinator / Master Node가 모든 그룹 정보와 멤버십을 관리
- 장점: 간단하고 효율적
- 단점: Single Point of Failure
Distributed Group Management
- 참여 요청, 탈퇴 메시지를 멤버 간 직접 전송
- Crash 시에는 탐지를 통해 수동적으로 제거
- 중앙 집중형에 비해 탄력성↑, 복잡성↑
반응형
'CS 지식 > 분산시스템과 컴퓨팅' 카테고리의 다른 글
| [분산시스템] 분산 알고리즘과 Coordinator개념 소개 (Bully Algorithm, Zookeeper Leader) (0) | 2025.04.14 |
|---|---|
| Ceph의 소개와 HDFS와 차이 (0) | 2025.04.03 |
| 빅데이터 처리와 람다 아키텍처 소개(Hadoop) (0) | 2025.04.02 |
| 분산시스템의 아키텍처와 운영체제의 종류 (0) | 2025.03.16 |
| 분산시스템과 컴퓨팅의 소개 (0) | 2025.03.10 |




댓글