
목차
1. 하둡 기반 오픈소스의 시대
2. 하둡의 마스터-슬레이브 아키텍처
3. 병렬처리 구조와 아키텍처 종류, 역사
4. 분산 아키텍처 스타일과 하둡 아키텍처의 진화
5. 하둡 장애처리 전략
6. 하둡 최종 아키텍처⭐️
1. 하둡(Hadoop) 기반 빅데이터, AI, 오픈소스 시대
- 과거에는 기업들이 하둡 기반의 시스템들을 오픈소스로 구현해 사용했음.
- 예를 들어 LG 같은 기업도 자체 솔루션을 만들어 활용했음.
- 다양한 기업들이 각자의 하둡 기반 솔루션을 만들어 쓰다가, 어느 시점부터는 내부 시스템으로 정착되어 외부 관심에서는 사라지게 됨.
- 하지만 "사라졌다고 해서 사용하지 않는 것이 아니라", 오히려 내부적으로 안정된 솔루션으로 계속 사용 중임.
AI 시대에서도 하둡은 살아 있다
- 지금은 AI 시대이며, 대부분의 분석 및 모델링 도구가 PyTorch나 TensorFlow로 옮겨갔음.
- 과거에는 Spark 내부에 ML 모듈을 결합해 하둡 기반에서도 AI 처리를 시도했지만, 현재는 Spark보다는 PyTorch나 TensorFlow가 대세로 자리잡음.
- 그러나 데이터 처리 측면에서는 여전히 하둡 기반 인프라(HDFS 등)가 사용되고 있음.
- 예: AI 학습 데이터를 처리하거나 저장하는 데 여전히 HDFS를 활용함.
하둡을 활용하는 산업의 예
- 금융권에서는 여전히 CEP(Complex Event Processing) 시스템을 사용함.
- 예: Esper
- SK텔레콤 같은 기업은 전화 통화 데이터(Call Data)를 분석하는 데에도 이 CEP를 활용함.
- 실시간으로 들어오는 데이터는 CEP로 분석하여 실시간 알림, 통계 등에 사용됨.
머신러닝과 딥러닝의 데이터 처리 단계
데이터 처리의 기본 흐름은 다음과 같음:
- 수집 (Collect)
- 저장 (Store)
- 변형/전처리 (Transform / Preprocessing)
- 분석 (Analyze)
- 모델링 (Modeling)
- 추론 (Inference)
머신러닝에서는 이 과정이 분석과 모델링 단계로 나뉨. 저장된 데이터를 그대로 사용할 수 없기 때문에, 반드시 전처리(Preprocessing) 단계가 필요함.
전처리에서는 다음과 같은 작업을 수행함:
- 이상치 제거
- 결측값 처리
- 스케일링
- 특징 추출 등
하둡 기반의 전처리 시스템
- 전처리 시스템도 하둡 기반으로 구성됨.
- Hadoop 기반 분산 저장소(HDFS) 위에 데이터를 올리고, 분석은 Spark 등으로 수행하거나, 다른 시스템과 연동함.
- 요즘에는 딥러닝 시스템이 end-to-end로 데이터를 학습에 사용하기 때문에, 과거처럼 분석 단계가 명시적으로 분리되진 않지만, 전처리의 필요성은 여전히 존재함.
실시간 데이터와 추론(Real-time Inference)
- 예시: 비행기 센서 데이터 → 실시간으로 인식해서 물체를 추적함.
- 이처럼 실시간 추론(inference) 이 필요한 영역에서는 모델이 서버나 디바이스에서 바로 동작해야 함.
- 예시: 스마트폰 음성비서, 실시간 번역 앱 등
- 사용자가 말하면 바로 응답 → 지연 시간(latency) 이 중요한 요소
- 실시간 시스템은 크게 두 종류로 나뉨:
- Human Real-time: 사람이 기다릴 수 있는 시간(보통 3초 이내)
- Hard Real-time: 미션 크리티컬 시스템 (항공기, 철도 제어 등 → 0.1초 이하 지연도 치명적)
실시간 시스템과 메시지 포맷의 효율성
- 시스템에서 메시지를 전송할 때, 포맷도 중요함:
- XML: 무겁고 느림 (300ms 이상 걸릴 수 있음)
- JSON: 가볍고 빠름 (구조화된 키-값 형태)
- 구조: {"key": value} 형태로 누구든 쉽게 해석 가능
- 프레임워크(Spring 등)가 파싱해서 내부 객체로 전달
- JSON의 특징:
- Semi-structured (반구조화 데이터)
- 전송/수신하는 쪽은 데이터 내용을 몰라도 되고, 프레임워크가 알아서 처리함 (예: Spring의 ObjectMapper)
AI 시대, 저장소와 데이터의 변화
- 과거에는 저장소 비용이 비싸서 데이터를 통계적으로 요약하거나 줄이는 방식이 일반적이었음.
- 지금은 저장소가 매우 저렴해짐 → Raw 데이터를 그대로 저장하는 게 기본
- 예: 영상, 이미지, 로그 데이터 등 비정형 데이터 (Unstructured Data)
- AI가 발전하면서 데이터가 많을수록 좋다는 인식이 보편화됨 → 모든 걸 저장하고, 나중에 필요한 데이터만 꺼내 사용
- 이를 가능하게 해주는 기술: 분산 파일 시스템
- 예전에는 HDFS(Hadoop Distributed File System)를 썼지만,
- 요즘은 Ceph 같은 고성능 분산 파일 시스템이 더 많이 쓰임
YARN과 MapReduce의 관계

YARN (Yet Another Resource Negotiator): 하둡의 리소스 관리 시스템
- 클러스터의 CPU, 메모리 등의 자원을 관리함
- 데이터 처리 프로그램(MapReduce, Spark 등)이 YARN 위에 올라가는 구조
MapReduce: YARN 위에서 실행되는 데이터 처리 프레임워크
- YARN이 자원을 배정해주고, MapReduce는 실제 데이터를 처리
💡 구조적으로:
- YARN은 리소스 매니저
- MapReduce는 프로세싱 프레임워크
- MapReduce는 YARN의 API를 통해 클러스터 노드에 작업을 분산 실행함
실시간 처리 vs 미션 크리티컬 시스템
- Spark 같은 프레임워크도 실시간 처리를 지원하지만, 미션 크리티컬 시스템에는 적합하지 않음.
- 🔍 미션 크리티컬 시스템이란?
- 결과가 늦거나 틀리면 사람의 생명에 영향을 미치는 시스템
- 예: 비행기 조종, 열차 제어, 병원 의료 장비 등
- 반면 우리가 사용하는 Spark 같은 시스템은 "휴먼 리얼타임" 수준
- 예: 사용자가 버튼을 클릭했을 때 3초 안에 결과가 오는 수준
- 사람은 보통 3초까지는 기다릴 수 있음 → 이를 3초 룰이라고도 함
- 📌 요약:
- Spark: Human Real-time (사용자 응답 기준)
- 항공/의료: Hard Real-time (지연 허용 불가)
2. 하둡의 Master-Slave 구조
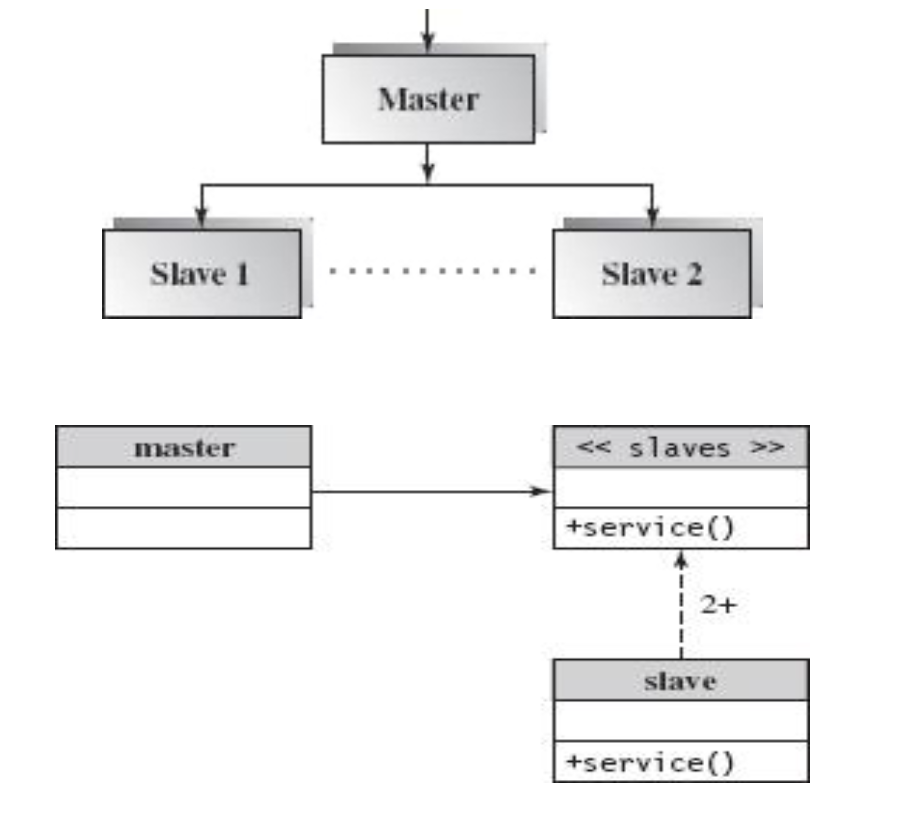
- Master-Slave 구조는 분산 처리 시스템에서 많이 사용되는 기본 아키텍처
- Master: 작업을 분배하고 결과를 수집
- Slave: 작업을 수행하고 결과를 Master에 반환
- MapReduce도 이 구조를 따름
- 예: Mapper/Reducer 작업을 슬레이브들이 수행하고 결과를 Master가 수집
- API 호출 구조:
- 위에서는 Master가 send() 등의 API로 데이터를 각 노드(Slave)로 전송
- 하단 노드는 어떤 노드인지를 몰라도 투명하게 메시지를 받아 처리함 → Transparently distributed 구조
Hadoop 시스템에서 Master의 역할
1. 병렬 처리 수행 (Parallel Computing for Big Data Processing)
- 빅데이터를 병렬로 처리하기 위한 작업 분배
- Mapper / Reducer 등의 Task를 Slave 노드에게 분산
- SPMD 모델 기반 병렬 처리 구조 구성
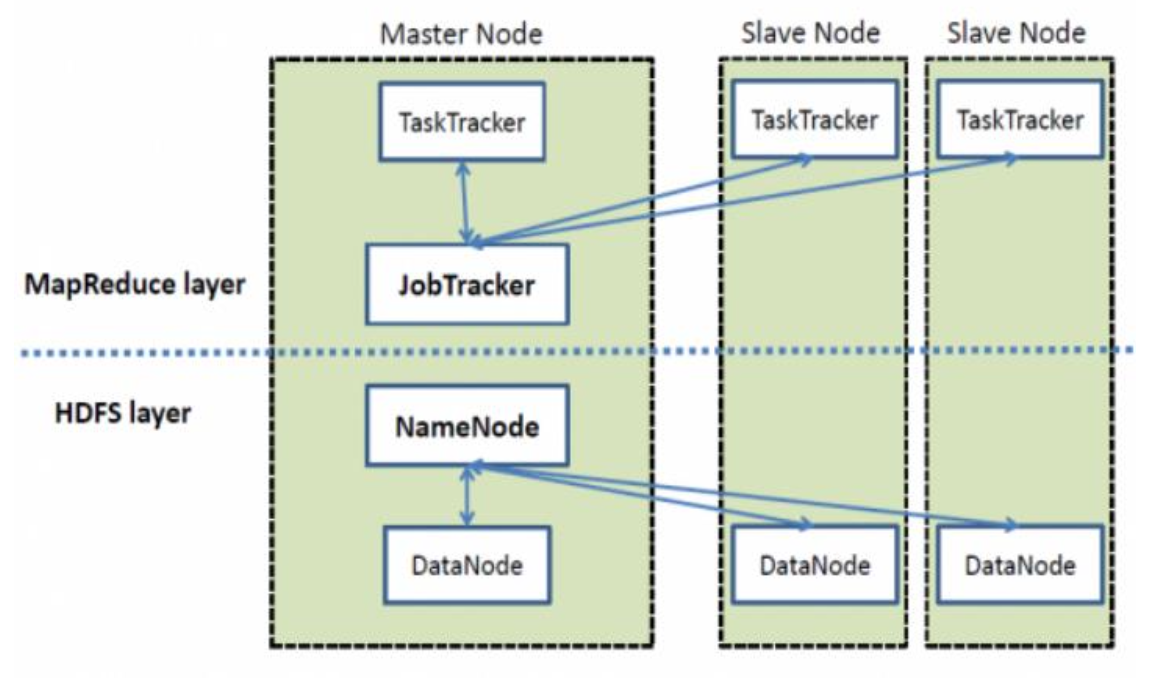
- Hadoop 1.0 기준: JobTracker가 이 역할을 담당함
2. 분산 저장소 인덱스 관리 (Index Service for Big Data Storage)
- 파일 시스템 상의 데이터를 추적하기 위한 메타데이터 관리
- 어떤 데이터가 어느 노드에 저장되어 있는지를 파악
- Hadoop의 HDFS에서 NameNode가 이 역할 수행
3. 장애 복구 및 장애 허용 기능 (Fault Tolerance and Failure Recovery)
- 노드 장애 감지 및 작업 재할당
- 체크포인트 저장 / 복제본 관리 / 상태 동기화 등
- YARN의 ResourceManager와 HDFS의 Secondary NameNode가 관련 기능 수행
Hadoop 1.0에서는 이 3가지 역할을 JobTracker 단일 구성요소가 수행
- 병렬 처리 + 리소스 관리 + 장애 복구를 모두 JobTracker 하나가 담당
- 그 결과, 역할 과부하로 인해 단일 장애 지점(SPOF) 발생 가능성 증가
- → 이 문제로 인해 Hadoop 2.0에서는 역할 분리를 도입
Hadoop 2.0 이후의 역할 분리 구조
| 역할 | 담당 컴포넌트 |
| 병렬 처리 | ApplicationMaster (YARN) |
| 자원 관리 | ResourceManager (YARN) |
| 저장소 인덱스 | NameNode (HDFS) |
| 장애 복구 / Fault-Tolerance | ResourceManager + Standby Nodes |
→ Separation of Concerns (관심사의 분리) 를 통해 아키텍처의 확장성, 안정성, 유지보수성을 확보함
병렬 처리 시스템과 스케줄링 문제
Master가 모든 작업을 Slave들에게 나눠주고 기다림 모든 Slave가 작업을 완료할 때까지 기다려야 다음 단계로 넘어감
- → 가장 느린 Slave가 전체 시스템의 속도를 결정함
- 이를 Late Node Problem이라고 함
해결 방안:
- 비동기 처리(Asynchronous Processing)
- 빠른 노드부터 결과 수집하고, 늦은 노드는 결과만 뒤늦게 반영
병렬화 전략이 중요한 이유:
- 데이터 처리의 효율성
- 시스템 자원의 최적화
- 사용자 응답 시간 단축
3. 병렬처리 구조와 아키텍처
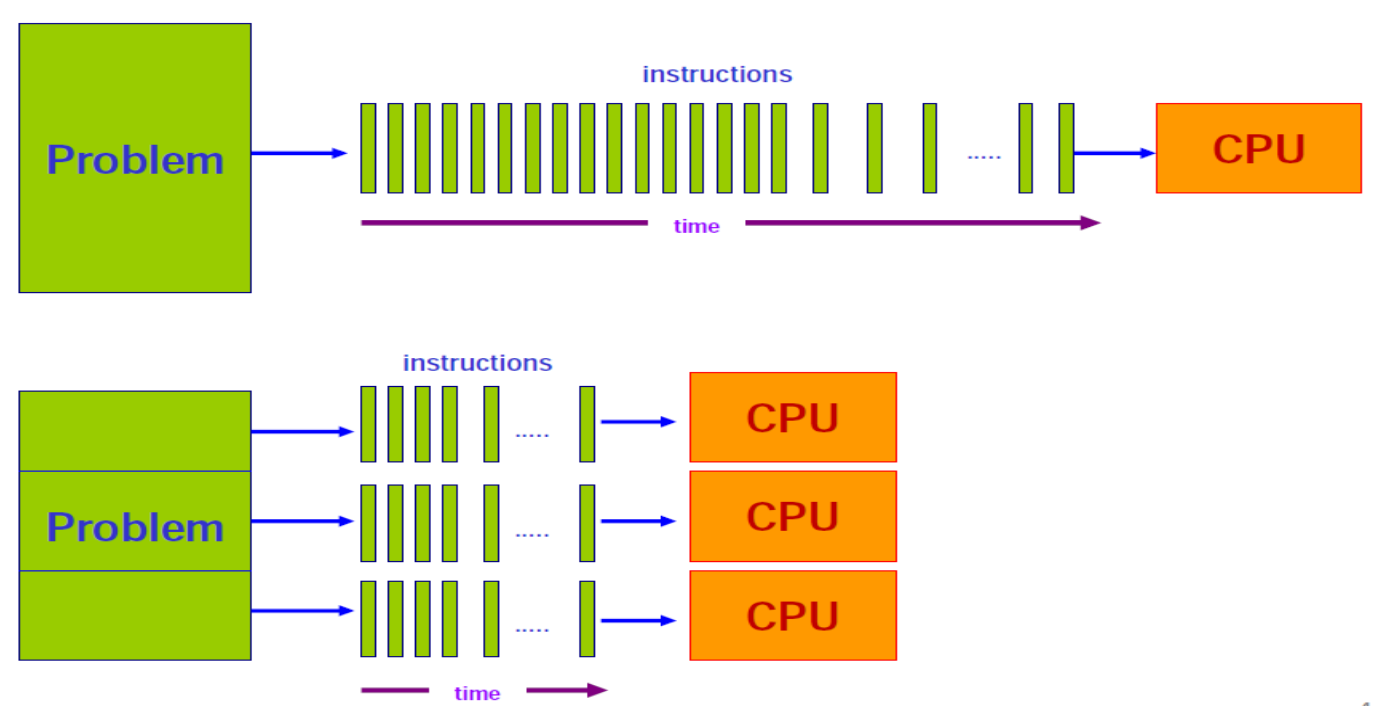
병렬처리는 여러 작업을 동시에 수행하여 처리 속도를 높이는 방식이다.
병렬 처리 시스템의 구성 요소
- P (Processor): 병렬로 작업을 수행하는 유닛
- M (Memory): 데이터와 명령어를 저장
- C (Controller): 명령어를 제어하는 장치
- IS (Instruction Stream): 처리 명령어의 흐름
메모리 구조
- 로컬 메모리 vs 공유 메모리
- 공유 메모리를 사용할 경우, 서로 다른 노드가 동일 데이터를 읽고 쓸 수 있음
- 메모리 구조에 따라 병렬 처리 방식이 달라짐
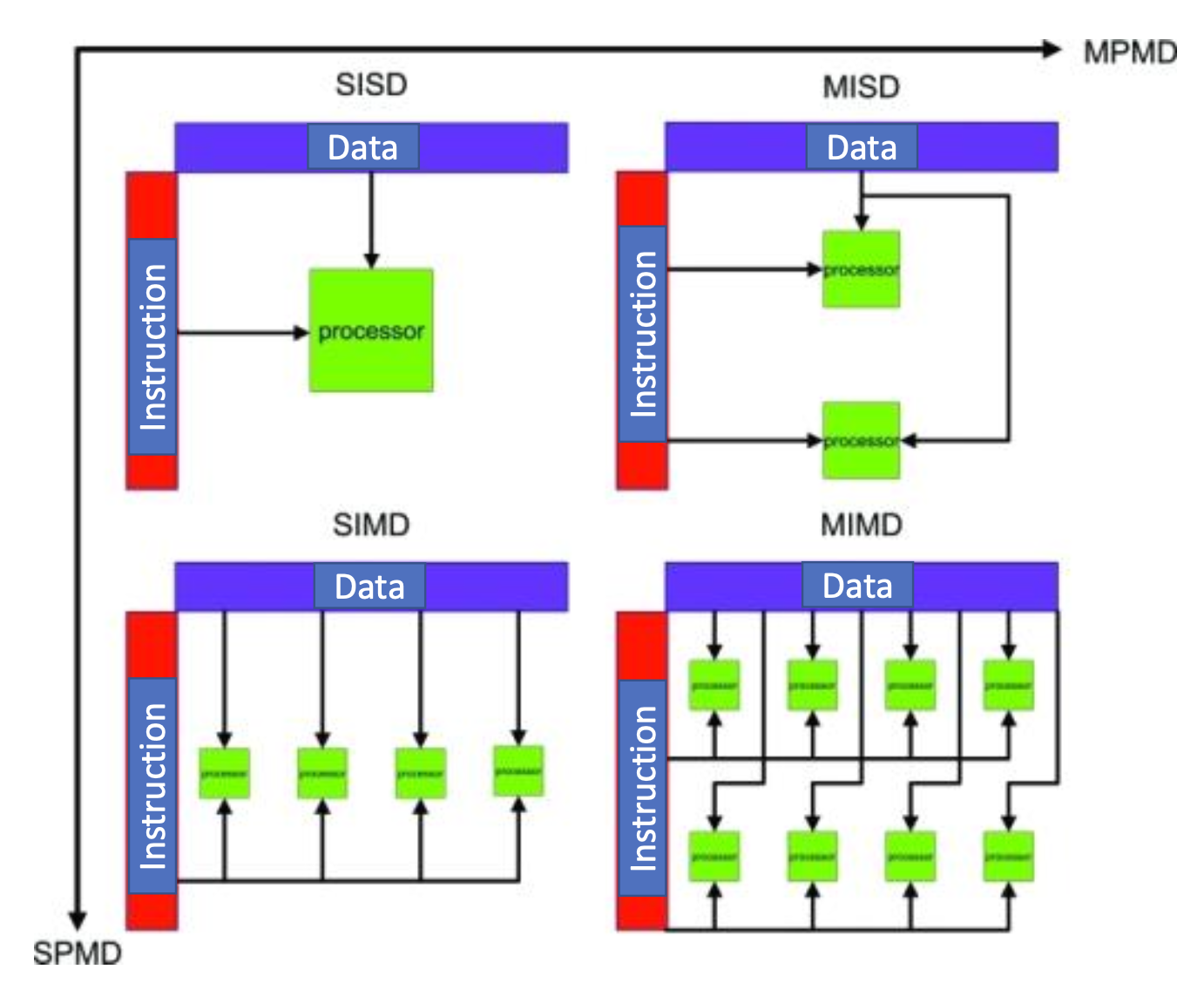
병렬 처리 아키텍처의 4가지 분류
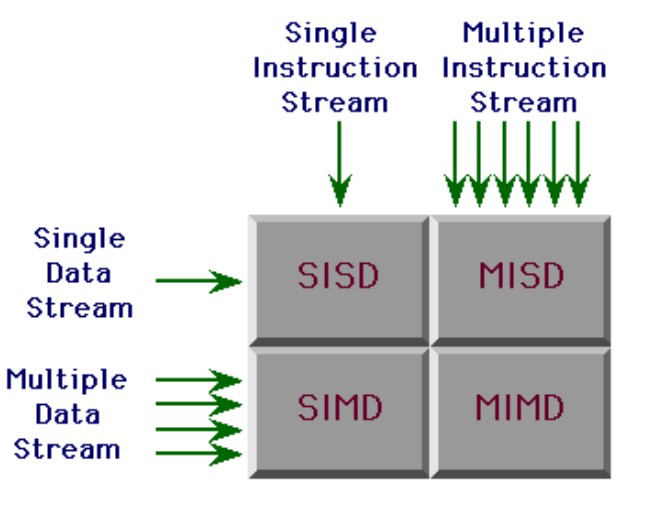
병렬 처리 구조는 Flynn의 분류에 따라 크게 4가지로 나뉨:
1. SISD (Single Instruction Single Data)
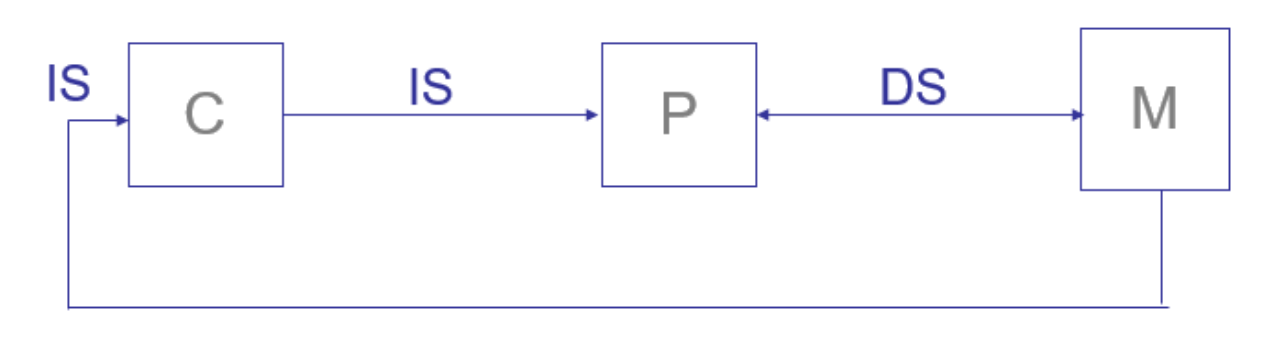
- 단일 명령어, 단일 데이터 스트림 처리
- 직렬(Serial) 컴퓨터 구조
- 병렬 처리 불가능 (비병렬)
- 결정적 실행(Deterministic Execution): 동일 입력에 대해 항상 동일한 결과 출력
- 예시: 전통적인 단일 코어 프로세서
2. SIMD (Single Instruction Multiple Data)
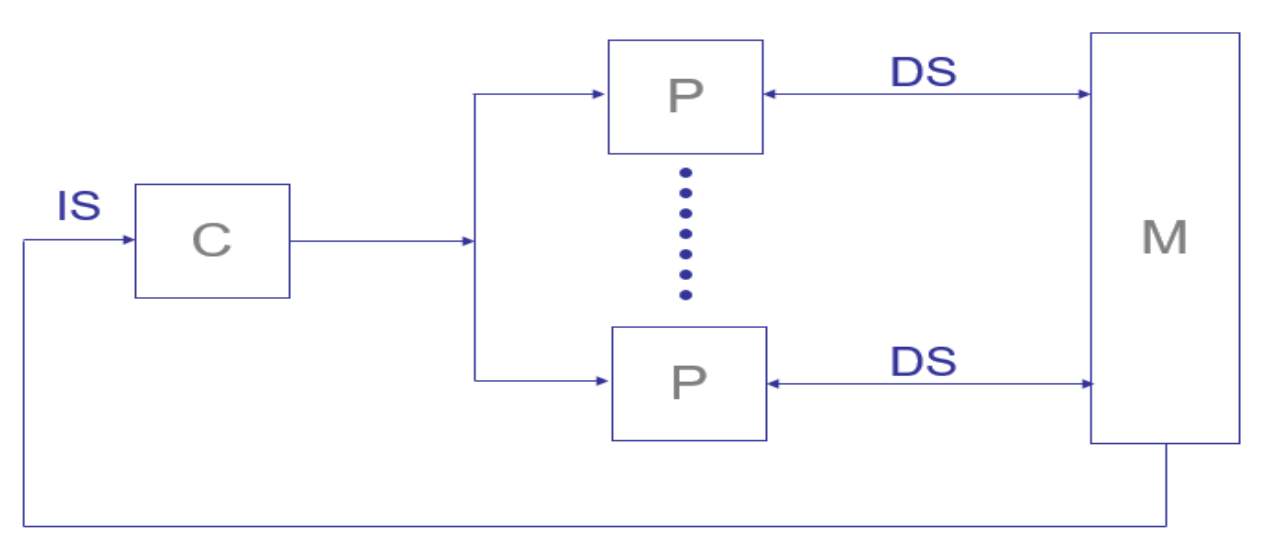
- 단일 명령어로 다수의 데이터를 동시에 처리
- 병렬 컴퓨터 구조의 한 형태
- 동기적(Synchronous) 실행: 모든 유닛이 동시에 동작
- 결정적 실행 가능
- 고도의 규칙성이 있는 문제에 적합 (예: 그래픽, 이미지 처리)
- 대부분의 현대 CPU/GPU에 SIMD 명령어셋 존재
- 예시: GPU, 벡터연산
3. MISD (Multiple Instructions Single Data)
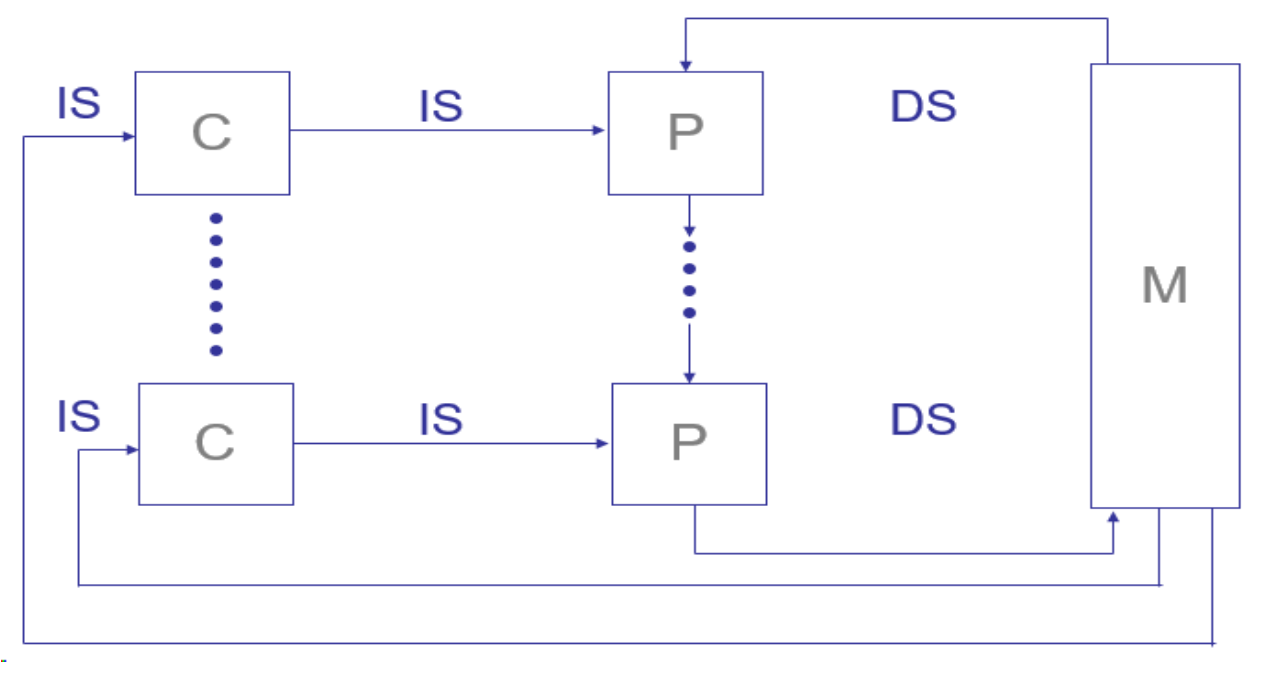
- 단일 데이터 스트림을 여러 개의 명령어 흐름이 동시에 처리
- 각 처리 유닛은 독립적인 명령어 흐름을 사용하여 동일 데이터를 처리
- 매우 드문 구조로 실질적인 상용 시스템은 거의 없음
- 일부 안정성 보장 시스템(fault-tolerant system)에 사용
- 예시: 필터 체계, 이메일 스팸 처리
4. MIMD (Multiple Instructions Multiple Data)
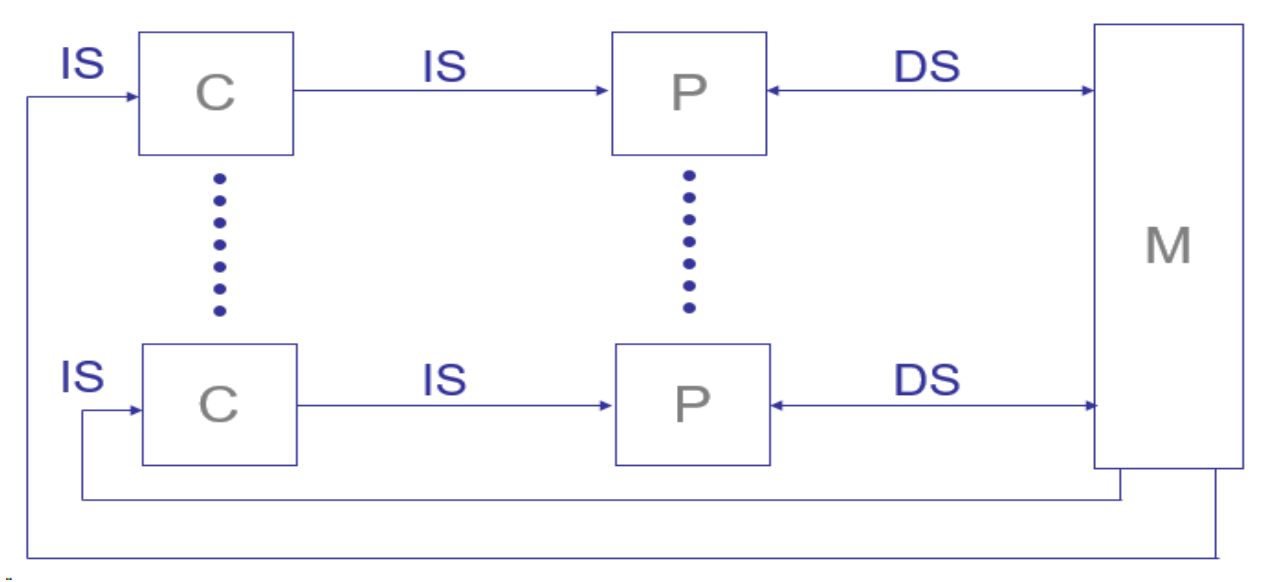
- 다중 명령어 흐름과 다중 데이터 스트림을 동시에 처리
- 가장 일반적인 병렬 컴퓨팅 구조
- 동기적 또는 비동기적, 결정적 또는 비결정적 실행 가능
- 대부분의 슈퍼컴퓨터, 클러스터 기반 병렬 컴퓨팅 시스템에서 사용
- 많은 MIMD 시스템은 내부적으로 SIMD 기능을 포함하기도 함
- 예시: 게임 서버, 멀티 컴퓨터 시스템
🔍 비교 요약
| 분류 | 명령어 흐름 | 데이터 흐름 | 병렬성 | 예시 |
| SISD | 1 | 1 | X | 단일 코어 프로세서 |
| SIMD | 1 | 다수 | O | GPU, 벡터 프로세서 |
| MISD | 다수 | 1 | O* | 신뢰성 기반 시스템 (드뭄) |
| MIMD | 다수 | 다수 | O | 슈퍼컴퓨터, 멀티코어 CPU |
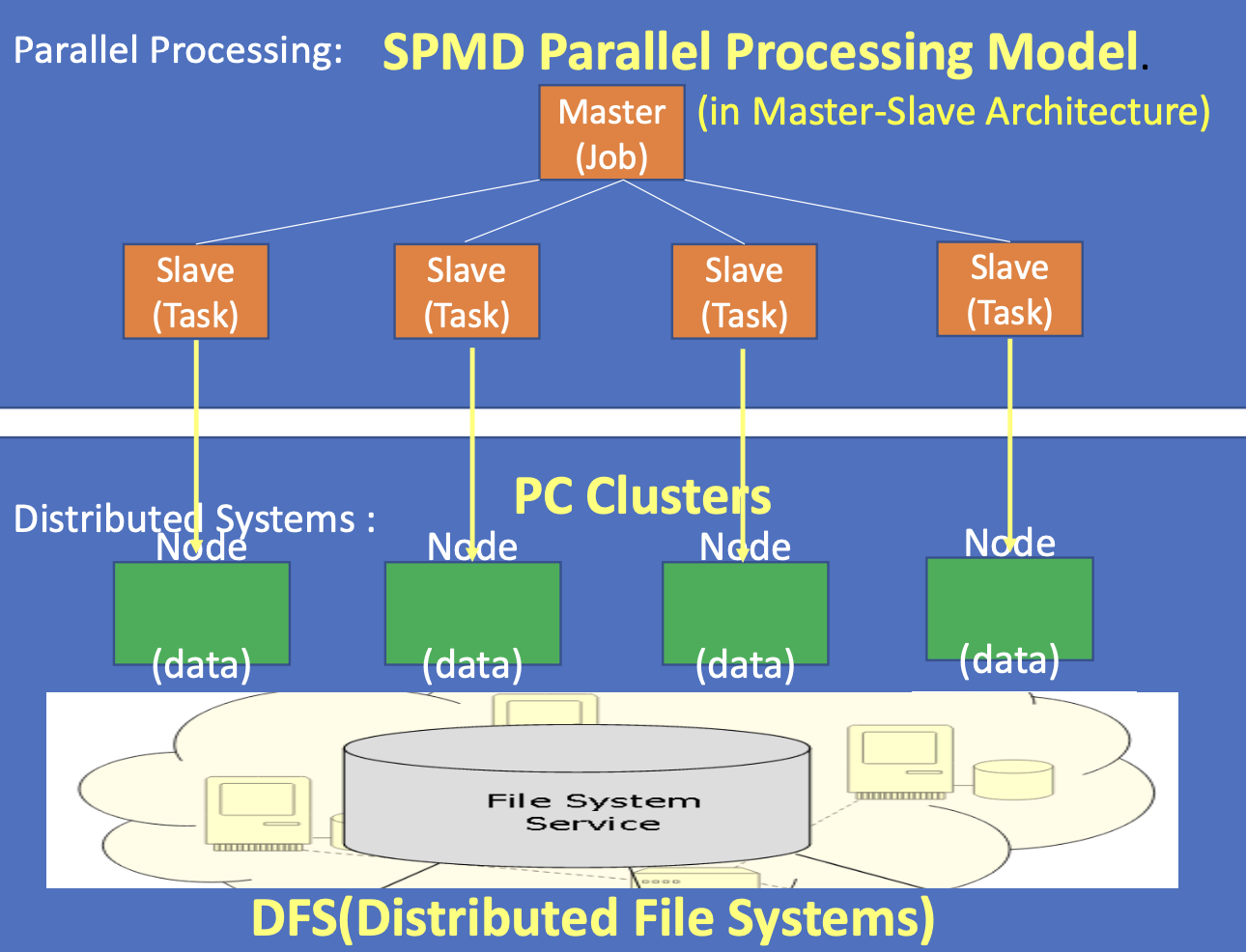
예1. 하둡의 병렬 처리 모델 (SIMD -> SPMD 구조 예)
- 하둡은 SPMD (Single Program, Multiple Data) 모델을 채택함
- 하나의 프로그램(Mapper 또는 Reducer)을 여러 노드에 배포해서 서로 다른 데이터를 병렬로 처리
- 예: 하나의 Mapper 프로그램을 여러 입력 파일에 대해 병렬 실행
구조적으로는 SIMD에서 출발한 개념이지만, 실행 단위는 프로그램이므로 SPMD에 가깝다
예2. 메시징 큐에서의 병렬 처리 (MISD 구조 예)
이메일 서버와 같은 필터 체계 Kafka 등의 메시징 큐에서 데이터가 들어오면:
- 1단계: 스팸 제거
- 2단계: 광고 필터링
- 3단계: 유해 콘텐츠 필터링
- 하나의 데이터가 여러 단계를 거쳐 처리됨 → MISD
Granularity (세분화 수준)의 중요성
- 병렬 처리는 어떤 수준에서 작업을 나눌 것인가가 중요함
| Granularity 수준 | 설명 |
| Instruction-level | 명령어 단위 병렬화 |
| Thread-level | 스레드 단위 병렬화 |
| Task-level | 태스크(작업) 단위 병렬화 |
| Process-level | 프로세스 단위 병렬화 |
| Program-level | 프로그램 단위 병렬화 (→ 하둡의 방식) |
- 하둡은 프로그램 단위 병렬화(Process-level) 방식으로 각 작업(Map 또는 Reduce)을 클러스터에서 병렬로 실행함
병렬 처리 기술의 역사와 흐름
과거: OS 수준에서 병렬 처리 구현
- 머신 리소스가 부족했던 시절에는 운영체제(OS) 수준에서 병렬 처리 구현
- 1980년대~90년대에는 직접 하드웨어 제어 수준에서 프로그래밍이 이루어짐
현재: 시스템 레벨에서 병렬 처리 가능
- 하드웨어 성능 향상으로 OS 위에서도 병렬 처리 구현 가능해짐
- 병렬 처리를 위한 다양한 기술이 등장
대표 기술: GPU, CUDA
- GPU는 병렬 처리에 특화된 하드웨어
- CUDA는 NVIDIA가 만든 병렬 처리 API
- 벡터 단위 연산(SIMD 기반)을 빠르게 처리할 수 있음
4. 아키텍처 스타일
아키텍처 설계에서 구조를 구성하는 기본 틀을 아키텍처 스타일(Architecture Style) 이라고 함. 분산 시스템의 주요 스타일은 다음과 같음.
1. Layered Architecture (계층형 아키텍처)
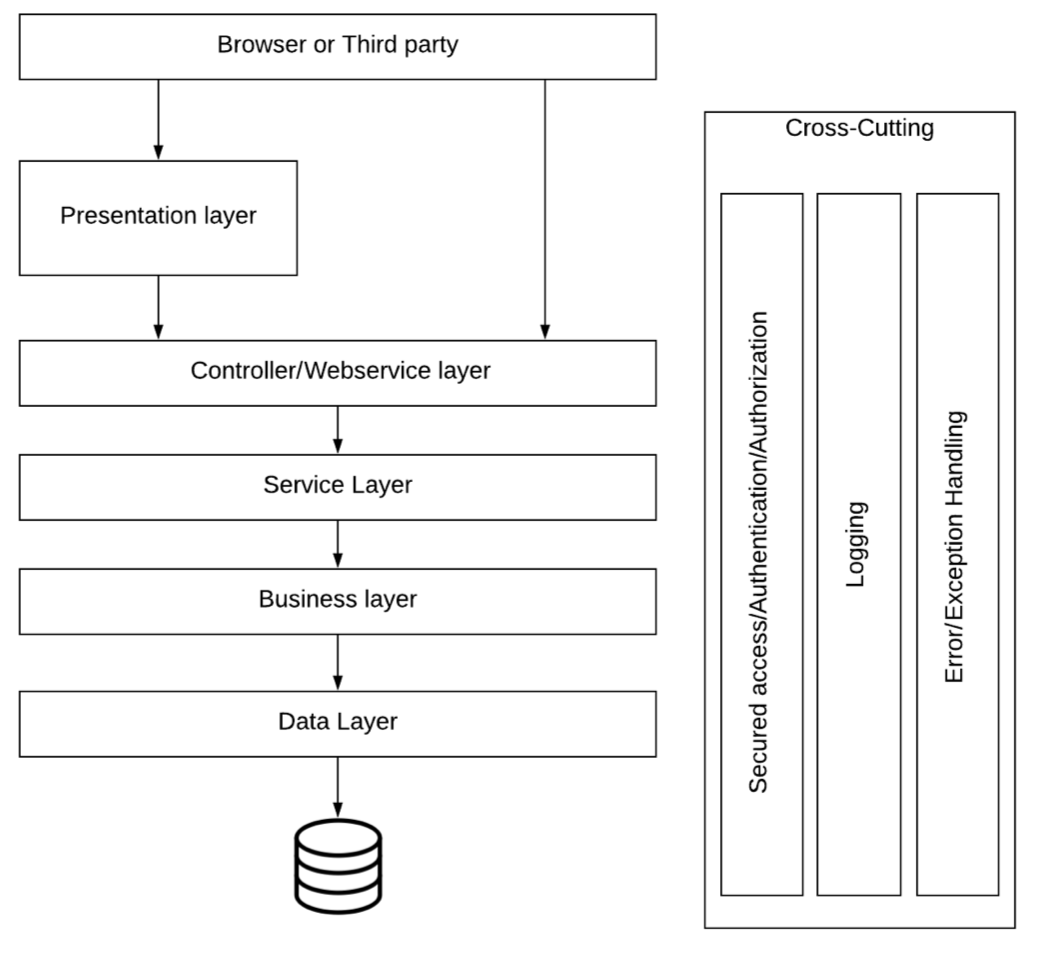
- 가장 기본적이고 보편적으로 사용되는 구조
- 각각의 계층은 서로 명확히 구분되며, 독립적인 책임(Sole Responsibility)을 가짐
- 예: Presentation Layer, Service Layer, Business Layer, Data Access Layer
Spring 프레임워크는 이 구조를 따름.
- 사용자의 요청 → Controller → Service → DAO → DB 순으로 계층적으로 흐름이 이동
특징:
- 각 레이어는 내부적으로 여러 클래스(패키지)로 구성됨
- 각 레이어는 자체 책임을 가지고 있으며, 추상화와 캡슐화가 적용됨
- 표준화된 인터페이스를 통해 레이어 간 통신함
2. Microkernel Architecture (마이크로 커널 아키텍처)
- OS 구조에서 자주 등장함
- 핵심 기능은 커널에서 수행하고, 나머지 기능은 별도 모듈로 분리하여 필요 시 추가함
- 안드로이드 시스템이 대표적인 예:
- Java/C 기반의 모듈이 레이어드 구조로 구성되고, 그 중간에 Microkernel이 위치함
3. Microservices Architecture (MSA)
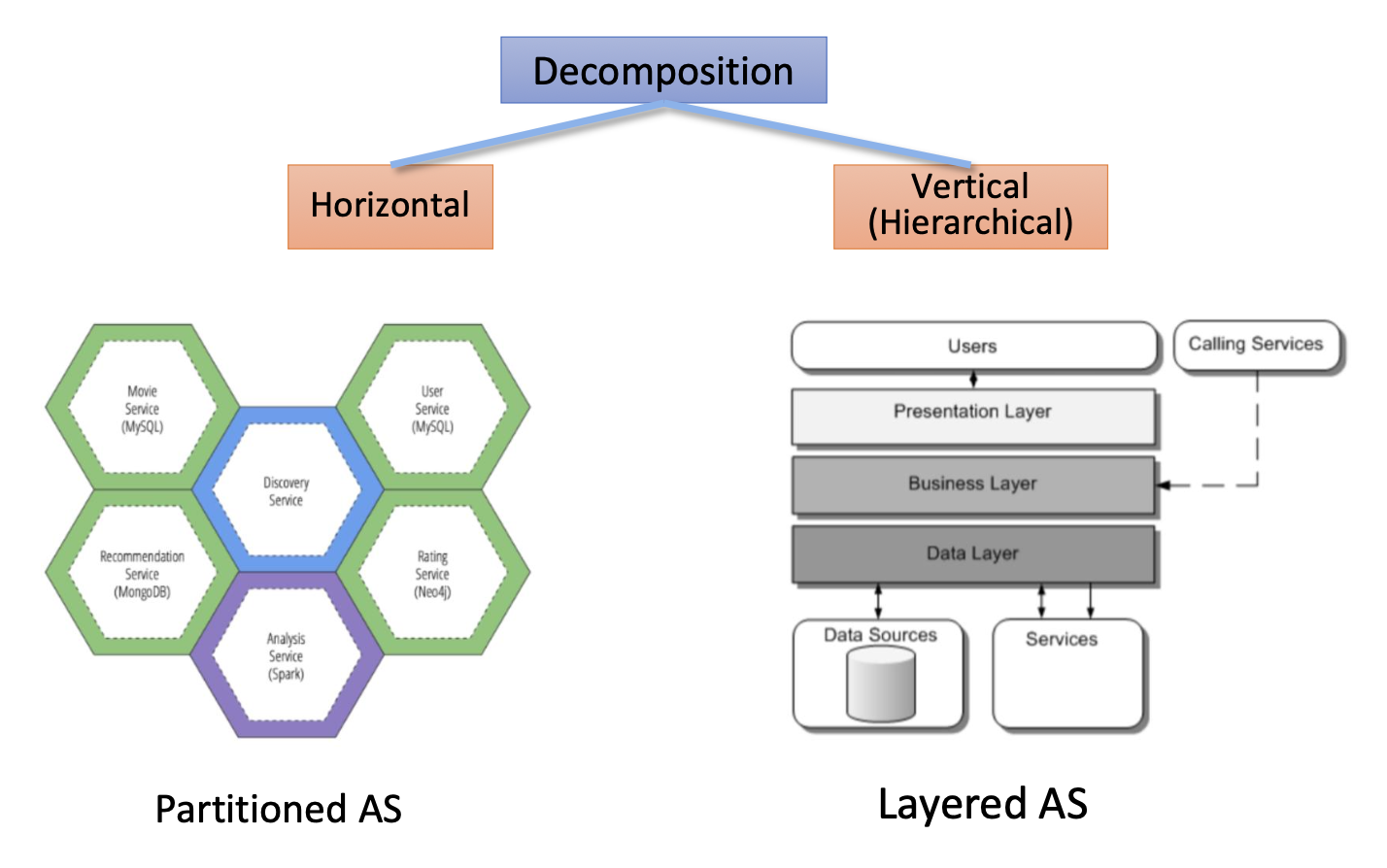
- 기존 SOA(Service-Oriented Architecture)를 더욱 작고 가볍게 분해한 구조
- 서비스 하나를 작게 쪼개어 독립적으로 배포, 실행, 확장할 수 있음
- REST API를 통해 통신하고, 컨테이너 기반 배포에 적합
- 최근의 시스템들은 대부분 MSA로 구현되는 추세
이전에는 모든 시스템을 하나의 큰 서비스로 만들었지만, 지금은 시스템이 충분히 빠르기 때문에 여러 개의 작은 서비스를 띄워도 무방함
하둡 아키텍처의 진화
Hadoop 1.0
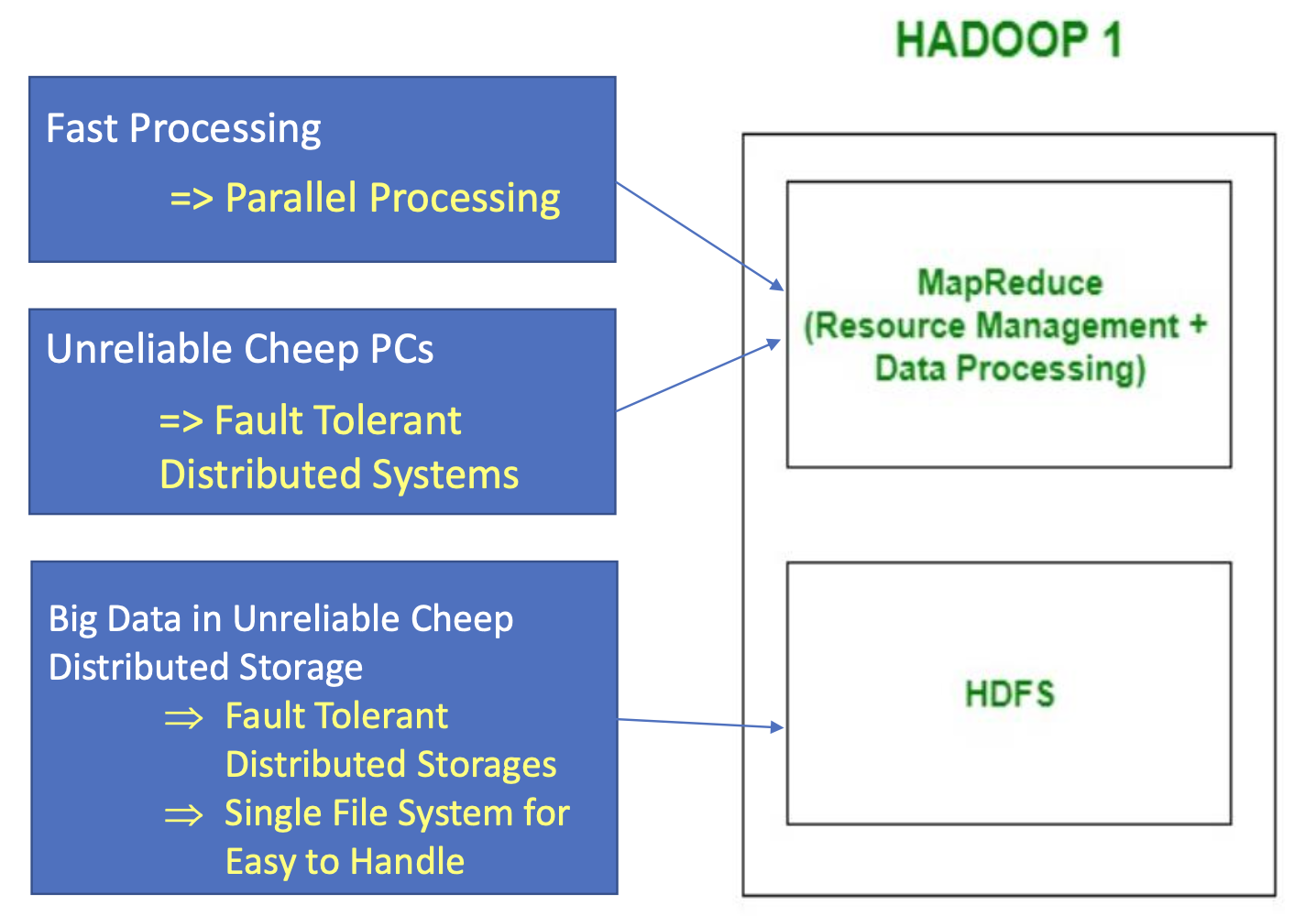
- 단일 마스터 구조
- MapReduce와 HDFS가 서로 강하게 결합되어 있었음
- 구조가 단순하지만, 확장성과 장애 대응에 한계가 있었음
Hadoop 2.0
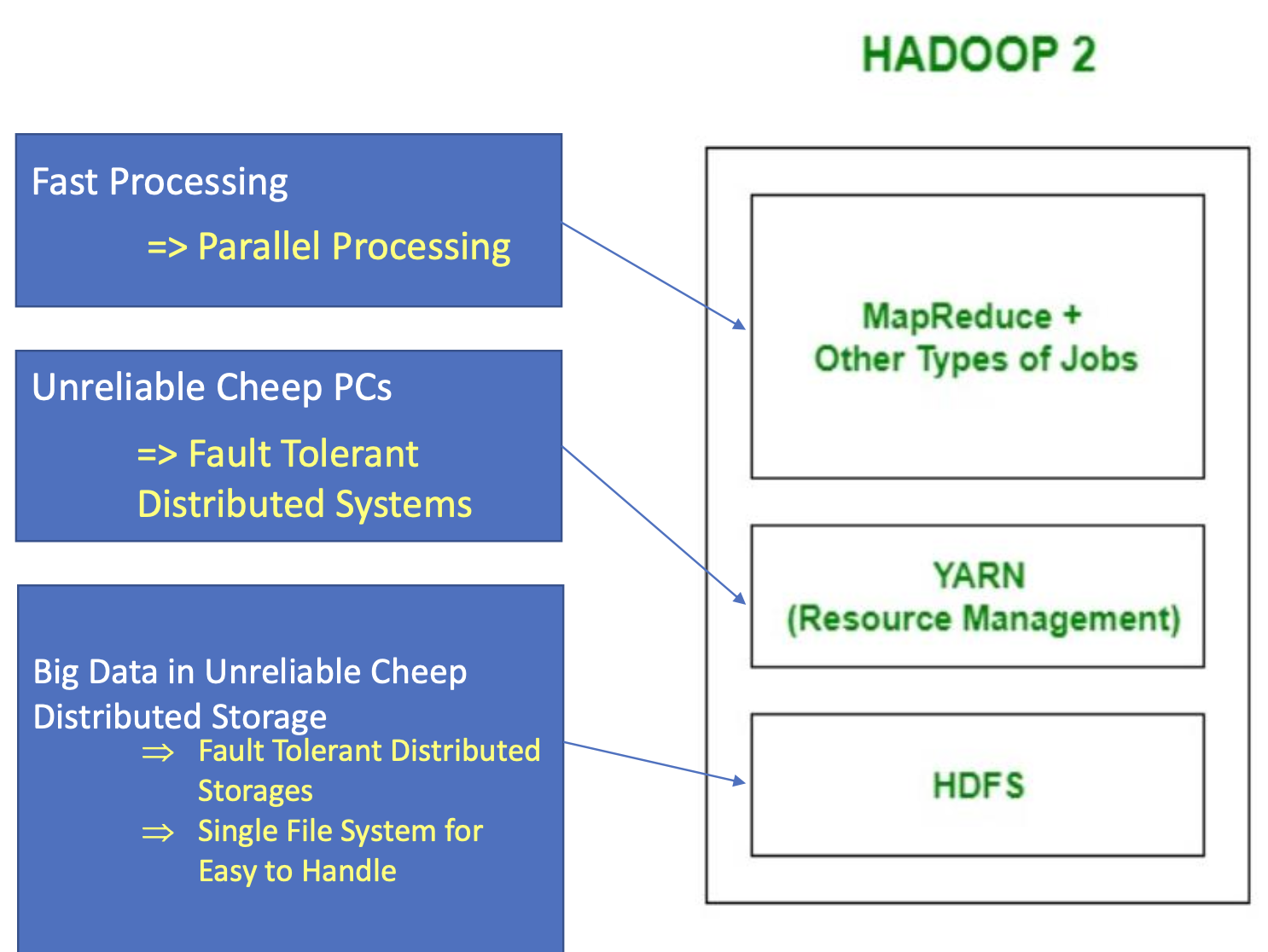
- YARN 도입: 자원 관리와 데이터 처리를 분리
- MapReduce가 YARN 위에서 동작하는 구조로 변경됨
- Master-Slave 구조에 Spare Master 추가:
- Master에 장애가 발생하면 대체 Master가 자동으로 takeover 가능
Hadoop 2.5
- 처리 구조를 더욱 분리하고, 안정성 강화
- 분산 처리와 분산 저장의 모듈화가 강화됨
- HDFS는 계속 사용되었고, 위쪽 처리 계층은 유연하게 교체 가능하게 설계됨
이 구조는 오픈소스로 공개된 후, 전 세계 연구자들이 붙어서 개선함
- 논문, 구현 등 활발한 기여가 이루어짐
오픈소스 생태계와 발전 방식
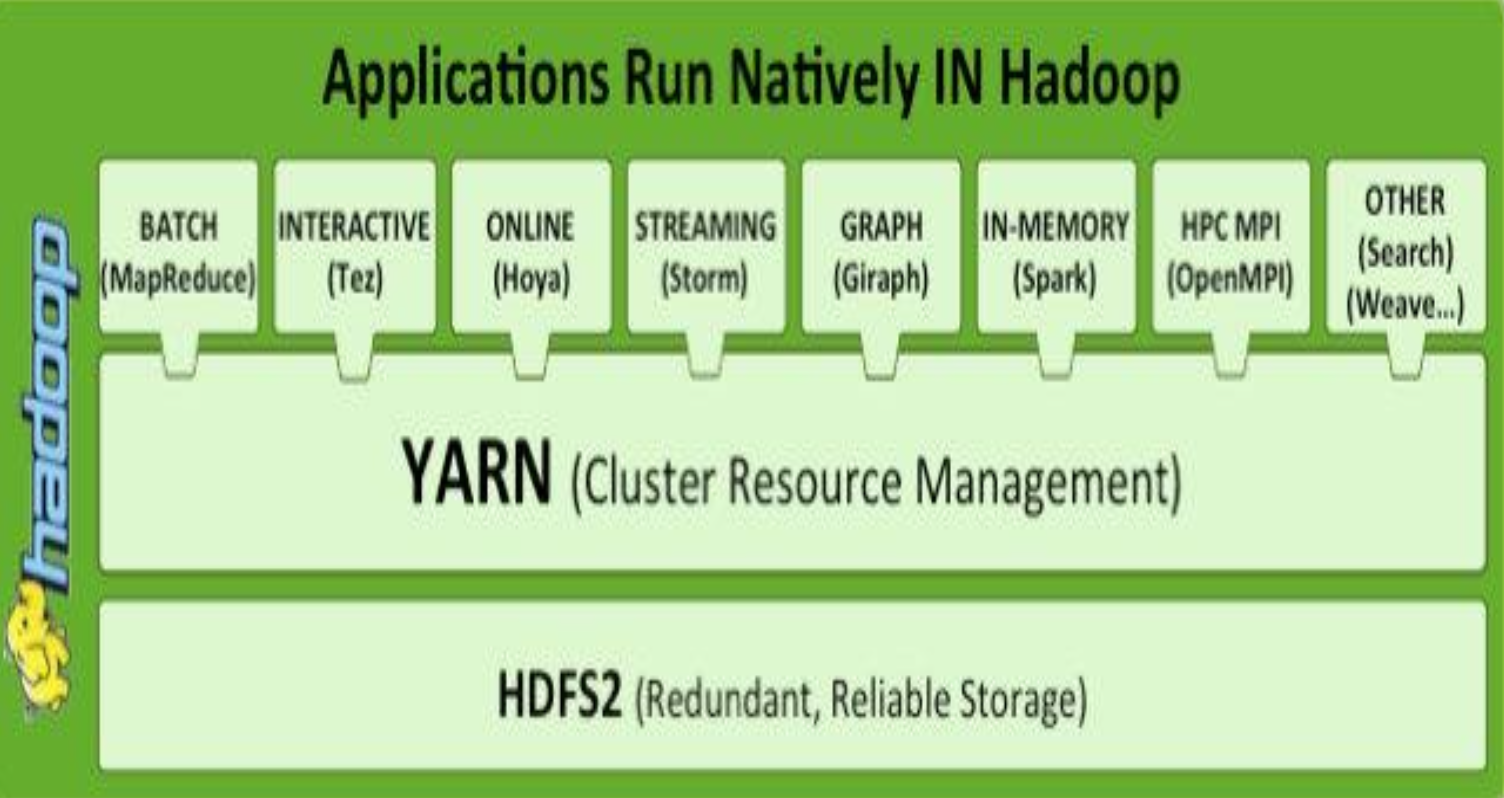
- 하둡이 오픈소스로 공개되자, 다양한 프레임워크들이 이 위에 붙기 시작함
- 예: Hive, Pig, Spark, Flink 등
- 생태계가 확장되면서 하둡은 빅데이터 플랫폼의 중심이 되었음
브라우저의 예시와 유사:
- 과거에는 Internet Explorer가 주류였으나, 구글이 공개한 크롬이 대세가 됨
- 크롬의 기반은 Netscape 오픈소스였고, 아파치 라이선스 덕분에 자유롭게 수정 가능했음
5. 장애 처리 전략 (Fault Tolerance)
분산 시스템은 언제든 노드가 죽거나 응답하지 않을 수 있으므로, 아래와 같은 전략이 필요함.
주요 전략들
- Redundant Spare: 예비 노드를 두어 하나가 죽으면 대체 노드가 즉시 대기
- Retrying: 실패한 작업을 다시 시도
- Recovery: 체크포인트 등을 활용하여 중단된 지점부터 복구
- Proactive Handling: 장애가 생기기 전에 미리 진단하거나 예방 (예: 리소스 과부하 감지)
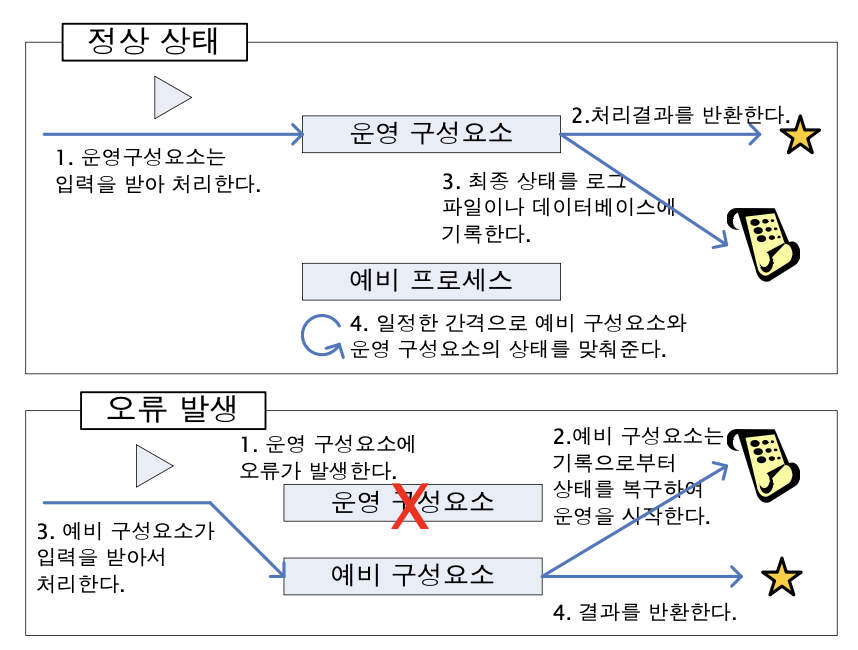
하둡 사례
- MapReduce에서 특정 슬레이브가 응답하지 않으면:
- 마스터는 해당 노드에 핑을 보내 확인
- 응답이 없으면 해당 작업을 다른 노드에 재할당
- 단, MapReduce 자체는 노드 상태를 항상 감지하지 않음
- 이 기능은 YARN 같은 리소스 매니저가 담당함
Crosscutting Concerns (횡단 관심사)
- 암호화, 예외 처리, 로깅, 인증 등은 모든 레이어에 영향을 주는 공통 기능
- AOP (Aspect-Oriented Programming)를 통해 분리하여 처리
6. 하둡 최종 아키텍처
빅데이터 분산 시스템을 구성하기 위한 3계층(layered) 아키텍처 구조는 다음과 같다
1. Parallel Processing Layer (병렬 처리 계층)
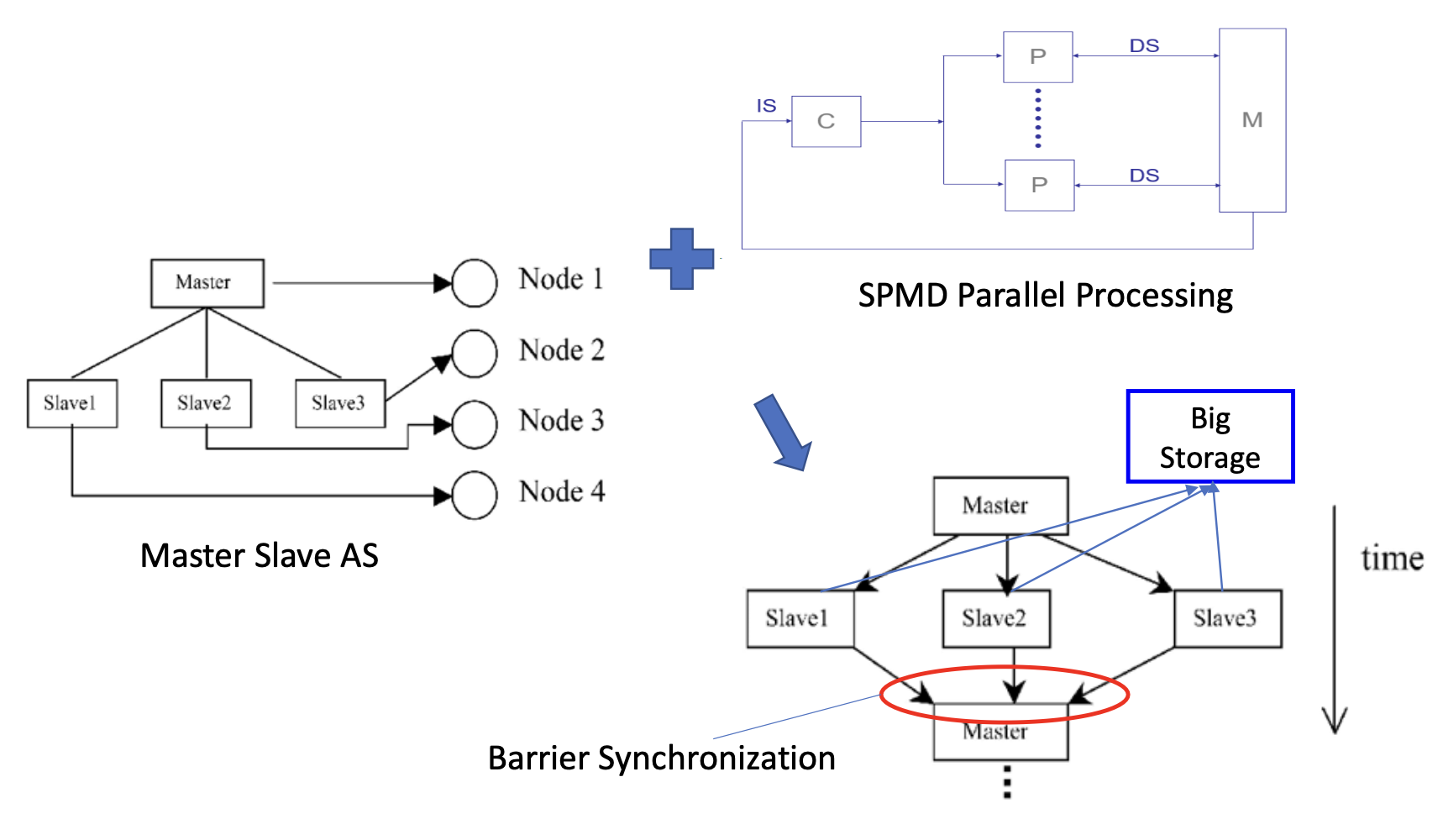
- 목적: 빠른 성능을 위한 병렬 처리 수행
- 구조: Master-Slave 아키텍처
- Master: Job Master (작업 전체 관리)
- Slaves: Task Workers (작업 분할 및 병렬 수행)
- 처리 방식: SPMD (Single Program Multiple Data) 방식의 병렬 처리
- 장애 대응: Passive Redundant Standby Master 구성
2. Cluster Resource Management Layer (클러스터 자원 관리 계층)
Layered + Master-Slave + Redundancy Standy
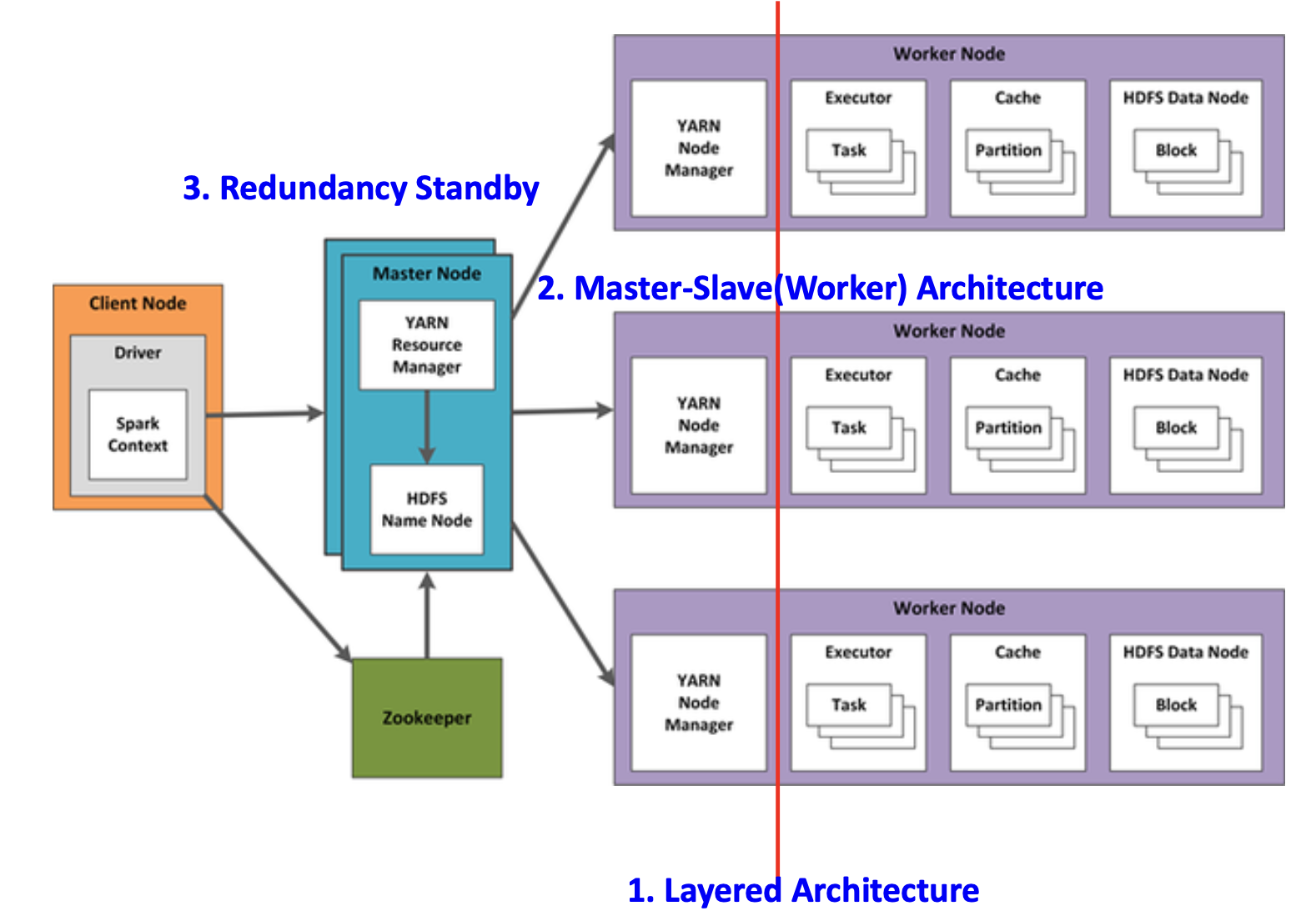
- 목적: 저렴한 PC 환경에서의 Fault Tolerance 제공
- 구조: Master-Slave 아키텍처
- Master: Resource Manager (전체 자원 상태 및 스케줄링 관리)
- Slaves: Node Managers (각 노드의 자원 상태 보고 및 컨테이너 관리)
- 장애 대응: Passive Redundant Standby Master 구성
3. Distributed File System Layer (분산 파일 시스템 계층)
Master Slave Architecture + Centralized P2P + Data Unit ( = Block (64M or 128M)) + Redundancy Standby Master
- 목적: 빅데이터 분산 스토리지의 쉬운 사용
- 구조: Master-Slave 아키텍처
- Master: NameNode (중앙 인덱스 서버, 메타데이터 관리)
- Slaves: DataNodes (실제 데이터 저장소 역할)
- 네트워크 모델: Centralized P2P
- 장애 대응: Passive Redundant Standby Master 구성
'CS 지식 > 분산시스템과 컴퓨팅' 카테고리의 다른 글
| Ceph의 소개와 HDFS와 차이 (0) | 2025.04.03 |
|---|---|
| HDFS(하둡 분산 파일 시스템) 구조 및 작동 방식 (0) | 2025.04.03 |
| 빅데이터 처리와 람다 아키텍처 소개(Hadoop) (0) | 2025.04.02 |
| 분산시스템의 아키텍처와 운영체제의 종류 (0) | 2025.03.16 |
| 분산시스템과 컴퓨팅의 소개 (0) | 2025.03.10 |




댓글