
HDFS: Hadoop Distributed File System
HDFS는 대용량 파일 저장 및 분산 처리에 최적화된 분산 파일 시스템이다. 다음과 같은 설계 철학을 기반으로 한다:
설계 목적
- 매우 큰 파일 저장: 수백 MB ~ 수 TB에 이르는 대규모 파일
- 스트리밍 데이터 접근 패턴: Write-once, Read-many-times 방식
- 일반 하드웨어(Commodity Hardware)에서 구동 가능
HDFS의 제한 사항
HDFS는 모든 유형의 워크로드에 적합하지 않다. 대표적인 제한 사항은 다음과 같다:
- 낮은 지연시간 요구에 부적합: HDFS는 고처리량(Throughput)에 최적화되어 있으며, 실시간 처리에는 부적절하다.
- 예: 실시간 쿼리 → HBase 추천
- 작은 파일이 많은 경우 비효율:
- 메타데이터를 NameNode가 메모리에 저장하기 때문에, 작은 파일 수가 많으면 메모리 소모 큼
- 다중 작성자 지원 안 됨:
- 한 파일에 대해 하나의 클라이언트만 쓸 수 있음
- 기존 파일의 임의 수정은 불가
블록 구조와 저장 단위
- 블록(Block): HDFS의 최소 읽기/쓰기 단위
- 기본 크기: 64MB (현업에서는 보통 128MB 사용)
- 왜 큰 블록인가?
- 디스크 탐색 비용(Seek Time) 최소화
- 이점
- 하나의 파일이 여러 디스크에 나뉘어 저장 가능
- 블록 단위로 저장 및 복제 → 가용성과 내결함성 향상
파일 복제 및 저장 방식
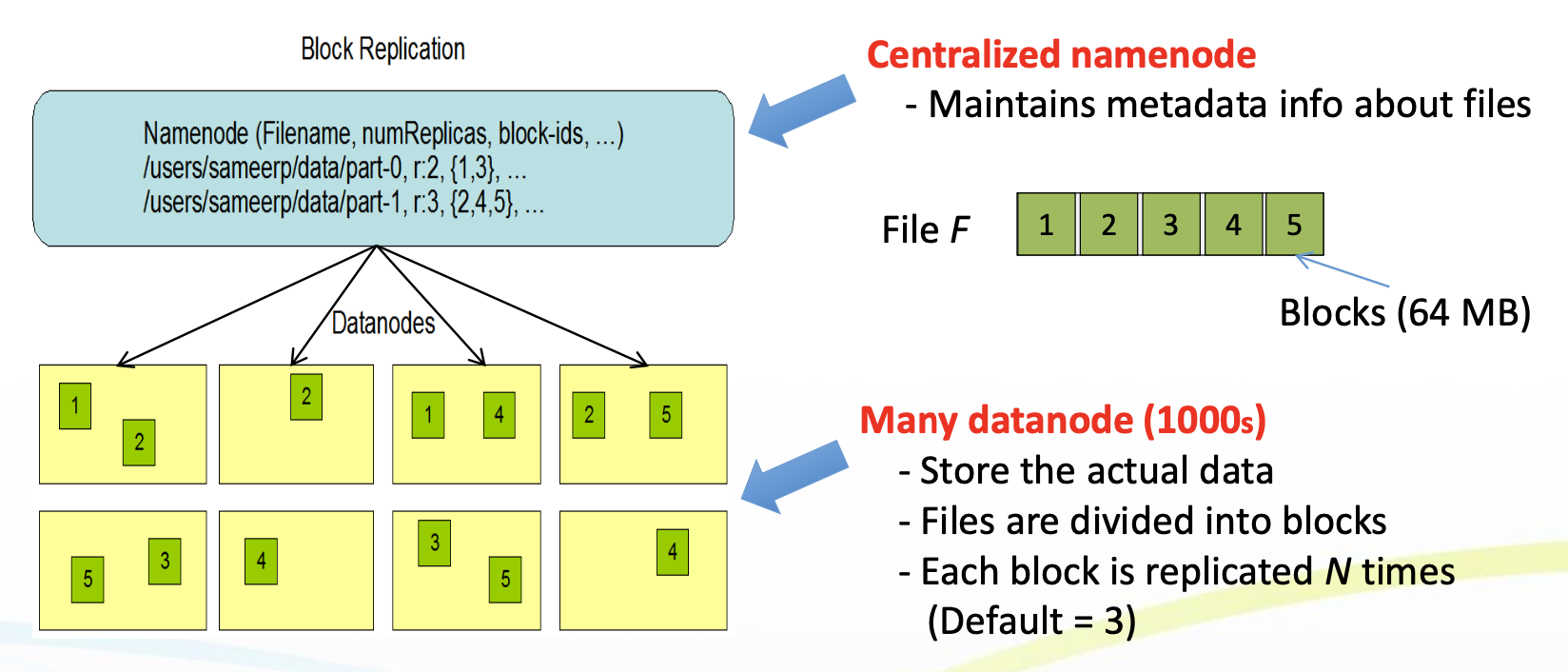
- HDFS는 각 블록을 기본 3개 복제(Replica) 하여 저장함
- 복제본 저장 순서:
- 클라이언트가 존재하는 노드
- 다른 랙(Rack)의 임의 노드
- 두 번째 노드와 같은 랙의 또 다른 노드
- 복제 이유:
- 장애 발생 시 빠른 복구 가능
- 네트워크 병목 최소화
HDFS 내부 구성 요소
1. NameNode (마스터)
- 파일 시스템 트리 및 메타데이터 관리
- 메타데이터 파일: fsimage, edits
- 각 파일이 어떤 블록으로 나뉘었는지, 해당 블록이 어느 DataNode에 있는지를 추적
- 블록의 실제 위치는 로컬에 저장하지 않고, DataNode에서 주기적으로 보고받음
2. DataNode (워커)
- 실제 블록 데이터를 저장
- 클라이언트의 읽기/쓰기 요청을 처리
- 주기적으로 NameNode에 자신이 가진 블록 목록을 보고한다.
3. Secondary NameNode
- NameNode의 스냅샷 백업용 보조 역할 수행
- 장애 복구를 위해 fsimage와 edit log를 주기적으로 병합
- 주의: Active-Standby 구조가 아님 (장애 대비용 백업임)
HDFS의 파일 저장과 읽기 흐름
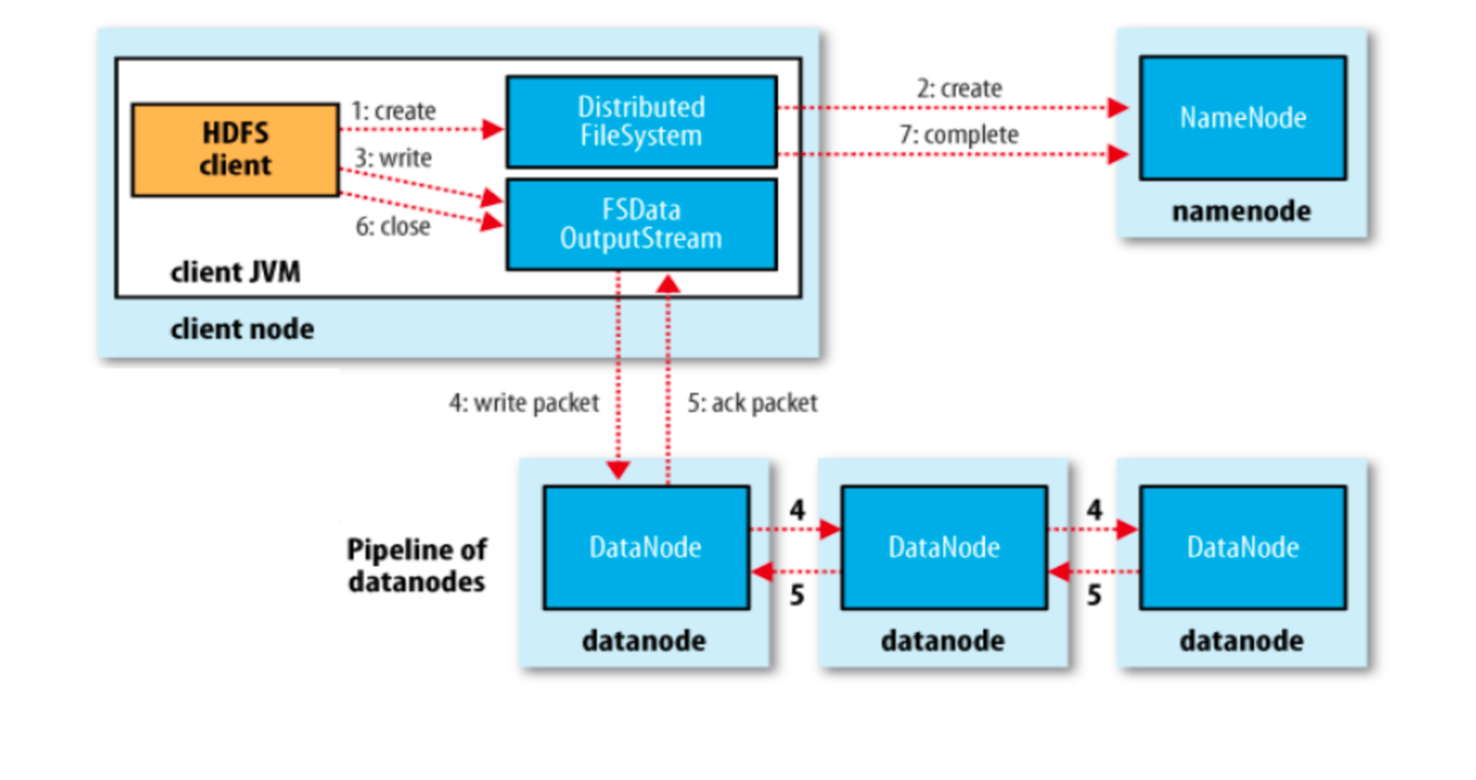
쓰기 흐름

- 클라이언트가 NameNode에 create 요청
- NameNode는 블록 ID와 대상 DataNode 리스트를 클라이언트에 전달
- 클라이언트는 첫 번째 DataNode에 전송 → 체인 구조로 첫번째 DataNode는 두 번째, 두번째 Datanode는 세 번째 노드로 복제해서 전달한다.
- 모든 노드에서 저장 완료 후 ACK 전달 → NameNode와 YARN에 완료 보고

클라이언트의 두번째 datablock에서도 똑같은 매커니즘으로 위 단계를 반복한다.
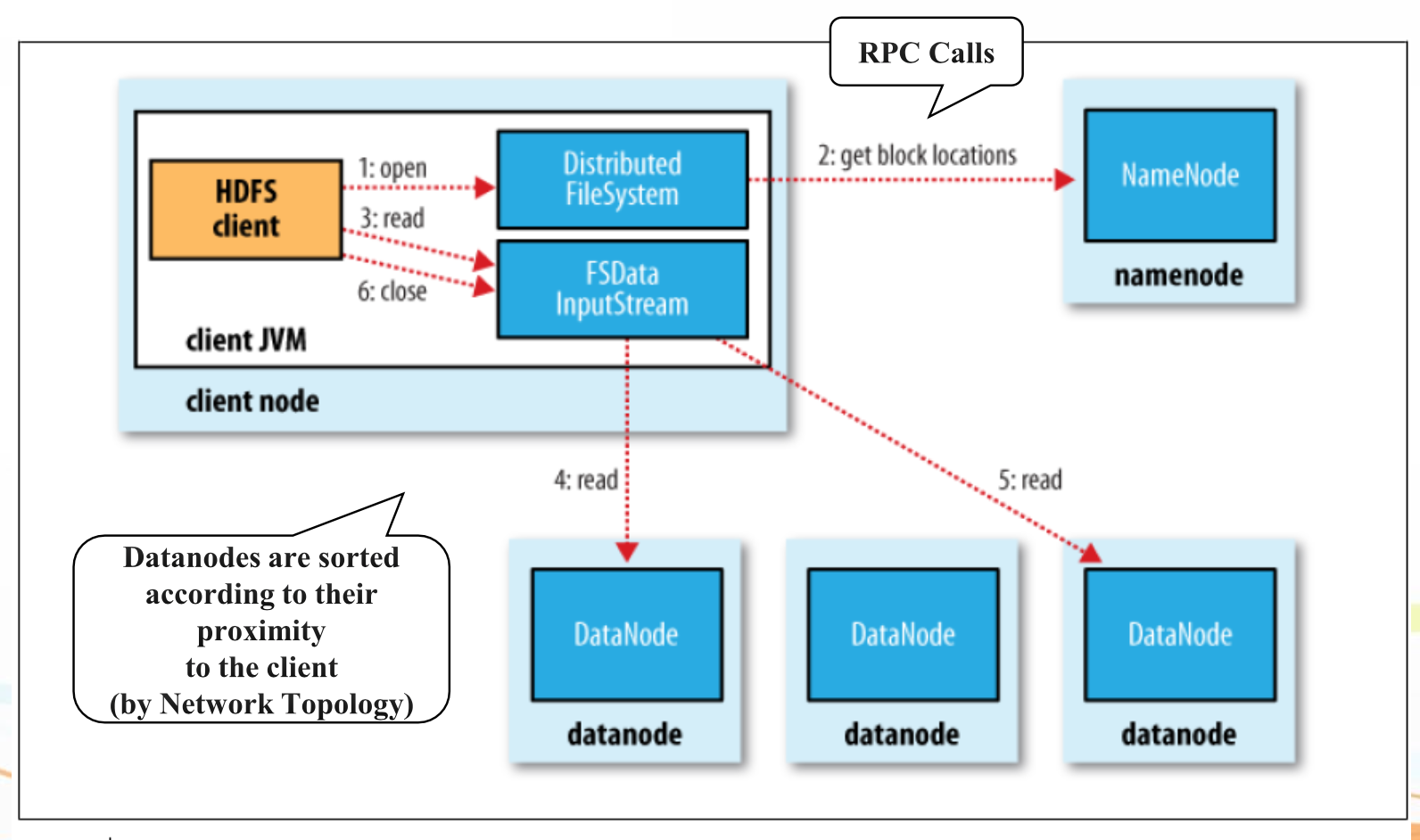
읽기 흐름

- 클라이언트가 NameNode에 파일의 메타데이터(블록 위치) 요청
- NameNode가 복제본(Datanode들) 리스트을 전달
- 클라이언트는 가장 네트워크 위상상 가까운/응답 빠른 노드로부터 직접 읽기
HDFS의 파일 저장과 읽기 흐름도
파일 읽기 흐름
파일 쓰기 흐름
네트워크 토폴로지와 거리 기반 최적화
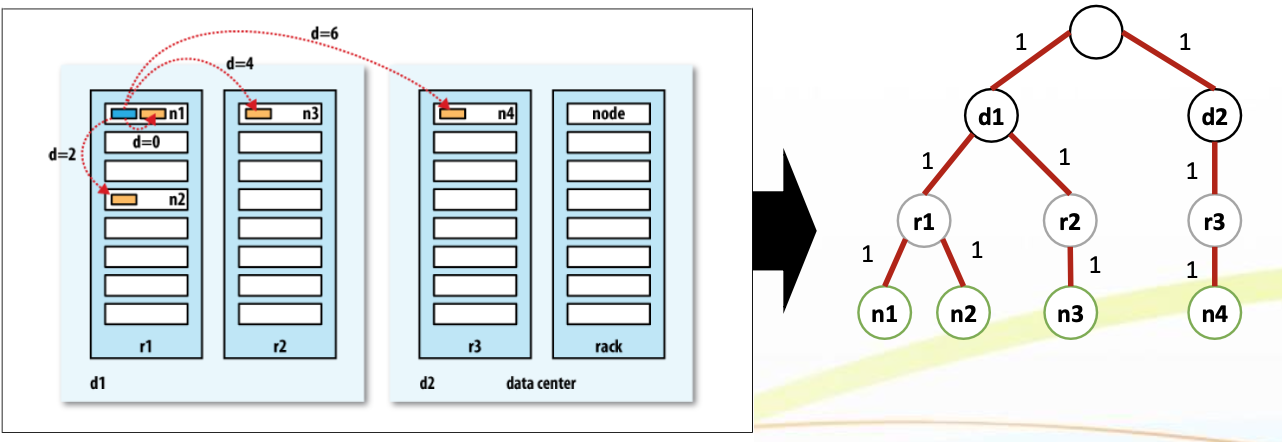
- Hadoop은 네트워크를 트리 구조(Tree) 로 표현
- 노드 간의 거리 = 루트에서 각 노드까지 거리의 합
- 이를 기반으로:
- 가장 가까운 DataNode에서 읽기
- 복제본 배치 시 네트워크 병목 최소화
YARN과 자원 관리 구조
- YARN: Yet Another Resource Negotiator
- 구성:
- ResourceManager: 전체 자원 상태 파악, 작업 스케줄링
- NodeManager: 각 노드의 실행 상태 및 컨테이너 관리
- YARN은 전체 클러스터의 자원 사용을 조율하고, MapReduce 작업의 컨테이너를 할당한다.
클러스터 구성 예시
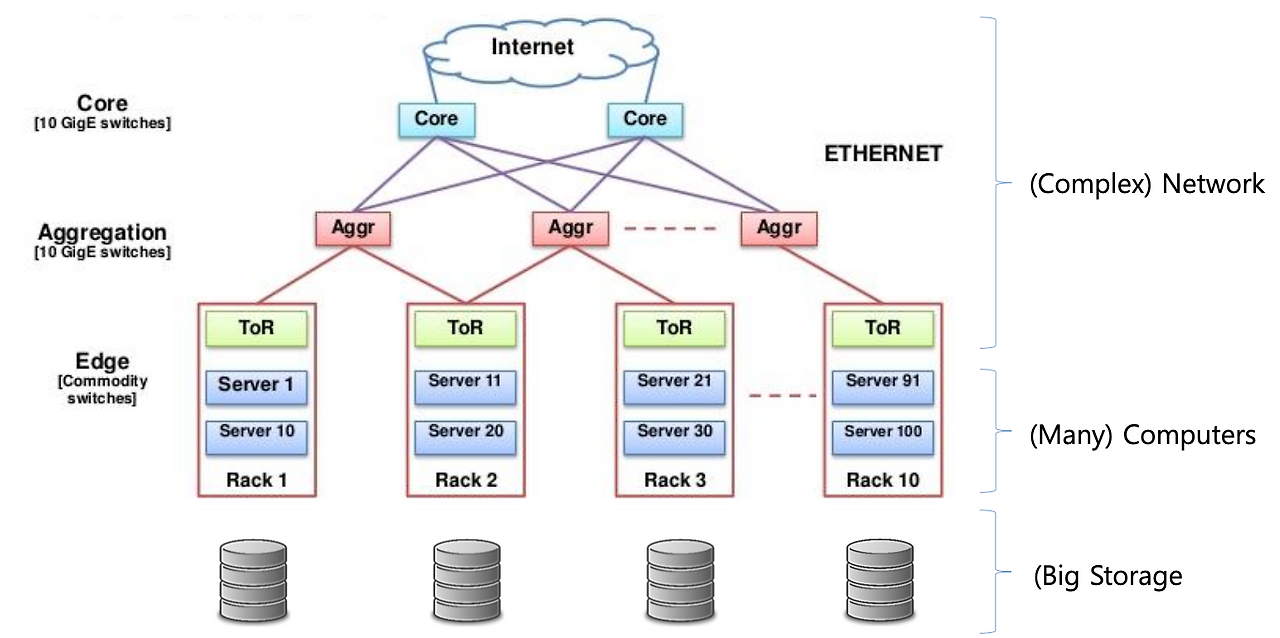
- 노드들은 보통 랙 단위로 묶임
- 네트워크 계층:
- Top-of-Rack (ToR) 스위치
- Aggregation Switch
- Core Router
- 복제본 배치 시 이 계층 구조를 고려하여 네트워크 효율성을 확보함
HDFS 복제본 저장 전략 (Replica Placement Strategy)
HDFS는 각 블록을 기본적으로 3개 복제(Replica) 하여 저장합니다. 이는 장애 발생 시 빠른 복구와 네트워크 병목 최소화를 위한 전략입니다.
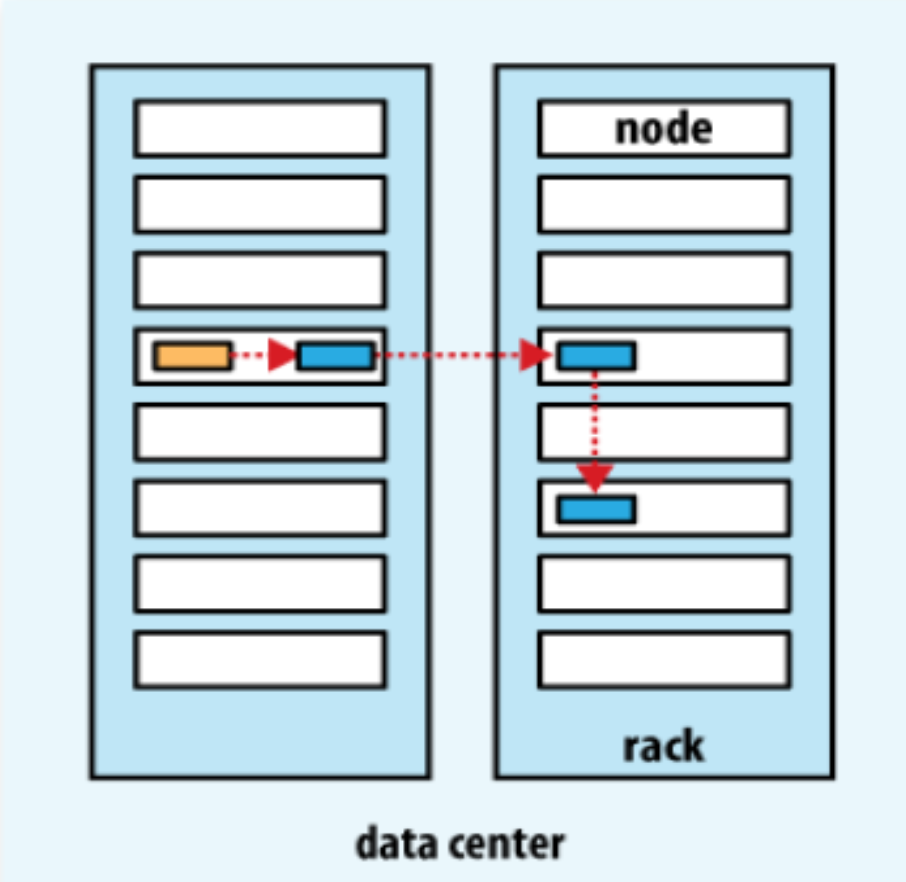
복제본 저장 순서:
- 첫 번째 복제본:
- 데이터를 업로드하는 클라이언트가 존재하는 노드의 DataNode에 저장
- 로컬 쓰기를 통해 네트워크 비용 최소화 및 빠른 처리 속도 확보
- 두 번째 복제본:
- 첫 번째 복제본이 위치한 랙과는 다른 랙의 임의 노드에 저장
- *랙 장애(rack failure)**와 같은 큰 장애에 대비해 고가용성 확보
- 세 번째 복제본:
- 두 번째 복제본과 같은 랙에 있는 다른 노드에 저장
- 복제 균형을 맞추며, 네트워크 효율성도 고려한 배치 전략
- 네 번째 이후 복제본 (추가 복제본):
- 필요 시 클러스터 내의 무작위 노드에 저장
복제 목적:
- 장애 발생 시 빠른 복구 가능
- → 블록 손실 시 다른 복제본으로부터 자동 복구
- 네트워크 병목 최소화
- → 랙 간 트래픽을 줄이고, 로컬 및 동일 랙 내 접근을 우선시함
이러한 전략을 통해 HDFS는 데이터의 내결함성(fault-tolerance)과 효율적인 데이터 접근을 동시에 보장합니다.
MapReduce 프로그래밍 모델
핵심 구성 함수
- Map Function
- Input: (Key, Value) → ex: (LineNumber, 문장)
- Output: (Key, Value) 리스트 → ex: "fox" → ("fox", 1)
- Reduce Function
- Input: (Key, [Value, Value, ...])
- Output: (Key, AggregatedValue) → ex: ("fox", 2)
- Combine Function
- Mapper에서 나오는 중간 결과를 로컬에서 미리 축약
- 네트워크 전송량 줄임
MapReduce 실행 흐름
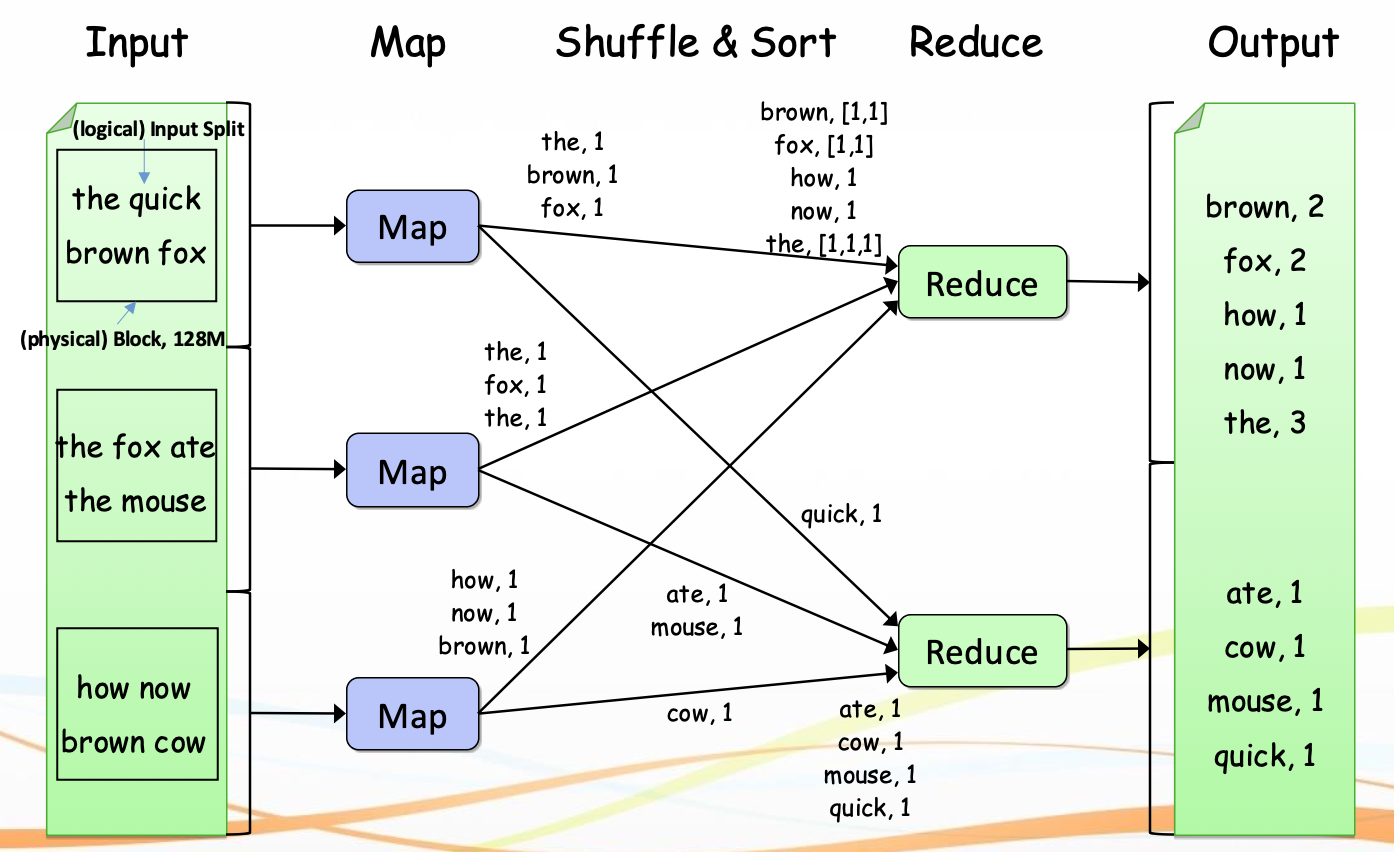
1. Input Split
- 큰 입력 파일을 Split 단위(보통 128MB) 로 논리적 분할
- Split 단위는 Mapper의 실행 단위가 된다
2. Mapper 실행
- 각 Split에 대해 Mapper 실행
- 메모리 버퍼에 Key-Value 저장
3. Spill 및 Partition
- 메모리 버퍼가 가득 차면 디스크로 Spill
- Partition: 각 Key-Value가 어느 리듀서로 갈지 결정
- 해시 기반 분배
4. Merge (정렬 및 병합)
- 여러 Spill 파일 병합
- 정렬 후 하나의 입력 스트림 구성
5. Shuffle & Sort
- 맵 출력 결과를 네트워크를 통해 각 리듀서로 전송
- 키 기준 정렬 + 병합
6. Reduce 실행
- 각 Key에 대해 집계 수행
- 최종 결과 출력
Hadoop 내부 최적화 요소
- Combiner
- 중복 Key에 대한 Value를 로컬에서 미리 집계
- Local Spill
- 중간 결과를 로컬 디스크에 저장하여 실패 시 복구 가능
- Shuffle 효율성
- 네트워크 오버헤드 최소화
리듀서 배치 전략
- 리듀서가 데이터를 받는 위치는 중요
- 가능한 가까운 노드에 배치
- 같은 랙 → 네트워크 병목 최소화
예시
- Mapper가 Node 1, 2, 3에서 실행되었다면, 이 중 하나에 Reducer 배치
데이터 복제 및 오버헤드 절감
- 클라이언트가 데이터를 전송할 때, 지정된 DataNode에 순차 전송
- 복제는 체인 방식으로 수행됨 (1 → 2 → 3)
- 모든 노드 저장 완료 후 ACK
Ceph vs HDFS 비교
| 항목 | Hadoop HDFS | Ceph |
| 아키텍처 | Master-Slave | Peer-to-Peer |
| 메타데이터 | NameNode | Monitor + MDS |
| 확장성 | 수천 대 가능 | 수만 대 이상 가능 |
| 장애 대응 방식 | Passive Standby | Active MON + CRUSH 알고리즘 |
| 복제 | 3-Copy | 3-Copy + CRUSH |
| 사용 목적 | 대용량 처리 (MapReduce) | 클라우드 스토리지, 백업 |
| 목적 | 병렬 분산 처리용 스토리지 | 범용 스토리지 (Object, Block 등) |
Ceph의 구조 요약
- Monitor(MON): 클러스터 상태 관리, Paxos 기반 합의
- Object Storage Device (OSD): 데이터 저장
- MDS: 파일시스템 구조 제공
- RADOS: 모든 데이터 객체는 RADOS에 저장됨
- Gateway: RESTful API 통해 접근
HDFS 장점
- 대용량 처리에 최적화
- 고속 스트리밍 처리
- 간단한 아키텍처
HDFS 단점
- 낮은 지연 요구에 부적합
- 작은 파일 처리에 비효율
- 파일 수정 불가
Ceph 장점
- 다양한 데이터 형식 지원 (Object, Block, File)
- 모든 노드가 Active
- 클라우드, VM, 백업에 적합
전체 아키텍처 개요
- Storage Layer: HDFS / Ceph
- Processing Layer: MapReduce / Spark
- Resource Management: YARN (RM + NM)
- Fault Tolerance:
- HDFS: 복제 + Secondary NameNode
- Ceph: MON + CRUSH
반응형
'Server-side 개발 & 트러블 슈팅 > 🐘 Hadoop (하둡)' 카테고리의 다른 글
| [Hadoop] 하둡 설치 및 MapReduce 기본 예제 실습 (Standalone 모드) (0) | 2025.04.14 |
|---|---|
| [Hadoop] 하둡 실습을 위한 VM 환경 세팅 (virtual box, VMware Fusion) (0) | 2025.04.14 |
| [Hadoop] 하둡 MapReduce 1.0 아키텍처와 동작 원리와 MapReduce 2.0의 개선 구조 (0) | 2025.04.09 |
| [Hadoop] 하둡 MapReduce 동작 원리 (0) | 2025.04.09 |
| 하둡(Hadoop)의 아키텍처, 병렬처리, 장애처리 전략 (0) | 2025.04.02 |




댓글