분산 알고리즘의 유형
1. Sequentional Algorithm
- 단일 흐름 (Single flow), 단일 프로세스로 순차적 실행.

2. Parallel Algorithm
- 여러 흐름(프로세스, 스레드)를 가지고 있고, 각 흐름에 대해서 병렬적으로 실행한다.
- Hierarchical Structure를 가진다.


병렬 처리의 4가지 유형:
- SISD
- SIMD
- MISD
- MIMD → 목표: 속도 향상 (Speed Up)
3. Distributed Algorithm


- 다중 흐름 (Multi-processes, Multi-thread), 동일한 흐름을 동시 비동기적으로 실행
- 각 흐름은 동일한 알고리즘을 가지며, 목표는 협력을 통한 문제 해결 (Cooperation to solve the target problem)
- Flat structure를 가진다.
분산 알고리즘의 예시
- 라우터 내 Routing Algorithm
- DNS (Domain Name Service) → 이름과 IP 주소 매핑
- Election Algorithm
- Consensus Algorithm
Coordinator 란?
코디네이터는 분산된 여러 노드 간의 상태를 관리하고, 특정 노드를 리더로 선출하거나, 노드 간 통신을 중재하는 핵심적인 역할을 담당한다. 이를 통해 노드들이 충돌 없이 하나의 시스템처럼 동작할 수 있게 만든다.
하지만 직접 이러한 코디네이터를 구현하는 것은 어렵고 번거로운 작업이다. 각 노드의 상태를 실시간으로 감지하고, 리더 선출 등의 합의 과정을 안정적으로 구현하려면 복잡한 알고리즘과 예외 처리가 필요하다.
Coordinator Election Algorithm (조정자 선출 알고리즘)
Election Problem
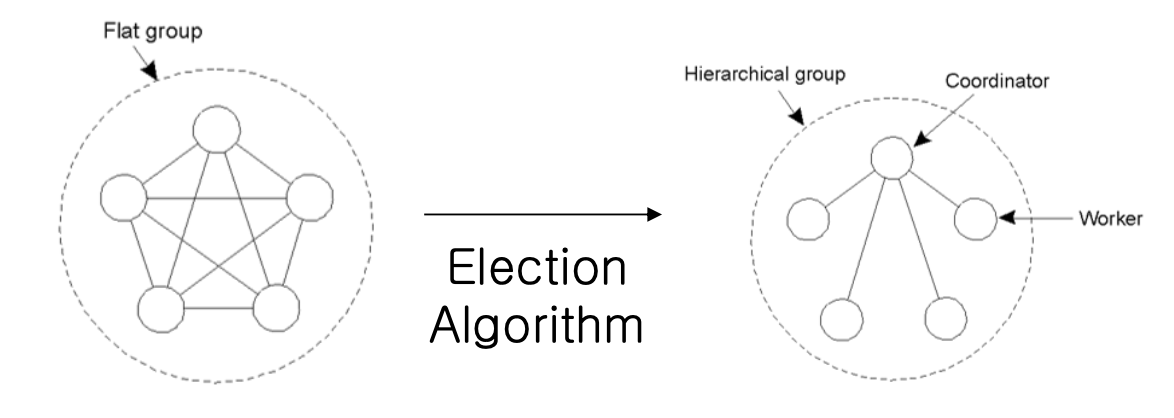
- 평등한 프로세스 집단에서 하나를 선택하여 조정자(Coordinator)로 지정
- 목표:
- 선거가 시작되면,
- 모든 프로세스가 새로운 조정자에 대해 동의하도록 선거를 끝냄
가정 (Assumptions)
- 각 프로세스는 고유 ID(id) 를 가짐
- 모든 프로세스는 다른 모든 프로세스의 ID와 주소를 알고 있음
- 어떤 프로세스가 살아있는지, 죽었는지는 모름
- 통신은 신뢰할 수 있다고 가정, 하지만 선거 중 프로세스는 실패할 수 있음
- 선거는 조정자(Coordinator)가 고장났음을 탐지했을 때 시작됨
Bully Algorithm (불리 알고리즘)
알고리즘 요약
- 프로세스 P가 선거를 시작하면,자신보다 ID가 높은 모든 프로세스에게 ELECTION 메시지 전송
- 응답이 없으면, P는 승자로 간주되어 조정자가 됨
- 응답이 오면, 더 높은 ID를 가진 프로세스가 선거를 넘겨받음, P는 중단
- 결국, 하나의 프로세스만 남고 새로운 조정자로 선택
- 해당 프로세스는 모든 프로세스에 새로운 조정자임을 알림
- 죽어 있던 프로세스가 다시 살아나면, 선거를 다시 시작함
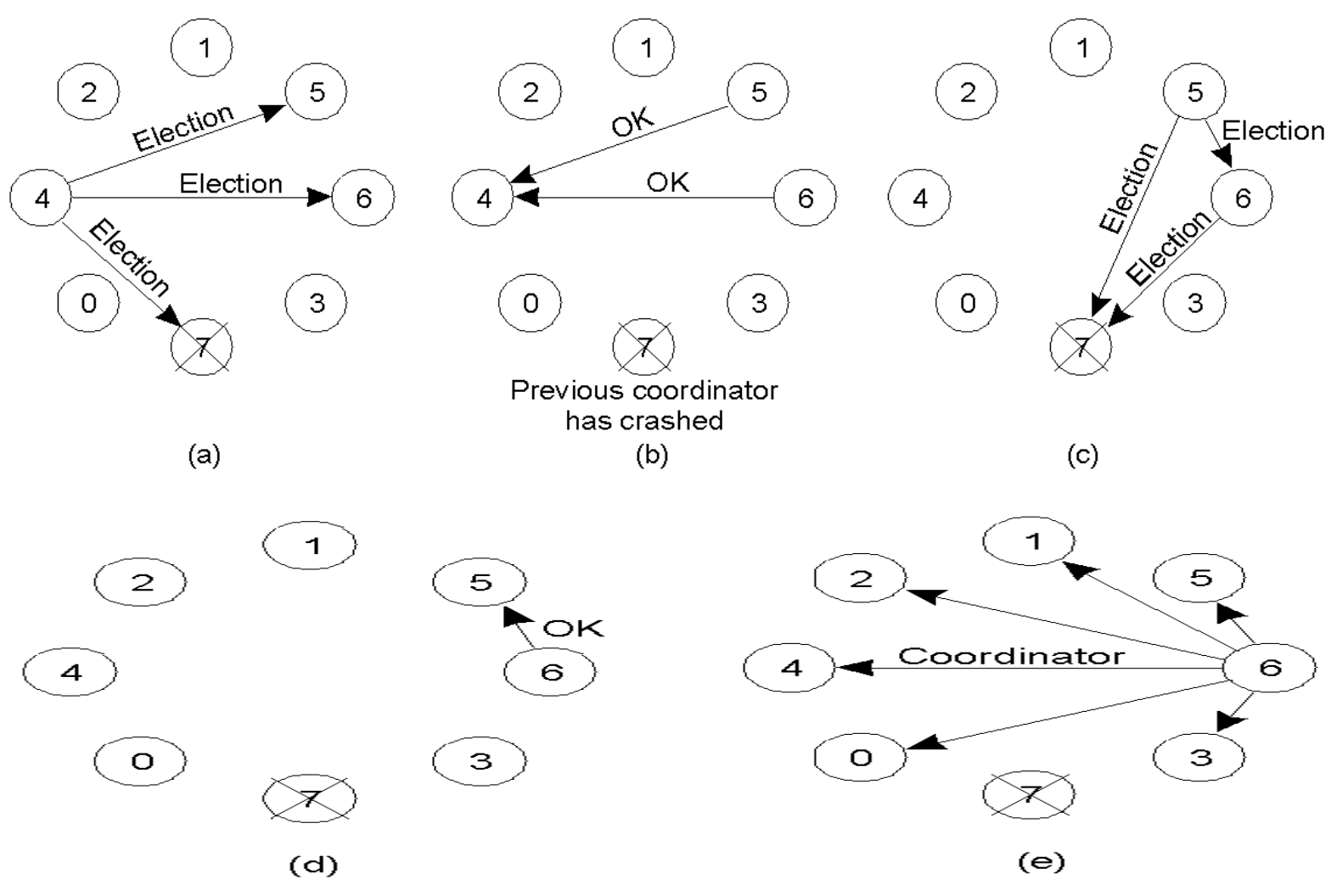
(a)
- Process 4가 조정자가 죽었다고 판단하고 선거를 시작
- 자신보다 ID가 높은 5, 6, 7에게 ELECTION 메시지 전송 (7은 죽었으므로 응답 없음)
(b)
- Process 5와 6이 응답(OK) → "내가 처리할게"
- 4는 선거에서 포기
(c)
- 이제 5와 6이 각자 선거를 시작
- 죽은 7에게도 메시지를 보내지만 응답 없음
(d)
- 6이 5에게 OK 응답 → 5는 포기
(e)
- 6이 승자(Coordinator)가 되어,모든 프로세스에게 자신이 새 조정자임을 알림
Zookeeper의 리더 선출 알고리즘 (Zookeeper Leader Election)
Zookeeper는 단순한 ID 비교 기반의 선출이 아닌, 데이터 일관성과 동기화를 고려한 분산 합의 기반 리더 선출 알고리즘을 사용한다.
이 알고리즘은 Fast Leader Election 또는 ZAB (Zookeeper Atomic Broadcast) 프로토콜의 일부분으로 작동한다.
핵심 개념
- ZXID (Zookeeper Transaction ID): 각 서버가 기록한 가장 최신 트랜잭션 ID. 로그 기반으로 누가 가장 '최신 상태'인지를 판단할 수 있다.
- Server ID: 각 서버마다 고유한 ID를 가지고 있으며, ZXID가 같을 경우 이를 기준으로 우위를 결정한다.
- Vote (투표): 각 서버는 자신을 리더라고 주장하면서 다른 서버들에게 투표 요청을 보낸다.
- Quorum (과반): 전체 서버 중 과반수의 동일한 지지를 얻어야만 리더로 선출된다.
리더 선출 과정
- 리더 실패 감지
- 기존 리더가 heartbeat를 보내지 않거나, 연결이 끊긴 경우 새로운 리더 선출이 시작된다.
- 각 서버는 자신을 후보로 등록
- 현재 자신의 ZXID, Server ID를 기반으로 투표 메시지를 전송한다.
- 예: Vote(ServerID=3, ZXID=0x80000006)
- 다른 서버의 투표 수신 및 비교
- 수신한 투표의 ZXID가 더 최신이면 그 후보에게 투표
- ZXID가 같다면 Server ID가 더 높은 쪽에게 투표
- Quorum 형성 확인
- 같은 후보에 대해 과반수의 투표가 모이면 해당 후보가 리더가 됨
- 리더 승리 브로드캐스트
- 선출된 리더가 LEADER 메시지를 모든 서버에 전파
- Follower 상태 전이
- 나머지 노드들은 자신을 Follower로 전이하고 리더와 데이터 동기화를 시작
예시 메시지 흐름
| 단계 | 설명 |
| 1 | Server 3, 4, 5 모두 리더 다운 감지 |
| 2 | Server 4: Vote(4, ZXID 0x80000005) |
| 3 | Server 5: Vote(5, ZXID 0x80000006) |
| 4 | Server 4, 5, 6 → 모두 Server 5 지지 |
| 5 | Server 5 과반 획득 → 리더 승리 선언 |
Bully Algorithm과의 차이점 요약
| 항목 | Bully Algorithm | Zookeeper |
| 우선순위 기준 | ID (숫자 크기) | 최신 트랜잭션 ZXID → ID |
| 메시지 방식 | Election, OK, Coordinator | Vote, ACK, LEADER |
| 안정성 | 단일 응답 기반 (취약) | Quorum 기반 (강한 합의) |
| 복원성 | 중단 시 재선거 필요 | 자동 재선거, 내고장성 보장 |
| 쓰기 동기화 | 없음 | 리더만 쓰기 허용, 동기화 필수 |
결론
Zookeeper의 리더 선출 알고리즘은 단순히 "누가 제일 높냐"를 따지는 방식이 아니라, 데이터의 최신성, 과반수 합의, 상태 동기화까지 고려하여 분산 환경에서도 안정적인 리더 교체가 가능한 고급 알고리즘이다.
이는 단순한 Bully Algorithm과는 비교도 되지 않을 만큼 분산 시스템 특화된 설계이며, Kafka나 Hadoop YARN과 같은 시스템에서도 이를 기반으로 안정성을 확보한다.
반응형
'CS 지식 > 분산시스템과 컴퓨팅' 카테고리의 다른 글
| 장애허용성과 TMR, 프로세스 그룹의 개념 설명 (Fault Tolerance, Process Group) (1) | 2025.04.12 |
|---|---|
| Ceph의 소개와 HDFS와 차이 (0) | 2025.04.03 |
| 빅데이터 처리와 람다 아키텍처 소개(Hadoop) (0) | 2025.04.02 |
| 분산시스템의 아키텍처와 운영체제의 종류 (0) | 2025.03.16 |
| 분산시스템과 컴퓨팅의 소개 (0) | 2025.03.10 |




댓글