MapReduce 프로그래밍 모델 상세 설명
하둡의 MapReduce 프로그래밍 모델은 대용량 데이터를 병렬 처리하기 위한 함수 기반 처리 구조를 따르며, 두 가지 핵심 함수로 구성된다.
1. Map Function
- Input: (Key, Value) 형태로 입력을 받음
- 예: (Line Number, 문장 내용)
- Output: List of (Key, Value) 형태로 출력
- 예: "the quick brown fox" → ("the", 1), ("quick", 1), ("brown", 1), ("fox", 1) Map 함수는 주어진 데이터를 원하는 형태로 전처리하는 역할을 한다.
2. Reduce Function
- Input: (Key, List<Value>) 형태로 입력을 받음
- 예: ("the", [1,1,1,1])
- Output: (Key, AggregatedValue) 형태로 출력
- 예: ("the", 4)
Sudo 코드
def mapper(line):
foreach word in line.split():
output(word, 1)
def reducer(key, values):
output(key, sum(values))
Reduce 함수는 같은 키에 대해 들어온 값들을 집계(aggregation) 하여 최종 결과를 만들어낸다.
예제: Word Count (단어 빈도 수 계산)

입력 문장
The quick brown fox
the fox Ate the mouse
how now brown cow
Map 단계 출력 예시
("The", 1), ("quick", 1), ("brown", 1), ("fox", 1),
("Ate", 1), ("the", 1), ("mouse", 1),
("how", 1), ("now", 1), ("brown", 1), ("cow", 1)
Shuffle & Sort 단계
- Map 단계에서 나온 데이터를 키 기준으로 정렬 및 그룹화
- 예:
- "brown" → [1, 1]
- "the" → [1, 1]
- "cow" → [1, 1]
Reduce 단계 출력 예시
("brown", 2), ("the", 3), ("cow", 2), ...
하둡 MapReduce 실행 흐름 상세 구조
하둡이 실제 MapReduce 작업을 실행할 때 수행하는 흐름은 다음과 같다:
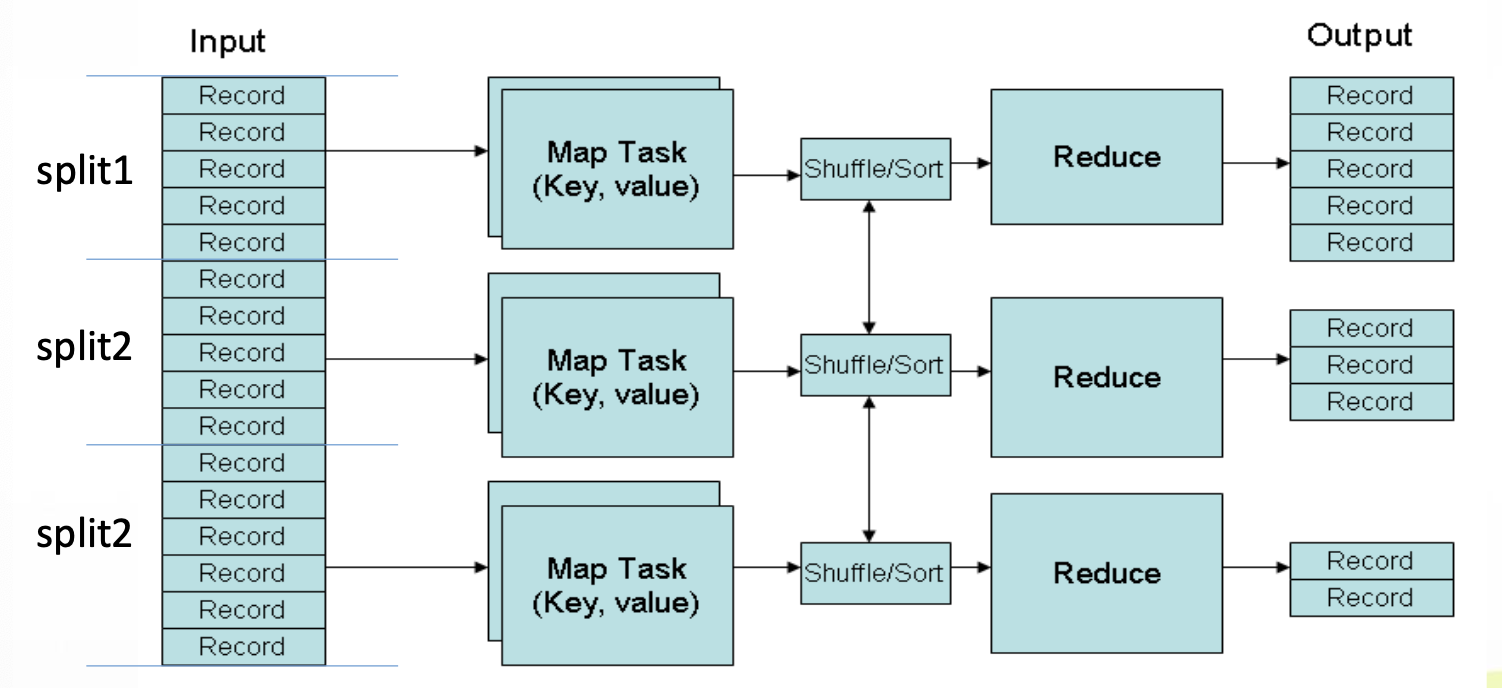
- Input Split:
- 대용량 파일을 여러 개의 Input Split으로 나눔
- 일반적으로 128MB 단위로 블록 분할
- Mapper 실행:
- 각 Split에 대해 Mapper 함수 실행
- Mapper는 로컬 디스크에 중간 결과를 저장
- Combiner 실행 (선택):
- Mapper가 낸 중간 결과를 로컬에서 미리 압축
- 네트워크 전송량 감소에 도움
- Shuffle & Sort:
- 같은 키끼리 데이터를 모으고 정렬함
- 네트워크를 통해 Reduce Task로 전송
- Reducer 실행:
- 수신한 중간 결과들을 집계
- Output 저장:
- 최종 결과를 HDFS에 파일로 저장
1. Input Split 생성
- InputSplit은 하나의 Mapper 작업에 입력으로 주어질 데이터를 논리적으로 분할한 단위이다.
- 반면, Block은 데이터를 물리적으로 분할한 단위이다.
- 하나의 InputSplit은 여러 개의 물리적 Block에 걸쳐 있을 수 있다.
- InputSplit의 기본 목적은 데이터를 정확히 처리할 수 있도록 논리적인 위치 정보를 Mapper에 전달하는 것이다.
- 이를 통해 각 Mapper는 여러 Block에 흩어진 데이터라도 전체를 올바르게 처리할 수 있게 된다.
- Hadoop에서 작업이 제출되면, 입력 데이터는 먼저 InputSplit 단위로 논리적으로 분할되고, 각 InputSplit은 하나의 Mapper에 의해 처리된다.
- Mapper의 수는 InputSplit의 수와 동일하게 생성된다.
2. Mapper 실행
- 하나의 마스터 노드가 전체 작업을 제어하며, 다수의 슬레이브 노드에서 작업이 수행된다.
- Mapper는 입력 블록과 같은 노드나 같은 랙(rack) 에서 실행되도록 우선 배치된다. → 이는 네트워크 사용량을 최소화 하기 위한 전략이다.
- 각 Split에 대해 Mapper 프로그램이 실행
- Mapper는 Split 데이터를 읽어 Key-Value 쌍으로 변환
- 변환된 결과는 메모리에 저장되다가 일정량을 넘으면 로컬 디스크에 Spill
- Mapper는 중간 결과를 로컬 디스크에 저장한 후 Reducer에게 전달한다.
- → 이를 통해 Reducer가 실패했을 때 복구가 가능하며,
- → Reducer 수가 노드 수보다 많을 수 있는 유연성도 확보된다.
3. Combiner (선택)
- Combiner는 같은 Mapper에서 반복적으로 생성된 동일 키에 대해 로컬에서 집계를 수행하는 함수이다.
- 합(sum), 개수(count), 최댓값(max) 처럼 결합 법칙이 성립하는(associative) 함수에 대해 사용할 수 있다.
- 목적은 중간 데이터의 크기를 줄여 네트워크 전송 비용을 줄이는 것이다.
- Reducer가 할 집계 작업을 일부 수행하여 효율 향상
- 예시: "the", 1이 여러 개 → "the", 4로 압축
- 예시: Word Count에서의 Combiner (map-side aggregation)
def combiner(key, values):
output(key, sum(values))
Combiner는 반드시 실행되는 것이 아니라, 하둡 설정에 따라 실행 여부가 달라진다.
4. Shuffle & Sort
- Shuffling과 Sorting은 Mapper와 Reducer 사이에 자동으로 수행되는 숨겨진 단계(hidden phase) 이다.
- 이 단계에서는 모든 Mapper의 출력 결과 중 동일한 키들을 그룹화하고, 키 기준으로 정렬하여 해당 키를 담당하는 Reducer에 전달한다.
- 이 과정을 통해 Reducer는 각 키에 대해 정렬된 값 리스트를 입력으로 받아 일관된 처리를 수행할 수 있게 된다.
- 이 과정
- 에서 네트워크를 통해 데이터 이동이 발생
하둡은 자동으로 데이터를 키 기준으로 Sort하고 필요한 Reducer에게 분배한다.
5. Reducer 실행
- Shuffle된 Key-Value 리스트를 입력으로 받아 집계 작업 수행
- 예: "fox", [1, 1] → "fox", 2
- 최종 결과를 하나의 (Key, Value)로 출력
6. Output 저장
- Reducer의 출력은 로컬 디스크에 저장된 후 HDFS에 최종 기록
- 출력 경로는 사용자 정의 가능 (보통 /output/ 디렉토리)
데이터 흐름: Disk와 Memory 간 처리
- Map Task는 출력 결과를 메모리 버퍼에 우선 저장
- 버퍼가 일정 이상 차면 디스크로 Spill
- 디스크에 저장된 데이터를 Reduce에 전송
버퍼 처리 과정
- Map Output → Memory Buffer
- Buffer가 가득 차면 → Spill to Disk
- Disk에 저장된 결과를 Partition 및 Merge
- Reduce에 전달하여 최종 처리
최종 구조 요약
| Job Tracker | 작업 전체를 조율하는 마스터 |
| Task Tracker | 각 노드의 작업을 수행하는 워커 |
| Map Task | 입력 데이터를 파싱 및 변환 |
| Reduce Task | Key별 데이터 병합 및 결과 생성 |
| Combiner (옵션) | 중간 결과를 로컬에서 병합 |
| YARN | 클러스터 자원 할당 및 모니터링 |
| HDFS | 분산 파일 저장소 (NameNode + DataNode) |
하둡은 단순히 데이터 처리만 하는 것이 아니라, 내부적으로 메모리와 디스크를 병행 활용하면서 효율적으로 데이터를 관리한다. 그 중 대표적인 작업 흐름이 바로 Spill, Merge, Partition이다.
메모리 → 디스크 Spill 과정
- 맵(Map) 단계에서의 처리 결과는 우선 메모리에 저장된다.
- 맵 함수가 Key-Value 결과를 생성하면, 이를 버퍼(메모리)에 임시 저장한다.
- 이 메모리는 일정 크기(버퍼 크기)가 찰 때까지 계속 사용된다.
- 메모리가 가득 차면 데이터를 디스크에 Spill한다.
- 데이터를 파티셔닝(Partitioning) 한다.
- 리듀서 수에 따라 파티션을 나눈다. 예: 리듀서가 3개면, 메모리 안의 데이터를 3개의 파티션으로 분리한다.
- 각 파티션 데이터를 디스크로 내보낸다(Spill).
- 데이터를 파티셔닝(Partitioning) 한다.
- 디스크에 저장된 여러 Spill 파일은 이후 Merge된다.
- 여러 Spill 파일이 생성될 수 있기 때문에, 이를 Merge(병합)하여 정리한다.
- 정렬(Sort) 및 머지 과정을 통해 최종적으로 리듀서에 전달할 준비를 한다.
Partition의 목적
- 각 Key-Value 쌍이 어느 리듀서에 전달될지를 결정하는 것이 파티셔닝의 목적이다.
- 예를 들어, the, box, brown 등의 단어가 각기 다른 리듀서로 가게 된다면:
- the는 리듀서1
- box는 리듀서2
- brown은 리듀서3
- 이런 식으로 Key 값을 기준으로 해시 함수를 이용해 분배한다.
리듀서 쪽에서의 처리
- 여러 맵퍼(Mappers)에서 전달된 파티션들이 각 리듀서로 전달된다.
- 리듀서에서는 자신이 받을 파티션 파일들을 Merge하여 하나의 정렬된 입력 스트림으로 만든다.
- 이후, 리듀서 함수가 실행되어 최종 Key-Value 집계 작업을 수행하게 된다.

하둡 내부의 최적화 포인트
- Combiner
- 리듀서로 가기 전, 중간에 동일 Key의 Value들을 먼저 더해서 리듀서 부담을 줄여주는 역할을 한다.
- Local Disk 사용
- 네트워크 전송 이전에 로컬 디스크에 저장해서 장애가 발생해도 복구가 가능하도록 한다.
- Shuffle & Sort
- 네트워크 전송 후, Key 기준으로 데이터를 정렬하고 리듀서에게 할당하기 위한 단계다.
전체 요약
하둡 MapReduce는 단순한 맵-리듀스가 아니라 다음과 같은 복잡한 과정을 거친다:
- Map 작업: Key-Value 생성 → 메모리 버퍼 → Spill → Partition → Disk 저장
- Shuffle & Sort: 맵 결과를 리듀서로 이동시키기 위한 정렬 및 분배
- Reduce 작업: Key 기준으로 정렬된 데이터 집계
- 최종 출력: 로컬 디스크 또는 HDFS에 저장
이 과정을 통해 하둡은 대용량 데이터를 효과적으로 병렬 처리할 수 있는 인프라를 제공하게 된다.
하둡 버전 별 MapReduce 구조 요약
하둡(Hadoop) 1.0 MapReduce 구조
기본 흐름
- 사용자가 Job을 제출하면 JobTracker가 이를 받아 처리한다.
- JobTracker는 Job을 여러 개의 Task로 나누고, 각 Task를 TaskTracker에게 분배한다.
- TaskTracker는 Map과 Reduce Task를 실행하고 중간 결과를 저장한다.
- Reduce Task가 중간 결과를 처리하여 최종 결과를 만든다.
구성 요소
- JobTracker: 클러스터 전체 Job 관리 및 Task 배포 담당
- TaskTracker: JobTracker로부터 Task를 받아 실행하고, 진행 상태를 Heartbeat로 JobTracker에 보고한다.
- NameNode/DataNode: 데이터의 위치를 관리하고 저장함.
Map Task 실행 과정
- 입력 데이터를 Input Split으로 나누어 처리함.
- 각 Map Task는 입력 데이터를 키-밸류 형태로 읽어 중간 결과를 생성함.
- 중간 결과는 메모리 버퍼에 임시 저장되며, 버퍼가 일정 크기(약 80%)가 되면 디스크로 Spill한다.
- Spill 시 데이터는 Partitioning, Sorting, Combining을 거쳐 디스크에 저장된다.
Reduce Task 실행 과정
- 각 Reduce Task는 여러 Mapper에서 생성된 중간 결과를 수집해 다시 병합(Merge) 및 정렬(Sort)한다.
- 최종적으로 Reduce 함수가 실행되어 결과를 HDFS에 저장한다.
장애 처리 메커니즘 (Fault Tolerance)
Task Failure
- Task가 Runtime Exception으로 종료되면, TaskTracker가 이를 감지하여 JobTracker에 보고한다.
- JobTracker는 다른 TaskTracker에서 Task를 다시 실행한다(최대 4회까지).
TaskTracker Failure
- TaskTracker가 Crash하거나 Heartbeat가 중단되면, JobTracker는 일정 시간(기본 10분) 기다린 후 해당 노드를 Blacklist 처리한다.
JobTracker Failure
- 가장 치명적이며 Hadoop 1.0에서는 이를 복구할 수 있는 방법이 없다.
Job Scheduling
- 초기 Hadoop은 FIFO(선입선출) 방식이며, 우선순위 조정 및 Fair Scheduler를 통해 다중 사용자 환경에서 자원을 공정하게 배분할 수 있다.
성능 최적화
- Shuffle & Sort: Mapper 결과를 효율적으로 Reducer에게 전달하기 위한 과정.
- Speculative Execution: 느린 Task를 다른 노드에서 추가 실행하여 성능 병목을 완화함.
- JVM Reuse: Task 실행 시 JVM 생성 오버헤드를 줄이기 위해 JVM을 재사용함.
Hadoop 2.0 (YARN 기반 구조)
YARN의 특징
- 자원 관리(Resource Manager)와 작업 실행(Node Manager/ApplicationMaster)을 분리해 확장성과 안정성 개선
- JobTracker가 없어지고, 각 Job마다 독립적인 Application Master가 생김
- 다양한 애플리케이션(MapReduce, Spark, Tez 등)을 실행할 수 있는 플랫폼이 됨
주요 컴포넌트
- Resource Manager: 전체 클러스터의 자원을 관리하며 Application Master에 자원을 할당함
- Node Manager: 각 노드에서 Container를 실행하고 관리함
- Application Master (MRAppMaster): JobTracker의 역할을 분산시켜 Job의 Task 관리 및 상태 모니터링을 담당함
YARN에서의 작업 실행 흐름
- 클라이언트가 Resource Manager에 Job을 제출하면 Application ID를 생성하고 자원을 준비함
- Resource Manager는 Node Manager를 통해 Application Master 컨테이너를 생성함
- Application Master는 Input Split 정보를 가져오고, Resource Manager에 필요한 컨테이너를 요청함
- Node Manager가 컨테이너를 생성하고 Mapper 또는 Reducer Task를 실행함
- Task는 결과를 처리하여 최종적으로 HDFS에 저장하고 상태를 Application Master에 보고함
반응형
'Server-side 개발 & 트러블 슈팅 > 🐘 Hadoop (하둡)' 카테고리의 다른 글
| [Hadoop] 하둡 설치 및 MapReduce 기본 예제 실습 (Standalone 모드) (0) | 2025.04.14 |
|---|---|
| [Hadoop] 하둡 실습을 위한 VM 환경 세팅 (virtual box, VMware Fusion) (0) | 2025.04.14 |
| [Hadoop] 하둡 MapReduce 1.0 아키텍처와 동작 원리와 MapReduce 2.0의 개선 구조 (0) | 2025.04.09 |
| HDFS(하둡 분산 파일 시스템) 구조 및 작동 방식 (0) | 2025.04.03 |
| 하둡(Hadoop)의 아키텍처, 병렬처리, 장애처리 전략 (0) | 2025.04.02 |




댓글