Hadoop 1.0에서 2.0으로의 진화: 구조, 한계, 그리고 개선 전략
Hadoop은 대규모 데이터를 효율적으로 저장하고 처리할 수 있는 분산 시스템의 대표적인 오픈소스 프레임워크다. 그 중 Hadoop MapReduce 1.0은 단순하고 일관된 구조를 바탕으로 초기 빅데이터 생태계를 선도했지만, 대규모 클러스터 환경에서의 확장성과 안정성의 한계를 드러냈다.
이 글에서는 먼저 Hadoop 1.0의 아키텍처와 내부 구성요소, 전체 동작 흐름을 세부적으로 살펴본다. 이후 1.0의 근본적인 약점을 어떻게 파악하고 해결하고자 했는지, 그리고 Hadoop 2.0(YARN 기반)으로의 전환이 어떤 배경에서 이루어졌는지를 구조적 비교와 전략적 전환 관점에서 분석한다.
이 글의 구성
- Hadoop 1.0 아키텍처 해부
- JobTracker / TaskTracker 기반 구조
- HDFS와 MapReduce 구성 요소 및 역할
- 전체 실행 흐름 분석 (입력 → 맵 → 셔플/소트 → 리듀스 → 출력)
- 결합 전략 및 시스템 한계
- 자원 관리와 작업 스케줄링의 중앙 집중화
- 확장성의 병목, 단일 실패 지점(SPOF)
- 다중 사용자 환경에서의 자원 분배 문제
- Hadoop 2.0의 구조적 재설계
- YARN의 도입 배경과 핵심 컴포넌트(ResourceManager, NodeManager, ApplicationMaster 등)
- 자원 관리와 작업 실행의 분리 전략
- 다양한 분산 애플리케이션 지원을 위한 유연한 플랫폼 전환
- 1.0 → 2.0으로의 전환이 가져온 변화
- 단점 해소를 위한 설계적 개선
- 확장성, 고가용성, 유연성 확보
- MapReduce 외 Spark, Tez 등 다양한 애플리케이션 실행 기반 마련
Hadoop MapReduce 1.0
Distributed Batch-Sequential Architecture
이 아키텍처는 Hadoop의 MapReduce 처리 흐름을 시각적으로 보여주는 구조로, 전체 데이터 처리 과정이 순차적으로 진행되며, 각 단계가 분산된 노드에서 수행된다.

상단 흐름도 설명
- <k1, v1> 형태의 입력 데이터를 map 함수가 받아 <k2, v2> 형태로 변환한다.
- 이후 combiner가 로컬 수준에서 중간 결과를 집계한다 (선택적 단계).
- 정렬 및 셔플링 후, <k2, v2>는 reduce 함수에 의해 <k3, v3> 형태로 최종 출력된다.
하단 다이어그램 설명
- User Program: 사용자가 MapReduce 작업을 제출하면, 마스터 프로세스를 생성한다.
- Master:
- 각 입력 데이터를 논리적 Split으로 나누고,
- map과 reduce 작업을 분산된 worker들에게 할당한다.
- Map Phase:
- 각 worker는 자신이 할당받은 input split을 읽고, Map 작업을 수행한 뒤,
- 중간 결과를 로컬 디스크에 저장한다.
- Intermediate Files:
- Map의 출력은 <k2, v2> 형태의 중간 파일로 저장되며, 이후 Reducer가 이를 원격으로 읽는다.
- Reduce Phase:
- Reducer는 여러 Map worker들로부터 필요한 키 데이터를 remote read 방식으로 가져온다.
- 데이터를 키 기준으로 그룹핑하고, 최종적으로 Reduce 작업을 수행한다.
- Output Files:
- Reduce 작업이 완료되면 결과는 최종 출력 파일(output file)로 저장된다.
이 구조는 대용량 데이터 처리에 적합한 병렬성과 내결함성을 갖춘 아키텍처이며, 전형적인 배치 처리 흐름을 따른다.
Hadoop Master-Slave Architecture
이 아키텍처는 Hadoop이 분산 환경에서 작업을 관리하고 처리하는 방식을 나타낸다. 전체 시스템은 마스터 노드(NameNode)와 여러 개의 슬레이브 노드(DataNode)로 구성되며, 각 레이어는 HDFS와 MapReduce로 나뉜다.

구성 요소
1. NameNode (HDFS Layer)
- Hadoop 파일 시스템(HDFS)의 메타데이터를 관리하는 중앙 노드.
- 파일의 블록 위치 정보와 각 블록이 저장된 DataNode 정보를 추적한다.
2. JobTracker (MapReduce Layer)
- 클러스터 내 자원(Resource)을 관리하고, MapReduce 작업 실행을 모니터링한다.
- 사용자가 제출한 작업을 여러 Task로 나누어 적절한 TaskTracker에게 분배한다.
3. DataNode (HDFS Layer)
- 실제 데이터 블록을 저장하는 노드.
- NameNode의 지시에 따라 데이터를 읽고 쓰는 작업을 수행한다.
4. TaskTracker (MapReduce Layer)
- JobTracker로부터 전달받은 Task를 실행한다.
- 각 Task의 상태를 JobTracker에 주기적으로 보고하며, 작업이 완료될 때까지 실행을 담당한다.
요약 흐름
- 사용자가 작업을 제출하면 JobTracker가 Task를 분할하여 각 TaskTracker에 배포한다.
- TaskTracker는 작업을 실행하고, 데이터는 HDFS의 DataNode에서 읽어 처리된다.
- NameNode는 데이터 블록의 위치를 관리하고, MapReduce는 해당 위치를 기준으로 작업을 최적화하여 수행한다.
이 구조는 중앙 집중식 제어(Master)와 분산 실행(Slave) 개념을 결합하여, 대규모 데이터를 효율적으로 처리할 수 있도록 설계된 분산 처리 아키텍처이다.
정리
하둡은 병렬 처리와 장애 복구를 위해 다음의 아키텍처를 채택함:
- Master-Slave 구조
- Master: NameNode, ResourceManager, JobTracker
- Slave: DataNode, NodeManager, TaskTracker
- 분산 저장 + 병렬 처리
- HDFS + MapReduce (SPMD 모델)
- 데이터는 블록 단위로 분산 저장
- 연산도 데이터와 가까운 곳에서 수행
- 내결함성(Fault Tolerance)
- 데이터 3중 복제
- Passive Redundant Standby NameNode
Job Tracker
Job Tracker는 Hadoop의 마스터 노드로, 보통 NameNode와 함께 실행되며 전체 MapReduce 작업을 관리한다.
주요 역할
- 사용자의 작업(job)을 수신하고,
- 얼마나 많은 Mapper 작업이 필요한지 결정하며 (예: 입력 블록 수에 따라),
- 각 Mapper를 어느 노드에서 실행할지 결정한다. → 이를 데이터 지역성(locality) 개념이라 하며, 가능한 한 데이터가 존재하는 노드에서 작업을 실행함으로써 네트워크 전송을 줄인다.
예시 설명
- 특정 입력 파일이 5개의 블록으로 나뉘어 있다면, 5개의 Mapper 작업이 생성된다.
- 예를 들어 블록 1을 읽는 작업은, 해당 블록이 저장된 Node 1 또는 Node 3에서 실행하는 것이 이상적이다.
- → 데이터가 위치한 곳에서 직접 처리하도록 유도해 효율을 높인다.

이러한 방식으로 Job Tracker는 작업 수, 위치, 실행 흐름을 조율하며, 전체 클러스터 자원의 활용을 최적화한다.
Task Tracker
Task Tracker는 Hadoop에서 각 DataNode에 배치되는 슬레이브 노드 역할의 컴포넌트로, 실제로 작업을 수행하는 주체이다.

주요 역할
- Job Tracker로부터 작업을 전달받아 실행한다.
- 각 작업(map 또는 reduce)이 완료될 때까지 지속적으로 실행한다.
- 작업 진행 상황을 Job Tracker에 주기적으로 보고하여 상태를 모니터링할 수 있도록 한다.
그림 예시 설명
- 하나의 MapReduce 작업은 4개의 Map 작업과 3개의 Reduce 작업으로 구성되어 있다.
- 각 Map 작업은 입력 데이터를 처리한 뒤 Parse-hash를 통해 키 기반으로 정리하고,
- 해당 데이터를 필요한 Reduce 작업으로 네트워크를 통해 분배한다 (Shuffling).
- 모든 작업(Task)은 Task Tracker에서 실행되며, Map과 Reduce가 병렬적으로 분산 실행된다.
이 구조를 통해 Hadoop은 병렬성과 확장성을 확보하며, 수많은 데이터 조각들을 효과적으로 처리할 수 있다.
Hadoop MapReduce Middleware Framework
이 프레임워크는 MapReduce 작업이 실제로 어떻게 내부적으로 처리되는지를 MAP → SORT → SHUFFLE → MERGE → REDUCE의 다섯 단계로 나누어 설명한다. 각 단계는 병렬적으로 처리되며, SPMD(Single Program Multiple Data) 방식의 병렬 컴퓨팅 구조를 따른다.

1. MAP 단계
- 입력 데이터를 읽어 사용자가 정의한 map() 함수에 전달하고, <key, value> 쌍으로 변환한다.
- 생성된 중간 키-값 쌍은 메모리 버퍼에 저장된다.
2. SORT 단계
- 버퍼에 저장된 중간 데이터는 spill 조건(버퍼 임계치 도달) 시 디스크에 쓰여지고, 로컬 디스크에 임시 파일 형태로 저장된다.
- 여러 spill 파일은 merge 정렬을 통해 병합되며, 이때 Combiner가 사용될 수 있다.
3. SHUFFLE 단계
- Reducer는 각 Mapper의 결과 파일을 원격으로 복사(fetch)하여 받아온다.
- 키별로 정렬된 데이터가 reducer 버퍼에 저장된다.
- 병렬적으로 여러 쓰레드가 fetch, decompress, buffer에 저장하는 역할을 수행한다.
4. MERGE 단계
- 받아온 shuffle 데이터는 다시 여러 번 정렬 및 병합 과정을 거치며, 하나의 입력 스트림으로 정리된다.
- 최종적으로 Reducer가 사용할 수 있도록 정렬된 순서대로 구성된다.
5. REDUCE 단계
- 사용자가 정의한 reduce() 함수가 정렬된 데이터 스트림을 받아 연산을 수행한다.
- 최종 출력은 출력 디렉토리에 저장된다.
이 프레임워크는 MapReduce의 각 단계를 명확하게 분리해주며, 입출력 흐름, 버퍼 관리, 멀티스레드 fetch 및 merge 구조까지 포함된 내부 실행 구조를 잘 보여준다. 특히, 대용량 데이터 처리에서의 데이터 이동 비용 최소화, 정렬 최적화, 에러 회복 가능성 등을 고려한 구조로 설계되어 있다.
네트워크 구조와 데이터 이동
- 각 랙(Rack)은 자체 Top of Rack (ToR) 스위치를 가짐
- 여러 랙을 묶는 Aggregation Switch와 Core Router가 있음
데이터 이동 경로 예시
- 같은 노드에 저장된 데이터 → 네트워크 이동 없음
- 같은 랙의 다른 노드 데이터 → ToR 스위치만 통과
- 다른 랙의 노드 데이터 → ToR → Aggregation → ToR → 노드

네트워크 단계가 늘어날수록 지연(latency) 과 병목(bottleneck) 가능성 증가
Shuffle and Sort in MapReduce
MapReduce에서 Shuffle과 Sort 단계는 Mapper와 Reducer 사이의 연결 과정이며, 전체 시스템 성능에 큰 영향을 미치는 핵심 과정이다. 이 그림은 Map 단계에서 출력된 데이터가 어떻게 정렬되고 전송되며, 최종적으로 Reduce 단계에 전달되는지를 설명한다.

1. Map Task 내부 처리
Input Split
- 입력 데이터는 Split 단위로 나뉘어 각 Mapper에게 전달된다.
Buffer in Memory
- Mapper는 처리 결과를 메모리 상의 순환 버퍼(circular buffer)에 저장한다.
- 이 버퍼는 기본적으로 100MB 크기이며, 버퍼의 80% (기본값)가 차면 백그라운드 스레드가 자동으로 데이터를 디스크에 spill(기록)한다.
Partition, Sort, Spill to Disk
- 버퍼에 쌓인 데이터는 키 기준으로 정렬(in-memory sort)되며,
- 지정된 파티션 수에 따라 나뉘고, 필요시 Combiner를 적용한 뒤 디스크에 spill된다.
- 이 디스크 파일들을 merge on disk 단계에서 하나로 병합한다.
2. Copy Phase (Shuffle 단계)
Fetch
- Reduce Task는 모든 Mapper의 출력이 준비되는 즉시 해당 데이터를 원격으로 복사(fetch)해온다.
- 이 동작은 Mapper가 끝나는 즉시 시작된다.
Data 위치
- 이때 가져오는 데이터는 메모리에 있거나 디스크에 있는 경우 모두 존재할 수 있다.
3. Sort Phase (Merge Phase)
Merge
- Reduce Task는 복사해온 데이터를 정렬된 상태로 병합하는 동시에 정렬한 .
- 이 과정에서 메모리 상의 데이터와 디스크상의 데이터를 섞어가며 Merge Sort 알고리즘으로 병합하여 최종적으로 정렬된 스트림 생성최종 입력 스트림을 만든다.
4. Reduce Phase
Reduce
- reduce() 함수는 병합된 입력 데이터를 받아 키별로 그룹화된 값들을 처리하고 최종 결과를 생성한다.
- 결과는 출력 파일로 저장된다.
핵심 요약
- Buffer → Spill → Sort → Shuffle → Merge → Reduce의 일련의 과정으로 구성된다.
- 이 중 Shuffle과 Merge가 병목의 주요 원인이 되므로, 성능 최적화가 필요하다.
- Combiner는 Spill 또는 Merge 시점에 중간 데이터의 양을 줄이는 역할을 한다.
Hadoop MapReduce 1.0 실행 단계
Hadoop MapReduce V1에서는 하나의 작업(Job)이 다음과 같은 단계로 실행된다:
1. Job Submission
- 클라이언트가 MapReduce 작업을 제출한다.
- 입력 파일, 맵 및 리듀스 클래스, 출력 경로 등 Job 설정 정보가 포함된다.
2. Job Initialization
- JobTracker가 클라이언트로부터 Job 정보를 받고, 입력 데이터를 InputSplit 단위로 나눈다.
- Mapper 수와 Reducer 수를 설정하고, 작업을 추적할 메타데이터를 초기화한다.
3. Task Assignment
- 각 InputSplit에 대해 Mapper 작업이 생성되고, TaskTracker 노드에 분배된다.
- Reducer 작업도 필요한 수만큼 생성된다.
4. Task Execution (Streaming and Pipes)
- TaskTracker는 자신에게 할당된 Mapper 또는 Reducer 작업을 실행한다.
- 작업은 로컬에 저장된 데이터를 기반으로 수행되며, 파이프 또는 스트리밍 방식으로 외부 프로그램과 연동될 수도 있다.
5. Progress and Status Updates
- 각 TaskTracker는 자신이 실행 중인 작업의 상태를 JobTracker에 주기적으로 보고한다.
- JobTracker는 전체 작업 진행 상황을 모니터링하고 필요시 실패한 작업을 재시도한다.
6. Job Completion
- 모든 Mapper 및 Reducer 작업이 성공적으로 완료되면, JobTracker는 클라이언트에 작업 완료를 알린다.
- 결과는 지정된 출력 디렉토리에 저장된다.
MapReduce 1.0의 구성요소
1. Client
- 사용자 또는 애플리케이션이 Job을 제출하는 주체.
- 입력 경로, 출력 경로, Mapper/Reducer 클래스 등을 설정한 후 JobTracker에 전송한다.
2. JobTracker
- MapReduce 시스템의 중앙 제어 역할을 수행하는 마스터 노드.
- 작업 초기화, 태스크 할당, 실패 감지 및 재시도 등을 관리한다.
- Java 애플리케이션이며, 주요 클래스는 JobTracker.
3. TaskTrackers
- 각 노드에서 실행되는 슬레이브 프로세스로, JobTracker로부터 할당된 태스크를 실제로 수행한다.
- Mapper 또는 Reducer 작업을 실행하고, 상태를 JobTracker에 보고한다.
- Java 애플리케이션이며, 주요 클래스는 TaskTracker.
4. Distributed Filesystem (예: HDFS)
- 모든 입력과 출력 데이터는 분산 파일 시스템(HDFS)에 저장된다.
- JobTracker와 TaskTracker는 HDFS로부터 데이터를 읽고 쓰는 방식으로 작업을 수행한다.
이 구조는 중앙 집중식 제어(JobTracker) + 분산 실행(TaskTracker) 기반으로, MapReduce 작업을 병렬로 처리하고, 장애 복구와 진행 상태 모니터링까지 포함하는 체계적인 아키텍처다.
MapReduce 1.0 상세 실행 흐름

Step 1: 사용자가 Job을 실행 (run job)
- 사용자는 MapReduce program을 실행하고, 내부적으로 JobClient가 생성된다.
- 이 클라이언트는 Job을 실행하기 위한 초기 준비를 시작한다.
Step 2: 새 Job ID 요청 (get new job ID)
- JobClient는 JobTracker에게 새로운 Job ID를 요청한다.
- JobTracker는 이 ID를 생성해 반환한다.
Step 3: 리소스 준비 및 업로드 (copy job resources)
- JobClient는 다음 리소스들을 공유 파일 시스템(HDFS)에 업로드한다:
- Job JAR 파일
- 설정 파일 (Configuration)
- 입력 데이터를 논리적으로 분할한 InputSplits 정보
- 이 리소스들은 Job ID 이름의 디렉토리에 저장된다.
Step 4: Job 제출 (submit job)
- JobClient는 JobTracker에게 Job을 공식적으로 제출한다.
- 이때 HDFS 경로에 저장된 Job 리소스들의 위치가 함께 전달된다.
Step 5: Job 초기화 (initialize job)
- JobTracker는 이 Job의 상태와 진행 상황을 추적하기 위한 Job 인스턴스를 생성한다.
- 이는 내부적으로 작업의 메타데이터와 상태를 저장하는 구조이다.
Step 6: Task 리스트 생성 (retrieve input splits)
- JobTracker는 JobClient가 생성한 InputSplit 목록을 받아온다.
- 이 정보를 바탕으로 Mapper와 Reducer 태스크 수를 결정하고, Task 목록을 만든다.
Step 7: Heartbeat로 상태 감시 및 태스크 할당
- 각 TaskTracker는 주기적으로 JobTracker에게 Heartbeat 신호를 보낸다.
- 이 Heartbeat는 단순히 "살아 있다"는 신호 외에도, 메시지를 포함할 수 있다.
- 예: "나는 새 작업을 받을 준비가 됐음"
- JobTracker는 이 정보를 보고 TaskTracker에게 Mapper 또는 Reducer 작업을 할당한다.
Step 8: 리소스 다운로드 (retrieve job resources)
- TaskTracker는 작업 수행에 필요한 리소스를 HDFS로부터 받아온다:
- Job JAR 파일
- 설정 파일
- 필요시 Distributed Cache에 저장된 추가 파일
Step 9: 자식 JVM 실행 (launch)
- 슬레이브 노드는 각각에 대해 별도 Child JVM을 fork해서 각 Task (Mapper/Reducer)를 독립적으로 실행합니다.
- 각 Task는 Child JVM이라는 별도 프로세스에서 실행된다.
- 이는 Task 간의 격리를 위해 필수적인 구조이다.
Step 10: 작업 수행 (run)
- Child JVM 내에서 Mapper 또는 Reducer 작업이 실행된다.
- 결과는 출력 디렉토리에 저장되며, 상태는 TaskTracker를 통해 JobTracker에 전달된다.
요약 구조
- JobClient는 사용자의 Job을 준비하고 JobTracker에게 제출함
- JobTracker는 작업을 초기화하고, Task들을 적절히 나누어 각 TaskTracker에게 할당
- TaskTracker는 각 태스크를 받아 Child JVM에서 실행하며,
- 전체 진행 상황은 Heartbeat를 통해 JobTracker에 실시간으로 전달됨
이 구조는 완전한 마스터-슬레이브 방식으로, 모든 중앙 제어는 JobTracker가 수행하며, TaskTracker는 실제 작업을 수행하는 실행 노드 역할을 한다.
Streaming and Pipes in Hadoop MapReduce
공통 개념
- Streaming과 Pipes는 Java 외의 언어(C/C++, Python 등)로 작성된 사용자 정의 프로그램(실행 파일)을 MapReduce 작업에서 실행할 수 있도록 해주는 인터페이스이다.
- 둘 다 특별한 방식으로 MapTask 또는 ReduceTask를 실행하며, 외부 프로그램과 데이터를 주고받는 통신을 담당한다.
1. Streaming
- Streaming은 표준 입력/출력(stdin/stdout)을 통해 통신하는 방식이다.
- 입력 키-값 쌍은 텍스트 형태로 사용자 프로그램의 표준 입력(stdin)으로 전달된다.
- 출력 결과는 표준 출력(stdout)으로 받아 다시 Hadoop이 처리한다.
- 외부 프로그램은 Python, Shell Script, Perl 등 거의 모든 실행 파일이 가능하다.
실행 구조

- TaskTracker → Child JVM → MapTask/ReduceTask → Streaming process
- Hadoop이 입력을 스트리밍 프로세스에 전달하고, 출력도 받아서 후속 처리한다.
2. Pipes
- Pipes는 C++용 MapReduce API를 위한 인터페이스이다.
- Hadoop의 Task는 C++로 작성된 사용자 클래스(Map 또는 Reduce 클래스)를 실행하기 위해 소켓 통신을 사용한다.
- 내부적으로 C++ wrapper library가 사용자 로직을 호출하고, Hadoop과 데이터를 주고받는다.
실행 구조
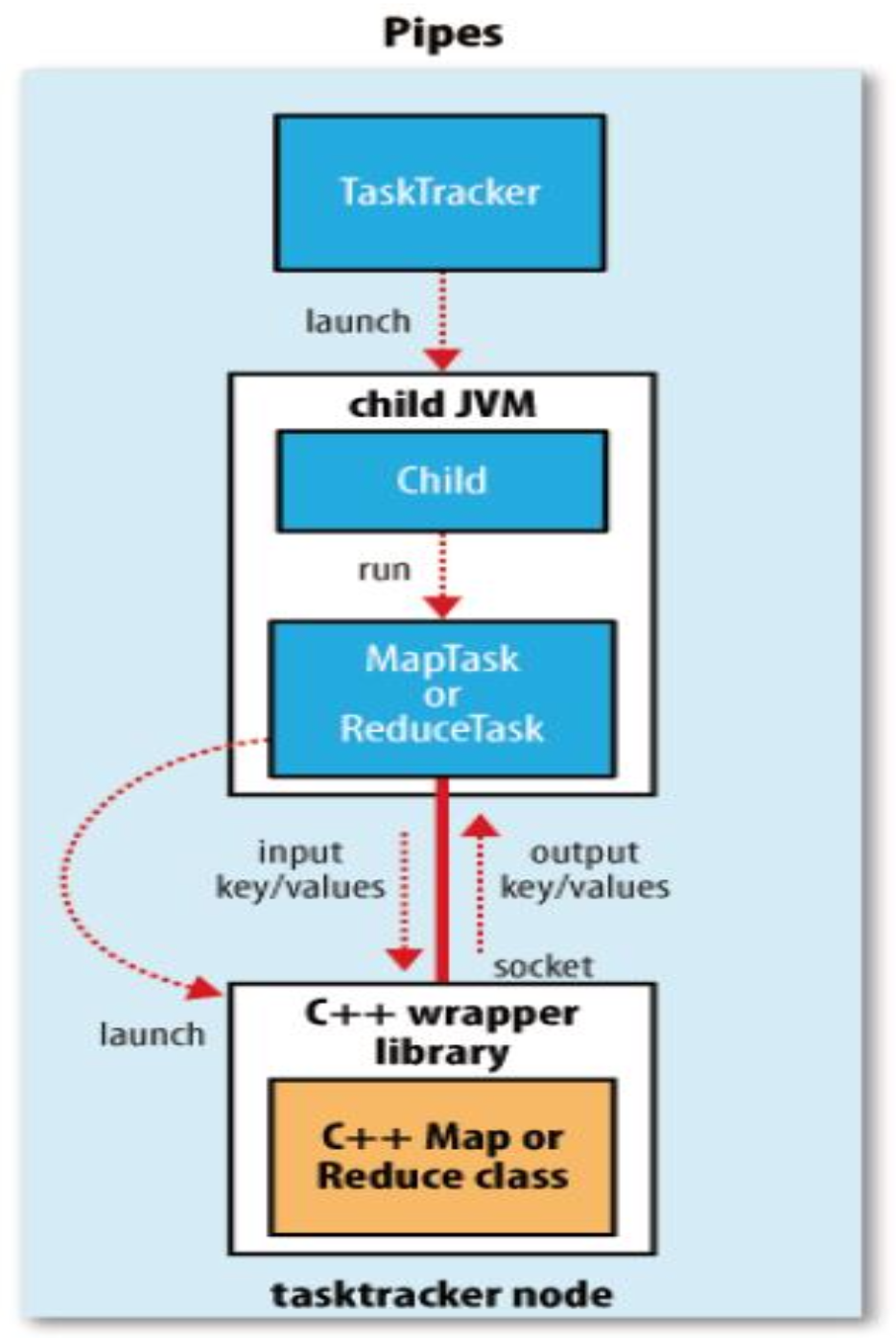
- TaskTracker → Child JVM → MapTask/ReduceTask → C++ wrapper → C++ 사용자 클래스
- 소켓을 통해 키-값 데이터를 입출력하며 동작한다.
🔁 Streaming vs Pipes 비교
| 항목 | Streaming | Pipes |
| 지원 언어 | 거의 모든 언어 (Python, Shell, Perl 등) | C++ 전용 |
| 통신 방식 | 표준 입력/출력 (stdin / stdout) | 소켓 통신 |
| 입출력 포맷 | 텍스트 기반 | 바이너리 기반 |
| 성능 | 상대적으로 느림 (텍스트 변환 오버헤드) | 빠름 (바이너리 직접 전송) |
| Hadoop과의 통합 | 느슨한 결합 (외부 실행 파일) | 깊은 통합 (Wrapper Library 사용) |
| Mapper/Reducer 작성 방식 | 독립적인 실행 파일로 작성 | C++ 클래스 형태로 작성 (Java MapReduce 유사 API) |
| Wrapper 제공 | ❌ 없음 (직접 처리) | ✅ C++ Wrapper Library 자동 제공 |
| 적합한 사용 사례 | 간단한 스크립트 실행, 빠른 프로토타입 | 고성능 C++ 알고리즘 통합, 복잡한 MapReduce 작업 |
💡 결론:
Streaming: 간단하고 언어 제약이 없어 빠른 실험에 유리함
Pipes: 고성능 C++ 환경과 깊은 통합이 필요할 때 적합
Progress and Status Updates in MapReduce
MapReduce는 Job 및 각 Task의 실행 상태와 진행 상황을 지속적으로 모니터링하고 업데이트한다.
1. 상태(Status)
- 작업의 상태 (예: 실행 중, 성공, 실패)
- Map과 Reduce의 진행률
- 진행률은 작업이 얼마나 완료되었는지를 나타내는 비율이다.
- Job Counter의 값
- Job 실행 중의 다양한 통계값 (예: 실행된 Mapper 수 등)
- 사용자 정의 상태 메시지
- 개발자가 직접 설정할 수 있는 상태 설명
2. MapReduce Job Counters
- Job counter는 개별 태스크 실행 중이 아닌, Job 전체 수준의 통계를 측정한다.
- 예시: TOTAL_LAUNCHED_MAPS → 실행된 Mapper 태스크 수를 누적 집계 (실패한 태스크도 포함)
- 이러한 카운터는 JobTracker가 전체 작업의 흐름을 파악하고 디버깅하는 데 유용하다.
이 구조를 통해 Hadoop은 다양한 언어로 작성된 외부 프로그램과도 유연하게 연동할 수 있으며, Job의 상태와 진행 상황을 정확히 추적하여 클러스터 자원을 효과적으로 관리할 수 있다.
Hadoop MapReduce 1.0 의 단점과 해결방안
현실 세계에서는 사용자 코드 오류, 시스템 크래시, 노드 장애가 자주 발생한다. Hadoop MapReduce는 이러한 실패 상황을 견디고 작업을 끝까지 수행할 수 있는 내결함성(Fault Tolerance)을 제공한다.
1. Task Failure
- 주로 사용자 정의 Mapper 또는 Reducer 코드에서 런타임 예외(Runtime Exception)가 발생할 때 발생한다.
- 실패 과정:
- Child JVM이 오류 발생 후 종료되며, 이를 TaskTracker에 보고한다.
- TaskTracker는 Heartbeat 메시지를 통해 JobTracker에게 실패 사실을 알림.
- JobTracker는 해당 Task를 다른 TaskTracker에 재할당한다.
- 단, 이전에 실패했던 TaskTracker에는 재할당하지 않음.
- Task가 4회 이상 실패하면 더 이상 재시도하지 않음.
- 그 외에도 Task가 중단되는 경우:
- Speculative Execution 중 중복 태스크가 성공하면 다른 태스크는 종료됨.
- 일부 작업은 일부 태스크 실패에도 불구하고 결과를 유지하고 싶어함.
2. TaskTracker Failure
- TaskTracker가 크래시되거나 지나치게 느리게 동작할 경우, JobTracker는 일정 시간 동안 Heartbeat를 받지 못하게 된다.
- 기본적으로 10분 이상 Heartbeat가 없으면 해당 TaskTracker는 제외(blacklist)됨.
- 설정: mapred.task.tracker.expiry.interval
- 지속적으로 실패하는 TaskTracker도 blacklist 대상이 될 수 있다.
3. JobTracker Failure
- 가장 치명적인 실패 유형.
- Hadoop V1에서는 JobTracker 장애에 대한 복구 메커니즘이 없음.
- 이후 버전(YARN 등)에서는 JobTracker 분산화 또는 고가용성(HA) 아키텍처가 도입될 예정.
Job Scheduling in Hadoop
기본 스케줄링 방식
- 초기 Hadoop은 매우 단순한 FIFO(First-In-First-Out) 방식 사용.
- 제출 순서에 따라 Job이 순차적으로 실행됨.
우선순위 설정
- Job의 우선순위를 설정할 수 있도록 개선됨:
- 설정: mapred.job.priority
- 프로그래밍 인터페이스: setJobPriority() (JobClient)
Fair Scheduler
- 다중 사용자 환경을 고려해 자원 분배를 공정하게 처리하기 위한 스케줄러.
- 사용자별로 Job이 균등하게 실행되도록 설계됨.
Task Execution 최적화 전략
1. Speculative Execution
- 느리게 실행되는 태스크를 감지해 백업 태스크를 병렬로 실행.
- 가장 먼저 끝나는 태스크의 결과만 사용.
- 병목을 완화하고 전체 Job 완료 시간을 단축시킴.
2. Task JVM Reuse
- 매번 새로운 JVM을 실행하는 오버헤드를 줄이기 위해, 하나의 JVM을 재사용 가능.
- 단기 작업이나 CPU 바운드 작업에 적합.
3. Skipping Bad Records
- 입력 레코드 중 문제가 있는 경우:
- 예외를 발생시켜 작업 중단, 또는
- 문제가 있는 레코드는 건너뛰고 실행 계속 가능.
- 설정에 따라 유연한 실패 처리 구현 가능.
하지만 이러한 방식은 구조적으로 JobTracker의 병목, 확장성 부족, 단일 장애점 문제 등을 근본적으로 해결하지 못했다.
이를 해결하기 위해 Hadoop 2에서는 YARN이라는 새로운 자원 관리 체계를 도입했다.
Hadoop MapReduce 2.0 (YARN 기반 구조)

개요
- Hadoop MapReduce V2는 YARN (Yet Another Resource Negotiator) 위에서 실행된다.
- JobTracker/TaskTracker 방식이었던 V1 구조에서 벗어나, 자원 관리와 작업 실행을 분리함으로써 확장성과 안정성을 크게 향상시켰다.
핵심 구성 요소 (5가지 독립적 엔티티)

1. Client
- 사용자가 MapReduce 작업을 제출한다.
- 설정 파일, 입력 경로, Mapper/Reducer 클래스 등을 포함.
2. Resource Manager (RM)
- YARN의 중앙 자원 관리자 역할.
- 클러스터 전체 자원을 추적하며, ApplicationMaster에게 컨테이너 실행 권한을 부여함.
- 모든 노드의 상태, 자원 할당 요청을 관리함.
3. Node Manager (NM)
- 각 워커 노드에 존재하는 YARN 에이전트.
- 자원 사용량을 모니터링하고, RM의 지시에 따라 컨테이너(Container)를 생성해 작업을 실행함.
- 각 노드는 하나의 NodeManager가 담당.
4. MapReduce Application Master (MRAppMaster)
- MapReduce 작업을 실제로 조율하는 엔티티.
- JobTracker의 역할이 분산됨 → 각 MapReduce Job은 독립된 MRAppMaster 인스턴스를 갖는다.
- 작업 분할, 태스크 모니터링, 장애 복구 등을 담당.
5. YARN Child / Container
- 실제 Mapper 또는 Reducer 코드가 실행되는 단위.
- NodeManager가 관리하는 컨테이너 안에서 실행됨.
작동 흐름 요약
- Client가 Job 제출
- ResourceManager가 자원 할당 후 MRAppMaster 시작
- MRAppMaster가 Job 논리 분할, 컨테이너 요청
- NodeManager가 Container를 생성하고 YARN Child에 Map/Reduce 실행
- Job 종료 시 결과 저장 및 상태 보고
구조 정리
Hadoop MapReduce V2는 YARN 위에서 실행됨으로써,
- 자원 관리(Resource Management)
- 작업 스케줄링(Task Scheduling)
- 작업 실행(Execution)을 완전히 모듈화함. 이를 통해 더 안정적이고 유연한 분산 처리 시스템을 제공한다.
MapReduce 2.0 Job 실행 과정 (with YARN)

Hadoop MapReduce V2는 YARN 아키텍처 기반으로 작동하며, Job이 실행되는 전체 과정은 다음과 같다:
Step-by-Step 실행 흐름
Step 1. 사용자가 Job 실행 요청 (run job)
- 사용자가 Client에서 MapReduce Job을 실행한다.
- 내부적으로 Job 객체가 생성된다.
Step 2. 애플리케이션 ID 생성 (get new application ID)
- Client는 YARN의 ResourceManager에게 새로운 Application ID를 요청한다.
- 이 ID는 V1의 Job ID와 같은 역할.
Step 3. 리소스 준비 (copy job resources)
- Client는 다음 리소스를 HDFS에 업로드한다:
- Job JAR 파일
- 설정 정보 (Configuration)
- 입력 분할 정보 (Input Splits)
Step 4. Job 제출 (submit application)
- ResourceManager에게 Application 제출 (JAR 위치, 설정, 실행 정보 포함)
Step 5. ApplicationMaster 컨테이너 생성 및 실행
- ResourceManager는 YARN Scheduler를 통해 ApplicationMaster 실행을 위한 Container를 할당한다.
- 5a: 컨테이너 할당
- 5b: 해당 NodeManager에서 MRAppMaster 실행
Step 6. MRAppMaster 초기화
- MRAppMaster는 Job을 초기화하며, 작업 상태를 추적할 메타데이터를 생성한다.
Step 7. 입력 정보 읽기
- MRAppMaster는 HDFS에서 InputSplit 정보를 읽어온다.
Step 8. Mapper/Reducer 실행용 리소스 요청
- MRAppMaster는 각각의 Mapper, Reducer 실행을 위해 ResourceManager에게 Container 자원 요청을 보낸다.
Step 9. 컨테이너 할당 및 실행
- ResourceManager는 적절한 NodeManager에게 Container 실행 지시
- 9a: 컨테이너 시작 요청
- 9b: NodeManager에서 YarnChild JVM 실행
Step 10~11. Task 실행
- 컨테이너 안에서 MapTask 또는 ReduceTask가 실행된다.
- 작업 결과는 HDFS에 저장되며, 상태는 MRAppMaster에게 보고된다.
1.0 과 2.0 구조 비교
| 항목 | MapReduce V1 (JobTracker 기반) | MapReduce V2 (YARN 기반) |
| 자원 관리자 | JobTracker (중앙 집중식) | ResourceManager (YARN) |
| 작업 스케줄러 | JobTracker 단일 노드에서 수행 | MRAppMaster가 개별 Job을 관리 |
| 실행 담당자 | TaskTracker | NodeManager + YarnChild |
| 장애 복구 | JobTracker 장애 시 전체 실패 | MRAppMaster 단위로 고립된 복구 가능 |
| 확장성 | 수천 노드 한계, 병목 존재 | 수만 노드 이상 확장 가능 |
| 구조적 유연성 | MapReduce 전용 | 다양한 앱(Spark, Tez 등) 실행 가능 |
| JVM 실행 | 각 Task 마다 새 JVM 실행 | Container 내부에서 실행, 더 효율적 |
요약 포인트
- MRAppMaster는 V1의 JobTracker 역할을 각 Job 단위로 분산하여 맡는다.
- 자원 할당과 작업 실행은 완전히 분리된 컴포넌트(ResourceManager vs NodeManager) 가 수행.
- YARN 기반 구조는 확장성과 고가용성, 유연성 면에서 V1보다 훨씬 강력하다.
'Server-side 개발 & 트러블 슈팅 > 🐘 Hadoop (하둡)' 카테고리의 다른 글
| [Hadoop] 하둡 설치 및 MapReduce 기본 예제 실습 (Standalone 모드) (0) | 2025.04.14 |
|---|---|
| [Hadoop] 하둡 실습을 위한 VM 환경 세팅 (virtual box, VMware Fusion) (0) | 2025.04.14 |
| [Hadoop] 하둡 MapReduce 동작 원리 (0) | 2025.04.09 |
| HDFS(하둡 분산 파일 시스템) 구조 및 작동 방식 (0) | 2025.04.03 |
| 하둡(Hadoop)의 아키텍처, 병렬처리, 장애처리 전략 (0) | 2025.04.02 |




댓글